 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArrayTac: A tactile display for simultaneous rendering of shape, stiffness and friction
Mar 14, 2026Human-computer interaction in the visual and auditory domains has achieved considerable maturity, yet machine-to-human tactile feedback remains underdeveloped. Existing tactile displays struggle to simultaneously render multiple tactile dimensions, such as shape, stiffness, and friction, which limits the realism of haptic simulation. Here, we present ArrayTac, a piezoelectric-driven tactile display capable of simultaneously rendering shape, stiffness, and friction to reproduce realistic haptic signals. The system comprises a 4x4 array of 16 actuator units, each employing a three-stage micro-lever mechanism to amplify the micrometer-scale displacement of the piezoelectric element, with Hall sensor-based closed-loop control at the end effector to enhance response speed and precision. We further implement two end-to-end pipelines: 1) a vision-to-touch framework that converts visual inputs into tactile signals using multimodal foundation models, and 2) a real-time tele-palpation system operating over distances of several thousand kilometers. In user studies, first-time participants accurately identify object shapes and physical properties with high success rates. In a tele-palpation experiment over 1,000km, untrained volunteers correctly identified both the number and type of tumors in a breast phantom with 100% accuracy and precisely localized their positions. The system pioneers a new pathway for high-fidelity haptic feedback by introducing the unprecedented capability to simultaneously render an object's shape, stiffness, and friction, delivering a holistic tactile experience that was previously unattainable.
X-Distill: Cross-Architecture Vision Distillation for Visuomotor Learning
Jan 16, 2026Visuomotor policies often leverage large pre-trained Vision Transformers (ViTs) for their powerful generalization capabilities. However, their significant data requirements present a major challenge in the data-scarce context of most robotic learning settings, where compact CNNs with strong inductive biases can be more easily optimized. To address this trade-off, we introduce X-Distill, a simple yet highly effective method that synergizes the strengths of both architectures. Our approach involves an offline, cross-architecture knowledge distillation, transferring the rich visual representations of a large, frozen DINOv2 teacher to a compact ResNet-18 student on the general-purpose ImageNet dataset. This distilled encoder, now endowed with powerful visual priors, is then jointly fine-tuned with a diffusion policy head on the target manipulation tasks. Extensive experiments on $34$ simulated benchmarks and $5$ challenging real-world tasks demonstrate that our method consistently outperforms policies equipped with from-scratch ResNet or fine-tuned DINOv2 encoders. Notably, X-Distill also surpasses 3D encoders that utilize privileged point cloud observations or much larger Vision-Language Models. Our work highlights the efficacy of a simple, well-founded distillation strategy for achieving state-of-the-art performance in data-efficient robotic manipulation.
