 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Distill: Cross-Architecture Vision Distillation for Visuomotor Learning
Jan 16, 2026Visuomotor policies often leverage large pre-trained Vision Transformers (ViTs) for their powerful generalization capabilities. However, their significant data requirements present a major challenge in the data-scarce context of most robotic learning settings, where compact CNNs with strong inductive biases can be more easily optimized. To address this trade-off, we introduce X-Distill, a simple yet highly effective method that synergizes the strengths of both architectures. Our approach involves an offline, cross-architecture knowledge distillation, transferring the rich visual representations of a large, frozen DINOv2 teacher to a compact ResNet-18 student on the general-purpose ImageNet dataset. This distilled encoder, now endowed with powerful visual priors, is then jointly fine-tuned with a diffusion policy head on the target manipulation tasks. Extensive experiments on $34$ simulated benchmarks and $5$ challenging real-world tasks demonstrate that our method consistently outperforms policies equipped with from-scratch ResNet or fine-tuned DINOv2 encoders. Notably, X-Distill also surpasses 3D encoders that utilize privileged point cloud observations or much larger Vision-Language Models. Our work highlights the efficacy of a simple, well-founded distillation strategy for achieving state-of-the-art performance in data-efficient robotic manipulation.
Failure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation
Jan 12, 2026Post-training algorithms based on deep reinforcement learning can push the limits of robotic models for specific objectives, such as generalizability, accuracy, and robustness. However, Intervention-requiring Failures (IR Failures) (e.g., a robot spilling water or breaking fragile glass) during real-world exploration happen inevitably, hindering the practical deployment of such a paradigm. To tackle this, we introduce Failure-Aware Offline-to-Online Reinforcement Learning (FARL), a new paradigm minimizing failures during real-world reinforcement learning. We create FailureBench, a benchmark that incorporates common failure scenarios requiring human intervention, and propose an algorithm that integrates a world-model-based safety critic and a recovery policy trained offline to prevent failures during online exploration. Extensive simulation and real-world experiments demonstrate the effectiveness of FARL in significantly reducing IR Failures while improving performance and generalization during online reinforcement learning post-training. FARL reduces IR Failures by 73.1% while elevating performance by 11.3% on average during real-world RL post-training. Videos and code are available at https://failure-aware-rl.github.io.
MoE-DP: An MoE-Enhanced Diffusion Policy for Robust Long-Horizon Robotic Manipulation with Skill Decomposition and Failure Recovery
Nov 07, 2025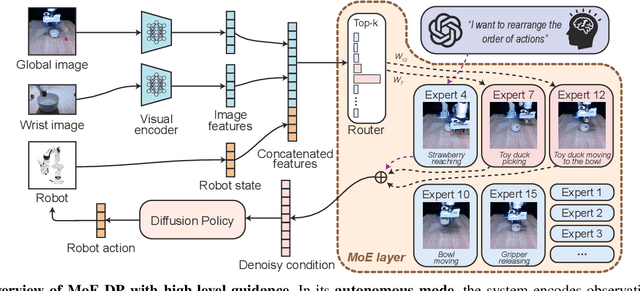
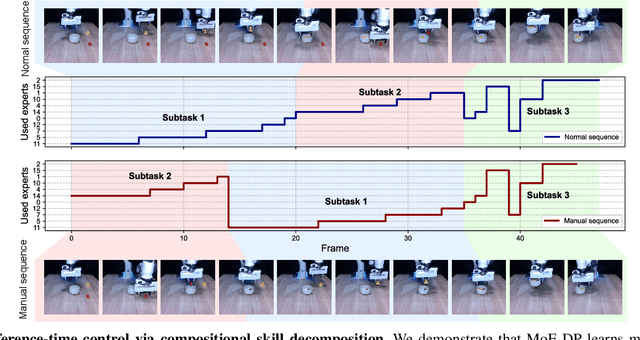
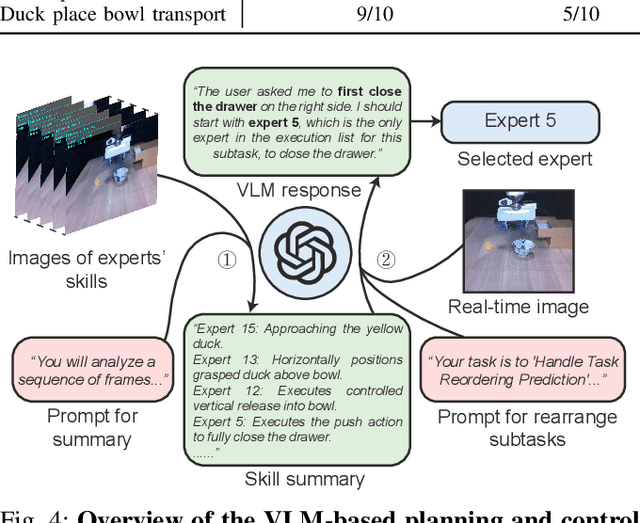
