 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization
Feb 26, 2026Exploration remains the key bottleneck for large language model agents trained with reinforcement learning. While prior methods exploit pretrained knowledge, they fail in environments requiring the discovery of novel states. We propose Exploratory Memory-Augmented On- and Off-Policy Optimization (EMPO$^2$), a hybrid RL framework that leverages memory for exploration and combines on- and off-policy updates to make LLMs perform well with memory while also ensuring robustness without it. On ScienceWorld and WebShop, EMPO$^2$ achieves 128.6% and 11.3% improvements over GRPO, respectively. Moreover, in out-of-distribution tests, EMPO$^2$ demonstrates superior adaptability to new tasks, requiring only a few trials with memory and no parameter updates. These results highlight EMPO$^2$ as a promising framework for building more exploratory and generalizable LLM-based agents.
Temporal Difference Learning with Constrained Initial Representations
Feb 12, 2026Recently, there have been numerous attempts to enhance the sample efficiency of off-policy reinforcement learning (RL) agents when interacting with the environment, including architecture improvements and new algorithms. Despite these advances, they overlook the potential of directly constraining the initial representations of the input data, which can intuitively alleviate the distribution shift issue and stabilize training. In this paper, we introduce the Tanh function into the initial layer to fulfill such a constraint. We theoretically unpack the convergence property of the temporal difference learning with the Tanh function under linear function approximation. Motivated by theoretical insights, we present our Constrained Initial Representations framework, tagged CIR, which is made up of three components: (i) the Tanh activation along with normalization methods to stabilize representations; (ii) the skip connection module to provide a linear pathway from the shallow layer to the deep layer; (iii) the convex Q-learning that allows a more flexible value estimate and mitigates potential conservatism. Empirical results show that CIR exhibits strong performance on numerous continuous control tasks, even being competitive or surpassing existing strong baseline methods.
SE-Bench: Benchmarking Self-Evolution with Knowledge Internalization
Feb 04, 2026True self-evolution requires agents to act as lifelong learners that internalize novel experiences to solve future problems. However, rigorously measuring this foundational capability is hindered by two obstacles: the entanglement of prior knowledge, where ``new'' knowledge may appear in pre-training data, and the entanglement of reasoning complexity, where failures may stem from problem difficulty rather than an inability to recall learned knowledge. We introduce SE-Bench, a diagnostic environment that obfuscates the NumPy library and its API doc into a pseudo-novel package with randomized identifiers. Agents are trained to internalize this package and evaluated on simple coding tasks without access to documentation, yielding a clean setting where tasks are trivial with the new API doc but impossible for base models without it. Our investigation reveals three insights: (1) the Open-Book Paradox, where training with reference documentation inhibits retention, requiring "Closed-Book Training" to force knowledge compression into weights; (2) the RL Gap, where standard RL fails to internalize new knowledge completely due to PPO clipping and negative gradients; and (3) the viability of Self-Play for internalization, proving models can learn from self-generated, noisy tasks when coupled with SFT, but not RL. Overall, SE-Bench establishes a rigorous diagnostic platform for self-evolution with knowledge internalization. Our code and dataset can be found at https://github.com/thunlp/SE-Bench.
CPMobius: Iterative Coach-Player Reasoning for Data-Free Reinforcement Learning
Feb 03, 2026Large Language Models (LLMs) have demonstrated strong potential in complex reasoning, yet their progress remains fundamentally constrained by reliance on massive high-quality human-curated tasks and labels, either through supervised fine-tuning (SFT) or reinforcement learning (RL) on reasoning-specific data. This dependence renders supervision-heavy training paradigms increasingly unsustainable, with signs of diminishing scalability already evident in practice. To overcome this limitation, we introduce CPMöbius (CPMobius), a collaborative Coach-Player paradigm for data-free reinforcement learning of reasoning models. Unlike traditional adversarial self-play, CPMöbius, inspired by real world human sports collaboration and multi-agent collaboration, treats the Coach and Player as independent but cooperative roles. The Coach proposes instructions targeted at the Player's capability and receives rewards based on changes in the Player's performance, while the Player is rewarded for solving the increasingly instructive tasks generated by the Coach. This cooperative optimization loop is designed to directly enhance the Player's mathematical reasoning ability. Remarkably, CPMöbius achieves substantial improvement without relying on any external training data, outperforming existing unsupervised approaches. For example, on Qwen2.5-Math-7B-Instruct, our method improves accuracy by an overall average of +4.9 and an out-of-distribution average of +5.4, exceeding RENT by +1.5 on overall accuracy and R-zero by +4.2 on OOD accuracy.
