 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerification Mirage: Mapping the Reliability Boundary of Self-Verification in Medical VQA
May 11, 2026Self-verification, re-invoking the same vision language model (VLM) in a fresh context to check its own generated answer, is increasingly used as a default safety layer for medical visual question answering (VQA). We argue that this practice is fundamentally unreliable. We introduce [METHOD NAME], a diagnostic framework for mapping the reliability boundary of medical VLM self-verification by decomposing verifier behavior into discrimination capability and agreement bias. Because the verifier and answer generator are capacity-coupled, the verifier can overly agree with the generator, creating a verification mirage: a regime with both high verifier error and high agreement bias, driven by false acceptance of incorrect answers. Evaluating six open-weight VLMs across five medical VQA datasets and seven medical tasks, we find that this boundary is strongly task-conditioned. Knowledge-intensive clinical tasks fall deepest into the mirage, simpler tasks are more resistant, and perceptual tasks lie in between. Verification also fails to provide an independent safety signal: logistic mixed-effects analysis shows that verifier error and agreement bias become more likely when the generator is wrong, while saliency analyses show that verifiers under-attend to image evidence relative to generators, a phenomenon we call the lazy verifier. Cross-verification reduces but does not eliminate the mirage. Moreover, when verification is reused in multi-turn actor-verifier loops, most initially wrong answers become locked in by false verification. Since our experiments use clean benchmarks, the observed reliability boundary likely underestimates failures in real clinical deployment.
Why Adam Can Beat SGD: Second-Moment Normalization Yields Sharper Tails
Mar 03, 2026Despite Adam demonstrating faster empirical convergence than SGD in many applications, much of the existing theory yields guarantees essentially comparable to those of SGD, leaving the empirical performance gap insufficiently explained. In this paper, we uncover a key second-moment normalization in Adam and develop a stopping-time/martingale analysis that provably distinguishes Adam from SGD under the classical bounded variance model (a second moment assumption). In particular, we establish the first theoretical separation between the high-probability convergence behaviors of the two methods: Adam achieves a $δ^{-1/2}$ dependence on the confidence parameter $δ$, whereas corresponding high-probability guarantee for SGD necessarily incurs at least a $δ^{-1}$ dependence.
DUCX: Decomposing Unfairness in Tool-Using Chest X-ray Agents
Feb 28, 2026Tool-using medical agents can improve chest X-ray question answering by orchestrating specialized vision and language modules, but this added pipeline complexity also creates new pathways for demographic bias beyond standalone models. We present ours (Decomposing Unfairness in Chest X-ray agents), a systematic audit of chest X-ray agents instantiated with MedRAX. To localize where disparities arise, we introduce a stage-wise fairness decomposition that separates end-to-end bias from three agent-specific sources: tool exposure bias (utility gaps conditioned on tool presence), tool transition bias (subgroup differences in tool-routing patterns), and model reasoning bias (subgroup differences in synthesis behaviors). Extensive experiments on tool-used based agentic frameworks across five driver backbones reveal that (i) demographic gaps persist in end-to-end performance, with equalized odds up to 20.79%, and the lowest fairness-utility tradeoff down to 28.65%, and (ii) intermediate behaviors, tool usage, transition patterns, and reasoning traces exhibit distinct subgroup disparities that are not predictable from end-to-end evaluation alone (e.g., conditioned on segmentation-tool availability, the subgroup utility gap reaches as high as 50%). Our findings underscore the need for process-level fairness auditing and debiasing to ensure the equitable deployment of clinical agentic systems. Code is available here: https://anonymous.4open.science/r/DUCK-E5FE/README.md
Bridging Online and Offline RL: Contextual Bandit Learning for Multi-Turn Code Generation
Feb 03, 2026Recently, there have been significant research interests in training large language models (LLMs) with reinforcement learning (RL) on real-world tasks, such as multi-turn code generation. While online RL tends to perform better than offline RL, its higher training cost and instability hinders wide adoption. In this paper, we build on the observation that multi-turn code generation can be formulated as a one-step recoverable Markov decision process and propose contextual bandit learning with offline trajectories (Cobalt), a new method that combines the benefits of online and offline RL. Cobalt first collects code generation trajectories using a reference LLM and divides them into partial trajectories as contextual prompts. Then, during online bandit learning, the LLM is trained to complete each partial trajectory prompt through single-step code generation. Cobalt outperforms two multi-turn online RL baselines based on GRPO and VeRPO, and substantially improves R1-Distill 8B and Qwen3 8B by up to 9.0 and 6.2 absolute Pass@1 scores on LiveCodeBench. Also, we analyze LLMs' in-context reward hacking behaviors and augment Cobalt training with perturbed trajectories to mitigate this issue. Overall, our results demonstrate Cobalt as a promising solution for iterative decision-making tasks like multi-turn code generation. Our code and data are available at https://github.com/OSU-NLP-Group/cobalt.