MoE-DP: An MoE-Enhanced Diffusion Policy for Robust Long-Horizon Robotic Manipulation with Skill Decomposition and Failure Recovery
Nov 07, 2025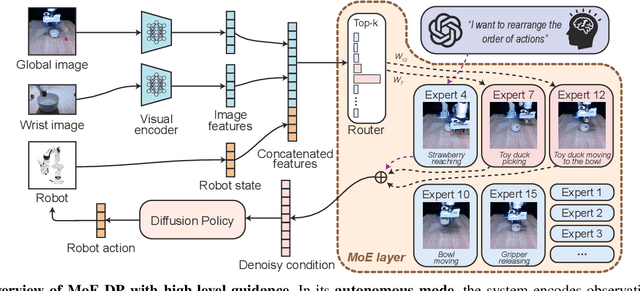
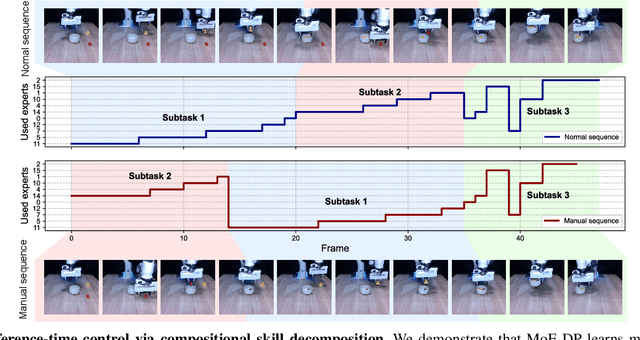
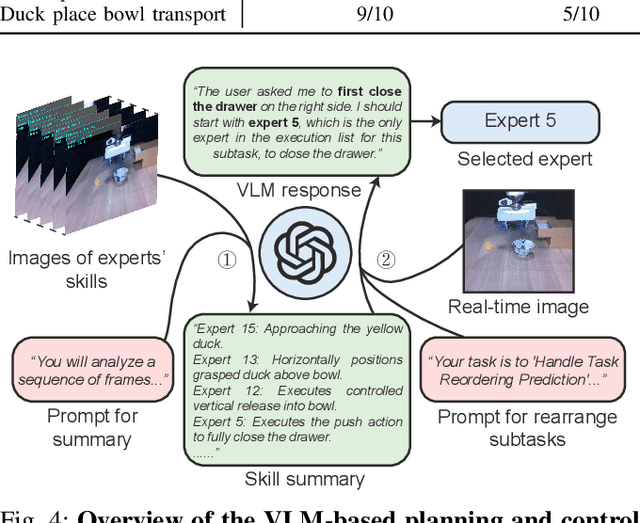
Diffusion policies have emerged as a powerful framework for robotic visuomotor control, yet they often lack the robustness to recover from subtask failures in long-horizon, multi-stage tasks and their learned representations of observations are often difficult to interpret. In this work, we propose the Mixture of Experts-Enhanced Diffusion Policy (MoE-DP), where the core idea is to insert a Mixture of Experts (MoE) layer between the visual encoder and the diffusion model. This layer decomposes the policy's knowledge into a set of specialized experts, which are dynamically activated to handle different phases of a task. We demonstrate through extensive experiments that MoE-DP exhibits a strong capability to recover from disturbances, significantly outperforming standard baselines in robustness. On a suite of 6 long-horizon simulation tasks, this leads to a 36% average relative improvement in success rate under disturbed conditions. This enhanced robustness is further validated in the real world, where MoE-DP also shows significant performance gains. We further show that MoE-DP learns an interpretable skill decomposition, where distinct experts correspond to semantic task primitives (e.g., approaching, grasping). This learned structure can be leveraged for inference-time control, allowing for the rearrangement of subtasks without any re-training.Our video and code are available at the https://moe-dp-website.github.io/MoE-DP-Website/.
DemoSpeedup: Accelerating Visuomotor Policies via Entropy-Guided Demonstration Acceleration
Jun 05, 2025Imitation learning has shown great promise in robotic manipulation, but the policy's execution is often unsatisfactorily slow due to commonly tardy demonstrations collected by human operators. In this work, we present DemoSpeedup, a self-supervised method to accelerate visuomotor policy execution via entropy-guided demonstration acceleration. DemoSpeedup starts from training an arbitrary generative policy (e.g., ACT or Diffusion Policy) on normal-speed demonstrations, which serves as a per-frame action entropy estimator. The key insight is that frames with lower action entropy estimates call for more consistent policy behaviors, which often indicate the demands for higher-precision operations. In contrast, frames with higher entropy estimates correspond to more casual sections, and therefore can be more safely accelerated. Thus, we segment the original demonstrations according to the estimated entropy, and accelerate them by down-sampling at rates that increase with the entropy values. Trained with the speedup demonstrations, the resulting policies execute up to 3 times faster while maintaining the task completion performance. Interestingly, these policies could even achieve higher success rates than those trained with normal-speed demonstrations, due to the benefits of reduced decision-making horizons.