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
Dec 18, 2025Recent advances in reinforcement learning for large language models have converged on increasing complexity: multi-stage training pipelines, dynamic hyperparameter schedules, and curriculum learning strategies. This raises a fundamental question: \textbf{Is this complexity necessary?} We present \textbf{JustRL}, a minimal approach using single-stage training with fixed hyperparameters that achieves state-of-the-art performance on two 1.5B reasoning models (54.9\% and 64.3\% average accuracy across nine mathematical benchmarks) while using 2$\times$ less compute than sophisticated approaches. The same hyperparameters transfer across both models without tuning, and training exhibits smooth, monotonic improvement over 4,000+ steps without the collapses or plateaus that typically motivate interventions. Critically, ablations reveal that adding ``standard tricks'' like explicit length penalties and robust verifiers may degrade performance by collapsing exploration. These results suggest that the field may be adding complexity to solve problems that disappear with a stable, scaled-up baseline. We release our models and code to establish a simple, validated baseline for the community.
ADG: Ambient Diffusion-Guided Dataset Recovery for Corruption-Robust Offline Reinforcement Learning
May 29, 2025Real-world datasets collected from sensors or human inputs are prone to noise and errors, posing significant challenges for applying offline reinforcement learning (RL). While existing methods have made progress in addressing corrupted actions and rewards, they remain insufficient for handling corruption in high-dimensional state spaces and for cases where multiple elements in the dataset are corrupted simultaneously. Diffusion models, known for their strong denoising capabilities, offer a promising direction for this problem-but their tendency to overfit noisy samples limits their direct applicability. To overcome this, we propose Ambient Diffusion-Guided Dataset Recovery (ADG), a novel approach that pioneers the use of diffusion models to tackle data corruption in offline RL. First, we introduce Ambient Denoising Diffusion Probabilistic Models (DDPM) from approximated distributions, which enable learning on partially corrupted datasets with theoretical guarantees. Second, we use the noise-prediction property of Ambient DDPM to distinguish between clean and corrupted data, and then use the clean subset to train a standard DDPM. Third, we employ the trained standard DDPM to refine the previously identified corrupted data, enhancing data quality for subsequent offline RL training. A notable strength of ADG is its versatility-it can be seamlessly integrated with any offline RL algorithm. Experiments on a range of benchmarks, including MuJoCo, Kitchen, and Adroit, demonstrate that ADG effectively mitigates the impact of corrupted data and improves the robustness of offline RL under various noise settings, achieving state-of-the-art results.
CDSA: Conservative Denoising Score-based Algorithm for Offline Reinforcement Learning
Jun 11, 2024Distribution shift is a major obstacle in offline reinforcement learning, which necessitates minimizing the discrepancy between the learned policy and the behavior policy to avoid overestimating rare or unseen actions. Previous conservative offline RL algorithms struggle to generalize to unseen actions, despite their success in learning good in-distribution policy. In contrast, we propose to use the gradient fields of the dataset density generated from a pre-trained offline RL algorithm to adjust the original actions. We decouple the conservatism constraints from the policy, thus can benefit wide offline RL algorithms. As a consequence, we propose the Conservative Denoising Score-based Algorithm (CDSA) which utilizes the denoising score-based model to model the gradient of the dataset density, rather than the dataset density itself, and facilitates a more accurate and efficient method to adjust the action generated by the pre-trained policy in a deterministic and continuous MDP environment. In experiments, we show that our approach significantly improves the performance of baseline algorithms in D4RL datasets, and demonstrate the generalizability and plug-and-play capability of our model across different pre-trained offline RL policy in different tasks. We also validate that the agent exhibits greater risk aversion after employing our method while showcasing its ability to generalize effectively across diverse tasks.