Diffusion policies have emerged as a powerful framework for robotic visuomotor control, yet they often lack the robustness to recover from subtask failures in long-horizon, multi-stage tasks and their learned representations of observations are often difficult to interpret. In this work, we propose the Mixture of Experts-Enhanced Diffusion Policy (MoE-DP), where the core idea is to insert a Mixture of Experts (MoE) layer between the visual encoder and the diffusion model. This layer decomposes the policy's knowledge into a set of specialized experts, which are dynamically activated to handle different phases of a task. We demonstrate through extensive experiments that MoE-DP exhibits a strong capability to recover from disturbances, significantly outperforming standard baselines in robustness. On a suite of 6 long-horizon simulation tasks, this leads to a 36% average relative improvement in success rate under disturbed conditions. This enhanced robustness is further validated in the real world, where MoE-DP also shows significant performance gains. We further show that MoE-DP learns an interpretable skill decomposition, where distinct experts correspond to semantic task primitives (e.g., approaching, grasping). This learned structure can be leveraged for inference-time control, allowing for the rearrangement of subtasks without any re-training.Our video and code are available at the https://moe-dp-website.github.io/MoE-DP-Website/.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
HERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
Aug 28, 2025Leveraging human motion data to impart robots with versatile manipulation skills has emerged as a promising paradigm in robotic manipulation. Nevertheless, translating multi-source human hand motions into feasible robot behaviors remains challenging, particularly for robots equipped with multi-fingered dexterous hands characterized by complex, high-dimensional action spaces. Moreover, existing approaches often struggle to produce policies capable of adapting to diverse environmental conditions. In this paper, we introduce HERMES, a human-to-robot learning framework for mobile bimanual dexterous manipulation. First, HERMES formulates a unified reinforcement learning approach capable of seamlessly transforming heterogeneous human hand motions from multiple sources into physically plausible robotic behaviors. Subsequently, to mitigate the sim2real gap, we devise an end-to-end, depth image-based sim2real transfer method for improved generalization to real-world scenarios. Furthermore, to enable autonomous operation in varied and unstructured environments, we augment the navigation foundation model with a closed-loop Perspective-n-Point (PnP) localization mechanism, ensuring precise alignment of visual goals and effectively bridging autonomous navigation and dexterous manipulation. Extensive experimental results demonstrate that HERMES consistently exhibits generalizable behaviors across diverse, in-the-wild scenarios, successfully performing numerous complex mobile bimanual dexterous manipulation tasks. Project Page:https://gemcollector.github.io/HERMES/.
