 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokerSkill: LLMs Can Play Expert-Level Poker without Training or Solvers
May 28, 2026Poker is a landmark challenge for artificial intelligence. The dominant approach relies on equilibrium solvers built on counterfactual regret minimization, requiring millions of core-hours of training. Large Language Models (LLMs) possess extensive poker knowledge but perform far below solver-based agents when asked to play directly. Traditional rule-based poker agents are interpretable and training-free, but their strategic ceiling remains far below equilibrium play. We introduce \textbf{PokerSkill}, a training-free and solver-free framework that bridges this gap by using detailed rule-based poker skills as a structured action-grounding interface for LLMs. A deterministic context engine analyzes the current state and retrieves only the relevant fragments from a layered skill library, which is entirely designed by human poker experts, constraining the LLM's choice to reasonable actions. Against GTOWizard, a state-of-the-art GTO benchmark, GPT-5.5 XHigh with PokerSkill achieves $-57 \pm 21$ mbb/hand, Claude Opus 4.6 achieves $-80 \pm 29$ mbb/hand and Claude Opus 4.7 achieves $-87\pm 64$ mbb/hand, reducing losses by 49--61\% compared to default-prompt baselines and outperforming the strong bot Slumbot. Our key finding is that rule-based skills alone do not constitute a strong strategy, and LLMs alone cannot play well, but their combination yields an agent that requires neither training nor solver access yet competes with systems built on millions of core-hours of computation. To our knowledge, this is the first demonstration of an LLM achieving competitive performance in a complex imperfect-information game without game-specific training or solver queries. Code is available at https://github.com/lbn187/PokerSkill.
The Optimal Token Baseline: Variance Reduction for Long-Horizon LLM-RL
Feb 06, 2026Reinforcement Learning (RL) for Large Language Models (LLMs) often suffers from training collapse in long-horizon tasks due to exploding gradient variance. To mitigate this, a baseline is commonly introduced for advantage computation; however, traditional value models remain difficult to optimize, and standard group-based baselines overlook sequence heterogeneity. Although classic optimal baseline theory can achieve global variance reduction, it neglects token heterogeneity and requires prohibitive gradient-based computation. In this work, we derive the Optimal Token Baseline (OTB) from first principles, proving that gradient updates should be weighted inversely to their cumulative gradient norm. To ensure efficiency, we propose the Logit-Gradient Proxy that approximates the gradient norm using only forward-pass probabilities. Our method achieves training stability and matches the performance of large group sizes ($N=32$) with only $N=4$, reducing token consumption by over 65% across single-turn and tool-integrated reasoning tasks.
Trust Region Masking for Long-Horizon LLM Reinforcement Learning
Dec 28, 2025Policy gradient methods for large language models optimize a surrogate objective computed from samples of a rollout policy $π_{\text{roll}}$. When $π_{\text{roll}} \ne π_θ$, there is approximation error between the surrogate and the true objective. Prior work has shown that this off-policy mismatch is unavoidable in modern LLM-RL due to implementation divergence, mixture-of-experts routing discontinuities, and distributed training staleness. Classical trust region bounds on the resulting error scale as $O(T^2)$ with sequence length $T$, rendering them vacuous for long-horizon tasks. We derive two tighter bounds: a Pinsker-Marginal bound scaling as $O(T^{3/2})$ and a Mixed bound scaling as $O(T)$. Crucially, both bounds depend on $D_{kl}^{tok,max}$ -- the maximum token-level KL divergence across all positions in a sequence. This is inherently a sequence-level quantity: it requires examining the entire trajectory to compute, and therefore cannot be controlled by token-independent methods like PPO clipping. We propose Trust Region Masking (TRM), which excludes entire sequences from gradient computation if any token violates the trust region, providing the first non-vacuous monotonic improvement guarantees for long-horizon LLM-RL.
Taming the Tail: Stable LLM Reinforcement Learning via Dynamic Vocabulary Pruning
Dec 28, 2025Reinforcement learning for large language models (LLMs) faces a fundamental tension: high-throughput inference engines and numerically-precise training systems produce different probability distributions from the same parameters, creating a training-inference mismatch. We prove this mismatch has an asymmetric effect: the bound on log-probability mismatch scales as $(1-p)$ where $p$ is the token probability. For high-probability tokens, this bound vanishes, contributing negligibly to sequence-level mismatch. For low-probability tokens in the tail, the bound remains large, and moreover, when sampled, these tokens exhibit systematically biased mismatches that accumulate over sequences, destabilizing gradient estimation. Rather than applying post-hoc corrections, we propose constraining the RL objective to a dynamically-pruned ``safe'' vocabulary that excludes the extreme tail. By pruning such tokens, we trade large, systematically biased mismatches for a small, bounded optimization bias. Empirically, our method achieves stable training; theoretically, we bound the optimization bias introduced by vocabulary pruning.