World Models with Hints of Large Language Models for Goal Achieving
Jun 11, 2024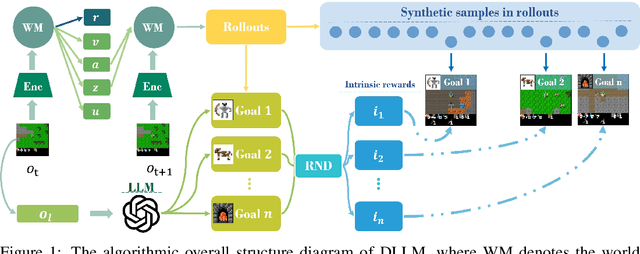

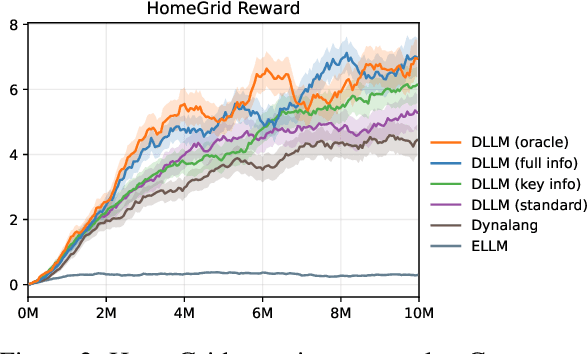
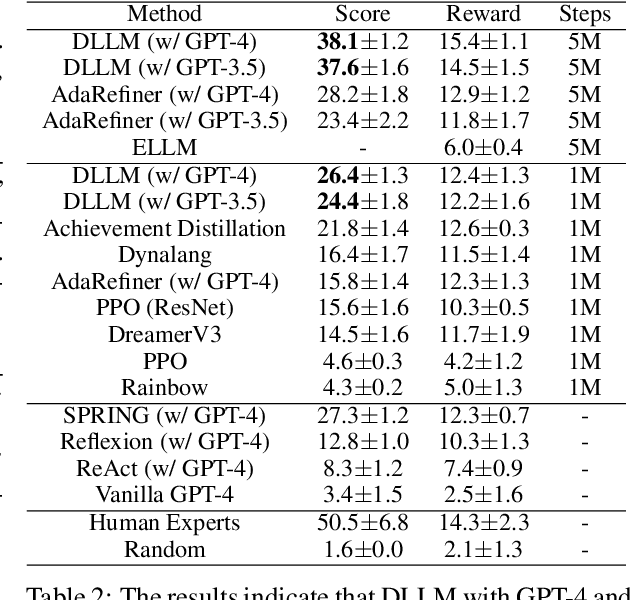
Reinforcement learning struggles in the face of long-horizon tasks and sparse goals due to the difficulty in manual reward specification. While existing methods address this by adding intrinsic rewards, they may fail to provide meaningful guidance in long-horizon decision-making tasks with large state and action spaces, lacking purposeful exploration. Inspired by human cognition, we propose a new multi-modal model-based RL approach named Dreaming with Large Language Models (DLLM). DLLM integrates the proposed hinting subgoals from the LLMs into the model rollouts to encourage goal discovery and reaching in challenging tasks. By assigning higher intrinsic rewards to samples that align with the hints outlined by the language model during model rollouts, DLLM guides the agent toward meaningful and efficient exploration. Extensive experiments demonstrate that the DLLM outperforms recent methods in various challenging, sparse-reward environments such as HomeGrid, Crafter, and Minecraft by 27.7\%, 21.1\%, and 9.9\%, respectively.
Adaptive Boosting with Fairness-aware Reweighting Technique for Fair Classification
Jan 06, 2024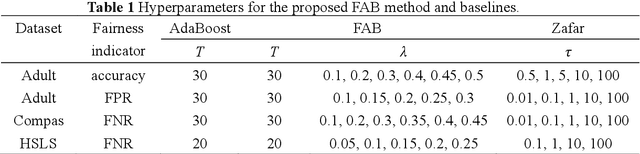
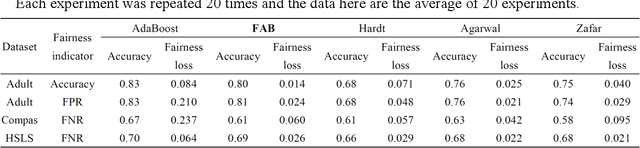
Machine learning methods based on AdaBoost have been widely applied to various classification problems across many mission-critical applications including healthcare, law and finance. However, there is a growing concern about the unfairness and discrimination of data-driven classification models, which is inevitable for classical algorithms including AdaBoost. In order to achieve fair classification, a novel fair AdaBoost (FAB) approach is proposed that is an interpretable fairness-improving variant of AdaBoost. We mainly investigate binary classification problems and focus on the fairness of three different indicators (i.e., accuracy, false positive rate and false negative rate). By utilizing a fairness-aware reweighting technique for base classifiers, the proposed FAB approach can achieve fair classification while maintaining the advantage of AdaBoost with negligible sacrifice of predictive performance. In addition, a hyperparameter is introduced in FAB to show preferences for the fairness-accuracy trade-off. An upper bound for the target loss function that quantifies error rate and unfairness is theoretically derived for FAB, which provides a strict theoretical support for the fairness-improving methods designed for AdaBoost. The effectiveness of the proposed method is demonstrated on three real-world datasets (i.e., Adult, COMPAS and HSLS) with respect to the three fairness indicators. The results are accordant with theoretic analyses, and show that (i) FAB significantly improves classification fairness at a small cost of accuracy compared with AdaBoost; and (ii) FAB outperforms state-of-the-art fair classification methods including equalized odds method, exponentiated gradient method, and disparate mistreatment method in terms of the fairness-accuracy trade-off.