4D Visual Pre-training for Robot Learning
Aug 24, 2025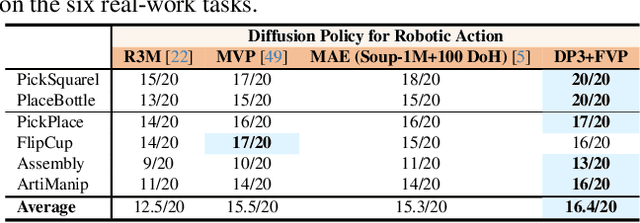
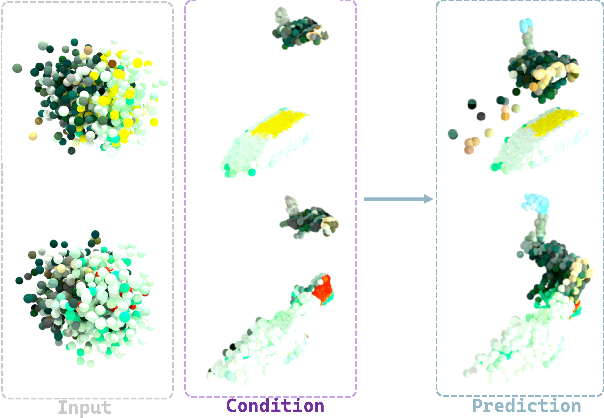
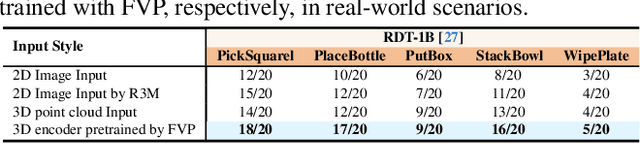
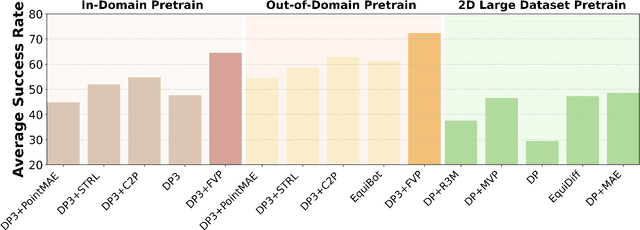
General visual representations learned from web-scale datasets for robotics have achieved great success in recent years, enabling data-efficient robot learning on manipulation tasks; yet these pre-trained representations are mostly on 2D images, neglecting the inherent 3D nature of the world. However, due to the scarcity of large-scale 3D data, it is still hard to extract a universal 3D representation from web datasets. Instead, we are seeking a general visual pre-training framework that could improve all 3D representations as an alternative. Our framework, called FVP, is a novel 4D Visual Pre-training framework for real-world robot learning. FVP frames the visual pre-training objective as a next-point-cloud-prediction problem, models the prediction model as a diffusion model, and pre-trains the model on the larger public datasets directly. Across twelve real-world manipulation tasks, FVP boosts the average success rate of 3D Diffusion Policy (DP3) for these tasks by 28%. The FVP pre-trained DP3 achieves state-of-the-art performance across imitation learning methods. Moreover, the efficacy of FVP adapts across various point cloud encoders and datasets. Finally, we apply FVP to the RDT-1B, a larger Vision-Language-Action robotic model, enhancing its performance on various robot tasks. Our project page is available at: https://4d- visual-pretraining.github.io/.
Morpheus: A Neural-driven Animatronic Face with Hybrid Actuation and Diverse Emotion Control
Jul 22, 2025Previous animatronic faces struggle to express emotions effectively due to hardware and software limitations. On the hardware side, earlier approaches either use rigid-driven mechanisms, which provide precise control but are difficult to design within constrained spaces, or tendon-driven mechanisms, which are more space-efficient but challenging to control. In contrast, we propose a hybrid actuation approach that combines the best of both worlds. The eyes and mouth-key areas for emotional expression-are controlled using rigid mechanisms for precise movement, while the nose and cheek, which convey subtle facial microexpressions, are driven by strings. This design allows us to build a compact yet versatile hardware platform capable of expressing a wide range of emotions. On the algorithmic side, our method introduces a self-modeling network that maps motor actions to facial landmarks, allowing us to automatically establish the relationship between blendshape coefficients for different facial expressions and the corresponding motor control signals through gradient backpropagation. We then train a neural network to map speech input to corresponding blendshape controls. With our method, we can generate distinct emotional expressions such as happiness, fear, disgust, and anger, from any given sentence, each with nuanced, emotion-specific control signals-a feature that has not been demonstrated in earlier systems. We release the hardware design and code at https://github.com/ZZongzheng0918/Morpheus-Hardware and https://github.com/ZZongzheng0918/Morpheus-Software.