Policy-Conditioned Policies for Multi-Agent Task Solving
Dec 24, 2025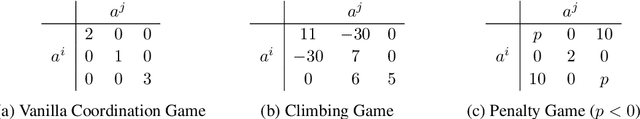

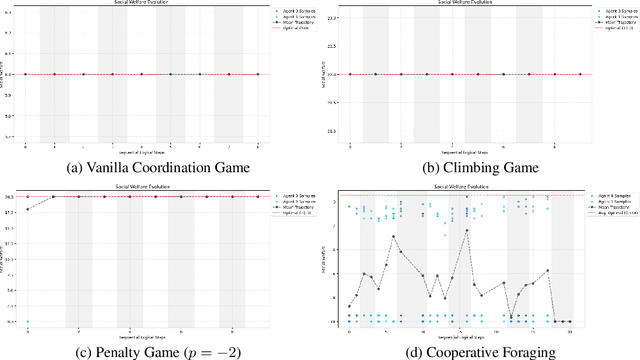
In multi-agent tasks, the central challenge lies in the dynamic adaptation of strategies. However, directly conditioning on opponents' strategies is intractable in the prevalent deep reinforcement learning paradigm due to a fundamental ``representational bottleneck'': neural policies are opaque, high-dimensional parameter vectors that are incomprehensible to other agents. In this work, we propose a paradigm shift that bridges this gap by representing policies as human-interpretable source code and utilizing Large Language Models (LLMs) as approximate interpreters. This programmatic representation allows us to operationalize the game-theoretic concept of \textit{Program Equilibrium}. We reformulate the learning problem by utilizing LLMs to perform optimization directly in the space of programmatic policies. The LLM functions as a point-wise best-response operator that iteratively synthesizes and refines the ego agent's policy code to respond to the opponent's strategy. We formalize this process as \textit{Programmatic Iterated Best Response (PIBR)}, an algorithm where the policy code is optimized by textual gradients, using structured feedback derived from game utility and runtime unit tests. We demonstrate that this approach effectively solves several standard coordination matrix games and a cooperative Level-Based Foraging environment.
Reinforcement Learning for Target Zone Blood Glucose Control
Aug 05, 2025Managing physiological variables within clinically safe target zones is a central challenge in healthcare, particularly for chronic conditions such as Type 1 Diabetes Mellitus (T1DM). Reinforcement learning (RL) offers promise for personalising treatment, but struggles with the delayed and heterogeneous effects of interventions. We propose a novel RL framework to study and support decision-making in T1DM technologies, such as automated insulin delivery. Our approach captures the complex temporal dynamics of treatment by unifying two control modalities: \textit{impulse control} for discrete, fast-acting interventions (e.g., insulin boluses), and \textit{switching control} for longer-acting treatments and regime shifts. The core of our method is a constrained Markov decision process augmented with physiological state features, enabling safe policy learning under clinical and resource constraints. The framework incorporates biologically realistic factors, including insulin decay, leading to policies that better reflect real-world therapeutic behaviour. While not intended for clinical deployment, this work establishes a foundation for future safe and temporally-aware RL in healthcare. We provide theoretical guarantees of convergence and demonstrate empirical improvements in a stylised T1DM control task, reducing blood glucose level violations from 22.4\% (state-of-the-art) to as low as 10.8\%.
Information Bargaining: Bilateral Commitment in Bayesian Persuasion
Jun 09, 2025Bayesian persuasion, an extension of cheap-talk communication, involves an informed sender committing to a signaling scheme to influence a receiver's actions. Compared to cheap talk, this sender's commitment enables the receiver to verify the incentive compatibility of signals beforehand, facilitating cooperation. While effective in one-shot scenarios, Bayesian persuasion faces computational complexity (NP-hardness) when extended to long-term interactions, where the receiver may adopt dynamic strategies conditional on past outcomes and future expectations. To address this complexity, we introduce the bargaining perspective, which allows: (1) a unified framework and well-structured solution concept for long-term persuasion, with desirable properties such as fairness and Pareto efficiency; (2) a clear distinction between two previously conflated advantages: the sender's informational advantage and first-proposer advantage. With only modest modifications to the standard setting, this perspective makes explicit the common knowledge of the game structure and grants the receiver comparable commitment capabilities, thereby reinterpreting classic one-sided persuasion as a balanced information bargaining framework. The framework is validated through a two-stage validation-and-inference paradigm: We first demonstrate that GPT-o3 and DeepSeek-R1, out of publicly available LLMs, reliably handle standard tasks; We then apply them to persuasion scenarios to test that the outcomes align with what our information-bargaining framework suggests. All code, results, and terminal logs are publicly available at github.com/YueLin301/InformationBargaining.