RVCBench: Benchmarking the Robustness of Voice Cloning Across Modern Audio Generation Models
Jan 31, 2026Modern voice cloning (VC) can synthesize speech that closely matches a target speaker from only seconds of reference audio, enabling applications such as personalized speech interfaces and dubbing. In practical deployments, modern audio generation models inevitably encounter noisy reference audios, imperfect text prompts, and diverse downstream processing, which can significantly hurt robustness. Despite rapid progress in VC driven by autoregressive codec-token language models and diffusion-based models, robustness under realistic deployment shifts remains underexplored. This paper introduces RVCBench, a comprehensive benchmark that evaluates Robustness in VC across the full generation pipeline, including input variation, generation challenges, output post-processing, and adversarial perturbations, covering 10 robustness tasks, 225 speakers, 14,370 utterances, and 11 representative modern VC models. Our evaluation uncovers substantial robustness gaps in VC: performance can deteriorate sharply under common input shifts and post-processing; long-context and cross-lingual scenarios further expose stability limitations; and both passive noise and proactive perturbation influence generation robustness. Collectively, these findings provide a unified picture of how current VC models fail in practice and introduce a standardized, open-source testbed to support the development of more robust and deployable VC models. We open-source our project at https://github.com/Nanboy-Ronan/RVCBench.
A Closer Look at Personalized Fine-Tuning in Heterogeneous Federated Learning
Nov 16, 2025
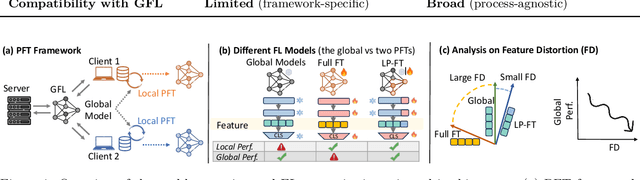
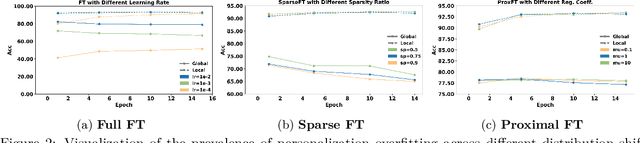
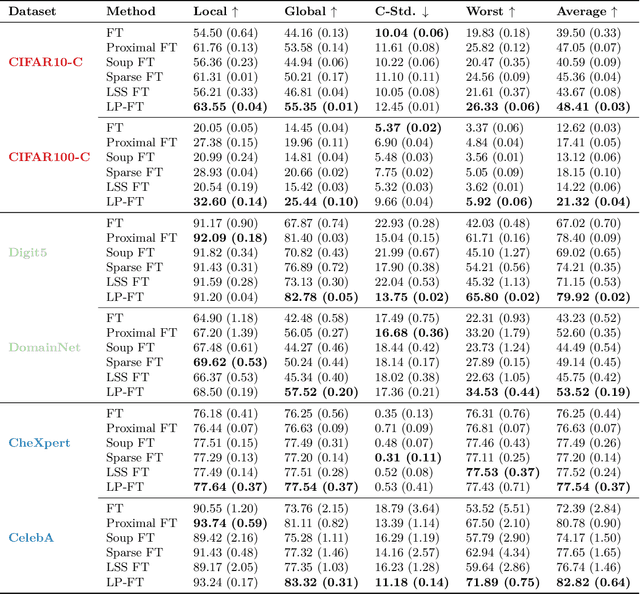
Federated Learning (FL) enables decentralized, privacy-preserving model training but struggles to balance global generalization and local personalization due to non-identical data distributions across clients. Personalized Fine-Tuning (PFT), a popular post-hoc solution, fine-tunes the final global model locally but often overfits to skewed client distributions or fails under domain shifts. We propose adapting Linear Probing followed by full Fine-Tuning (LP-FT), a principled centralized strategy for alleviating feature distortion (Kumar et al., 2022), to the FL setting. Through systematic evaluation across seven datasets and six PFT variants, we demonstrate LP-FT's superiority in balancing personalization and generalization. Our analysis uncovers federated feature distortion, a phenomenon where local fine-tuning destabilizes globally learned features, and theoretically characterizes how LP-FT mitigates this via phased parameter updates. We further establish conditions (e.g., partial feature overlap, covariate-concept shift) under which LP-FT outperforms standard fine-tuning, offering actionable guidelines for deploying robust personalization in FL.