A Forget-and-Grow Strategy for Deep Reinforcement Learning Scaling in Continuous Control
Jul 03, 2025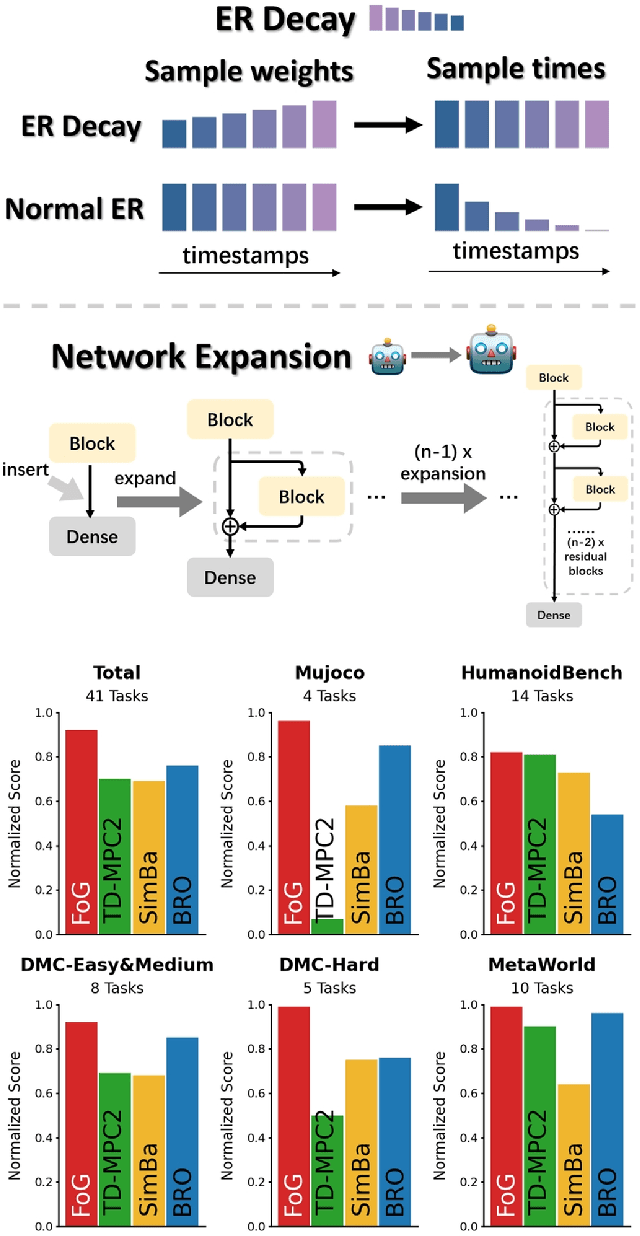
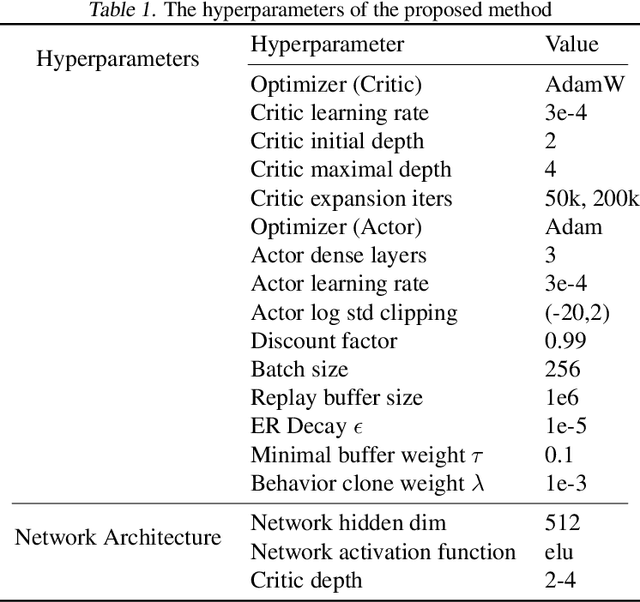
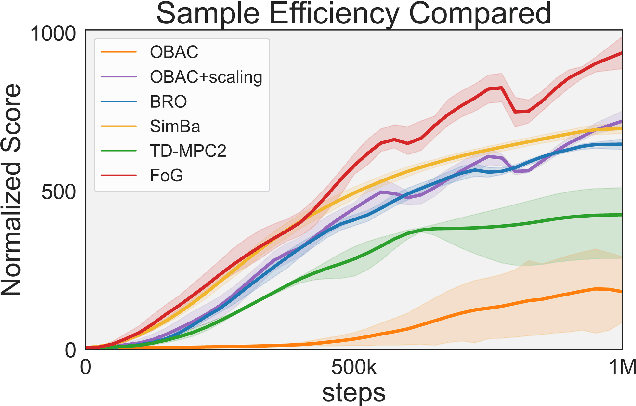
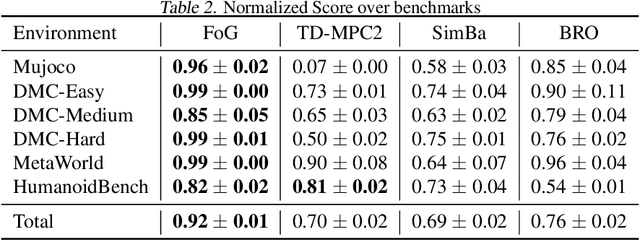
Deep reinforcement learning for continuous control has recently achieved impressive progress. However, existing methods often suffer from primacy bias, a tendency to overfit early experiences stored in the replay buffer, which limits an RL agent's sample efficiency and generalizability. In contrast, humans are less susceptible to such bias, partly due to infantile amnesia, where the formation of new neurons disrupts early memory traces, leading to the forgetting of initial experiences. Inspired by this dual processes of forgetting and growing in neuroscience, in this paper, we propose Forget and Grow (FoG), a new deep RL algorithm with two mechanisms introduced. First, Experience Replay Decay (ER Decay) "forgetting early experience", which balances memory by gradually reducing the influence of early experiences. Second, Network Expansion, "growing neural capacity", which enhances agents' capability to exploit the patterns of existing data by dynamically adding new parameters during training. Empirical results on four major continuous control benchmarks with more than 40 tasks demonstrate the superior performance of FoG against SoTA existing deep RL algorithms, including BRO, SimBa, and TD-MPC2.
DemoSpeedup: Accelerating Visuomotor Policies via Entropy-Guided Demonstration Acceleration
Jun 05, 2025Imitation learning has shown great promise in robotic manipulation, but the policy's execution is often unsatisfactorily slow due to commonly tardy demonstrations collected by human operators. In this work, we present DemoSpeedup, a self-supervised method to accelerate visuomotor policy execution via entropy-guided demonstration acceleration. DemoSpeedup starts from training an arbitrary generative policy (e.g., ACT or Diffusion Policy) on normal-speed demonstrations, which serves as a per-frame action entropy estimator. The