Bayesian Persuasion as a Bargaining Game
Jun 06, 2025Bayesian persuasion, an extension of cheap-talk communication, involves an informed sender committing to a signaling scheme to influence a receiver's actions. Compared to cheap talk, this sender's commitment enables the receiver to verify the incentive compatibility of signals beforehand, facilitating cooperation. While effective in one-shot scenarios, Bayesian persuasion faces computational complexity (NP-hardness) when extended to long-term interactions, where the receiver may adopt dynamic strategies conditional on past outcomes and future expectations. To address this complexity, we introduce the bargaining perspective, which allows: (1) a unified framework and well-structured solution concept for long-term persuasion, with desirable properties such as fairness and Pareto efficiency; (2) a clear distinction between two previously conflated advantages: the sender's informational advantage and first-proposer advantage. With only modest modifications to the standard setting, this perspective makes explicit the common knowledge of the game structure and grants the receiver comparable commitment capabilities, thereby reinterpreting classic one-sided persuasion as a balanced information bargaining framework. The framework is validated through a two-stage validation-and-inference paradigm: We first demonstrate that GPT-o3 and DeepSeek-R1, out of publicly available LLMs, reliably handle standard tasks; We then apply them to persuasion scenarios to test that the outcomes align with what our information-bargaining framework suggests. All code, results, and terminal logs are publicly available at github.com/YueLin301/InformationBargaining.
ADG: Ambient Diffusion-Guided Dataset Recovery for Corruption-Robust Offline Reinforcement Learning
May 29, 2025Real-world datasets collected from sensors or human inputs are prone to noise and errors, posing significant challenges for applying offline reinforcement learning (RL). While existing methods have made progress in addressing corrupted actions and rewards, they remain insufficient for handling corruption in high-dimensional state spaces and for cases where multiple elements in the dataset are corrupted simultaneously. Diffusion models, known for their strong denoising capabilities, offer a promising direction for this problem-but their tendency to overfit noisy samples limits their direct applicability. To overcome this, we propose Ambient Diffusion-Guided Dataset Recovery (ADG), a novel approach that pioneers the use of diffusion models to tackle data corruption in offline RL. First, we introduce Ambient Denoising Diffusion Probabilistic Models (DDPM) from approximated distributions, which enable learning on partially corrupted datasets with theoretical guarantees. Second, we use the noise-prediction property of Ambient DDPM to distinguish between clean and corrupted data, and then use the clean subset to train a standard DDPM. Third, we employ the trained standard DDPM to refine the previously identified corrupted data, enhancing data quality for subsequent offline RL training. A notable strength of ADG is its versatility-it can be seamlessly integrated with any offline RL algorithm. Experiments on a range of benchmarks, including MuJoCo, Kitchen, and Adroit, demonstrate that ADG effectively mitigates the impact of corrupted data and improves the robustness of offline RL under various noise settings, achieving state-of-the-art results.
Learning to Negotiate via Voluntary Commitment
Mar 05, 2025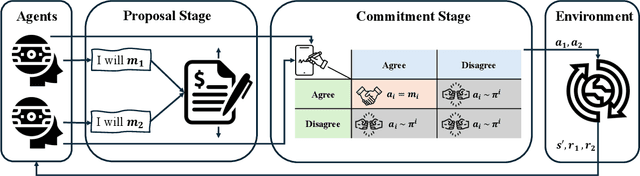
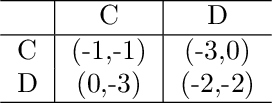
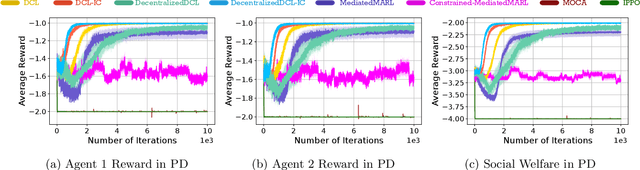

The partial alignment and conflict of autonomous agents lead to mixed-motive scenarios in many real-world applications. However, agents may fail to cooperate in practice even when cooperation yields a better outcome. One well known reason for this failure comes from non-credible commitments. To facilitate commitments among agents for better cooperation, we define Markov Commitment Games (MCGs), a variant of commitment games, where agents can voluntarily commit to their proposed future plans. Based on MCGs, we propose a learnable commitment protocol via policy gradients. We further propose incentive-compatible learning to accelerate convergence to equilibria with better social welfare. Experimental results in challenging mixed-motive tasks demonstrate faster empirical convergence and higher returns for our method compared with its counterparts. Our code is available at https://github.com/shuhui-zhu/DCL.