Stochastic Gradient Descent in Non-Convex Problems: Asymptotic Convergence with Relaxed Step-Size via Stopping Time Methods
Apr 17, 2025Stochastic Gradient Descent (SGD) is widely used in machine learning research. Previous convergence analyses of SGD under the vanishing step-size setting typically require Robbins-Monro conditions. However, in practice, a wider variety of step-size schemes are frequently employed, yet existing convergence results remain limited and often rely on strong assumptions. This paper bridges this gap by introducing a novel analytical framework based on a stopping-time method, enabling asymptotic convergence analysis of SGD under more relaxed step-size conditions and weaker assumptions. In the non-convex setting, we prove the almost sure convergence of SGD iterates for step-sizes $ \{ \epsilon_t \}_{t \geq 1} $ satisfying $\sum_{t=1}^{+\infty} \epsilon_t = +\infty$ and $\sum_{t=1}^{+\infty} \epsilon_t^p < +\infty$ for some $p > 2$. Compared with previous studies, our analysis eliminates the global Lipschitz continuity assumption on the loss function and relaxes the boundedness requirements for higher-order moments of stochastic gradients. Building upon the almost sure convergence results, we further establish $L_2$ convergence. These significantly relaxed assumptions make our theoretical results more general, thereby enhancing their applicability in practical scenarios.
Interactive Tumor Progression Modeling via Sketch-Based Image Editing
Mar 10, 2025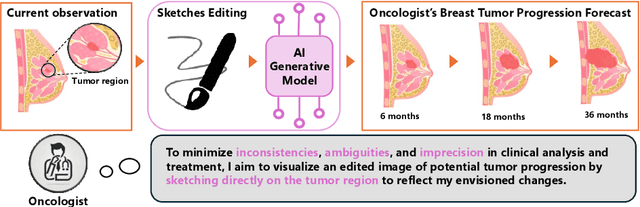
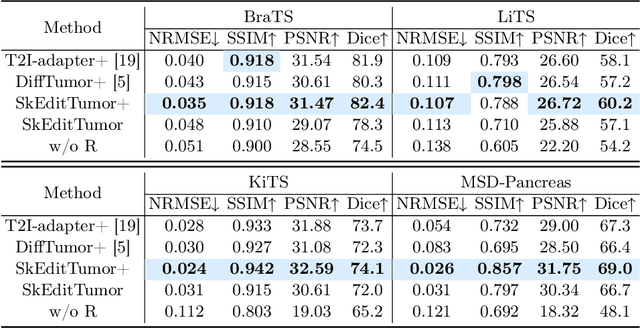
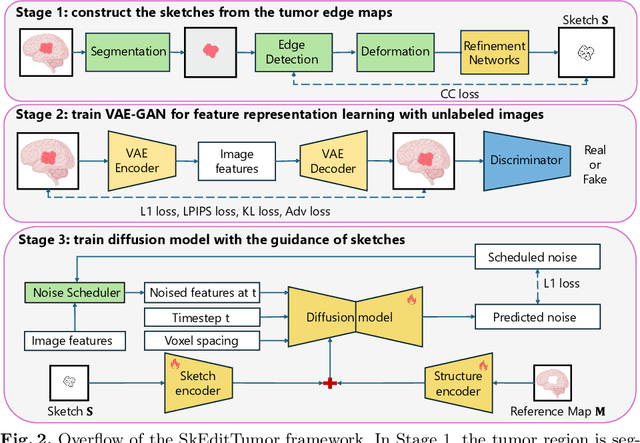
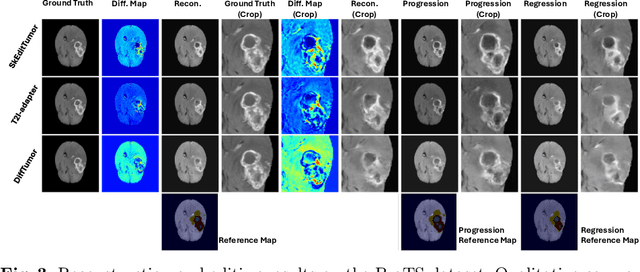
Accurately visualizing and editing tumor progression in medical imaging is crucial for diagnosis, treatment planning, and clinical communication. To address the challenges of subjectivity and limited precision in existing methods, we propose SkEditTumor, a sketch-based diffusion model for controllable tumor progression editing. By leveraging sketches as structural priors, our method enables precise modifications of tumor regions while maintaining structural integrity and visual realism. We evaluate SkEditTumor on four public datasets - BraTS, LiTS, KiTS, and MSD-Pancreas - covering diverse organs and imaging modalities. Experimental results demonstrate that our method outperforms state-of-the-art baselines, achieving superior image fidelity and segmentation accuracy. Our contributions include a novel integration of sketches with diffusion models for medical image editing, fine-grained control over tumor progression visualization, and extensive validation across multiple datasets, setting a new benchmark in the field.
Can Textual Gradient Work in Federated Learning?