key insight is that frames with lower action entropy estimates call for more consistent policy behaviors, which often indicate the demands for higher-precision operations. In contrast, frames with higher entropy estimates correspond to more casual sections, and therefore can be more safely accelerated. Thus, we segment the original demonstrations according to the estimated entropy, and accelerate them by down-sampling at rates that increase with the entropy values. Trained with the speedup demonstrations, the resulting policies execute up to 3 times faster while maintaining the task completion performance. Interestingly, these policies could even achieve higher success rates than those trained with normal-speed demonstrations, due to the benefits of reduced decision-making horizons.
Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities
May 21, 2025Reinforcement learning (RL) has emerged as an effective method for training reasoning models. However, existing RL approaches typically bias the model's output distribution toward reward-maximizing paths without introducing external knowledge. This limits their exploration capacity and results in a narrower reasoning capability boundary compared to base models. To address this limitation, we propose TAPO (Thought-Augmented Policy Optimization), a novel framework that augments RL by incorporating external high-level guidance ("thought patterns"). By adaptively integrating structured thoughts during training, TAPO effectively balances model-internal exploration and external guidance exploitation. Extensive experiments show that our approach significantly outperforms GRPO by 99% on AIME, 41% on AMC, and 17% on Minerva Math. Notably, these high-level thought patterns, abstracted from only 500 prior samples, generalize effectively across various tasks and models. This highlights TAPO's potential for broader applications across multiple tasks and domains. Our further analysis reveals that introducing external guidance produces powerful reasoning models with superior explainability of inference behavior and enhanced output readability.