Feb 27, 2025Recent studies highlight the promise of LLM-based prompt optimization, especially with TextGrad, which automates differentiation'' via texts and backpropagates textual feedback. This approach facilitates training in various real-world applications that do not support numerical gradient propagation or loss calculation. In this paper, we systematically explore the potential and challenges of incorporating textual gradient into Federated Learning (FL). Our contributions are fourfold. Firstly, we introduce a novel FL paradigm, Federated Textual Gradient (FedTextGrad), that allows clients to upload locally optimized prompts derived from textual gradients, while the server aggregates the received prompts. Unlike traditional FL frameworks, which are designed for numerical aggregation, FedTextGrad is specifically tailored for handling textual data, expanding the applicability of FL to a broader range of problems that lack well-defined numerical loss functions. Secondly, building on this design, we conduct extensive experiments to explore the feasibility of FedTextGrad. Our findings highlight the importance of properly tuning key factors (e.g., local steps) in FL training. Thirdly, we highlight a major challenge in FedTextGrad aggregation: retaining essential information from distributed prompt updates. Last but not least, in response to this issue, we improve the vanilla variant of FedTextGrad by providing actionable guidance to the LLM when summarizing client prompts by leveraging the Uniform Information Density principle. Through this principled study, we enable the adoption of textual gradients in FL for optimizing LLMs, identify important issues, and pinpoint future directions, thereby opening up a new research area that warrants further investigation.
A Comprehensive Framework for Analyzing the Convergence of Adam: Bridging the Gap with SGD
Oct 06, 2024
Adaptive Moment Estimation (Adam) is a cornerstone optimization algorithm in deep learning, widely recognized for its flexibility with adaptive learning rates and efficiency in handling large-scale data. However, despite its practical success, the theoretical understanding of Adam's convergence has been constrained by stringent assumptions, such as almost surely bounded stochastic gradients or uniformly bounded gradients, which are more restrictive than those typically required for analyzing stochastic gradient descent (SGD). In this paper, we introduce a novel and comprehensive framework for analyzing the convergence properties of Adam. This framework offers a versatile approach to establishing Adam's convergence. Specifically, we prove that Adam achieves asymptotic (last iterate sense) convergence in both the almost sure sense and the \(L_1\) sense under the relaxed assumptions typically used for SGD, namely \(L\)-smoothness and the ABC inequality. Meanwhile, under the same assumptions, we show that Adam attains non-asymptotic sample complexity bounds similar to those of SGD.