H$^{\mathbf{3}}$DP: Triply-Hierarchical Diffusion Policy for Visuomotor Learning
May 12, 2025Visuomotor policy learning has witnessed substantial progress in robotic manipulation, with recent approaches predominantly relying on generative models to model the action distribution. However, these methods often overlook the critical coupling between visual perception and action prediction. In this work, we introduce $\textbf{Triply-Hierarchical Diffusion Policy}~(\textbf{H$^{\mathbf{3}}$DP})$, a novel visuomotor learning framework that explicitly incorporates hierarchical structures to strengthen the integration between visual features and action generation. H$^{3}$DP contains $\mathbf{3}$ levels of hierarchy: (1) depth-aware input layering that organizes RGB-D observations based on depth information; (2) multi-scale visual representations that encode semantic features at varying levels of granularity; and (3) a hierarchically conditioned diffusion process that aligns the generation of coarse-to-fine actions with corresponding visual features. Extensive experiments demonstrate that H$^{3}$DP yields a $\mathbf{+27.5\%}$ average relative improvement over baselines across $\mathbf{44}$ simulation tasks and achieves superior performance in $\mathbf{4}$ challenging bimanual real-world manipulation tasks. Project Page: https://lyy-iiis.github.io/h3dp/.
DemoGen: Synthetic Demonstration Generation for Data-Efficient Visuomotor Policy Learning
Feb 24, 2025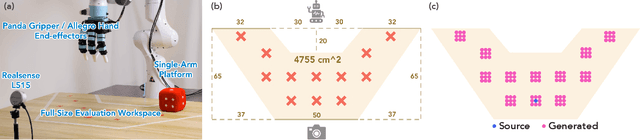
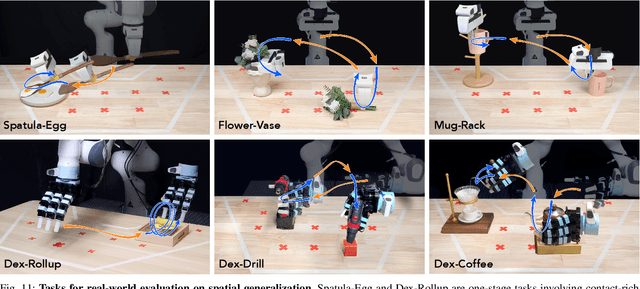
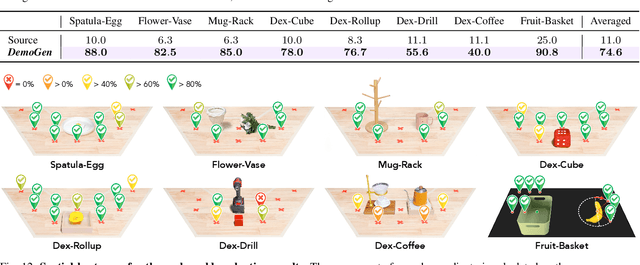

Visuomotor policies have shown great promise in robotic manipulation but often require substantial amounts of human-collected data for effective performance. A key reason underlying the data demands is their limited spatial generalization capability, which necessitates extensive data collection across different object configurations. In this work, we present DemoGen, a low-cost, fully synthetic approach for automatic demonstration generation. Using only one human-collected demonstration per task, DemoGen generates spatially augmented demonstrations by adapting the demonstrated action trajectory to novel object configurations. Visual observations are synthesized by leveraging 3D point clouds as the modality and rearranging the subjects in the scene via 3D editing. Empirically, DemoGen significantly enhances policy performance across a diverse range of real-world manipulation tasks, showing its applicability even in challenging scenarios involving deformable objects, dexterous hand end-effectors, and bimanual platforms. Furthermore, DemoGen can be extended to enable additional out-of-distribution capabilities, including disturbance resistance and obstacle avoidance.
MENTOR: Mixture-of-Experts Network with Task-Oriented Perturbation for Visual Reinforcement Learning
Oct 19, 2024
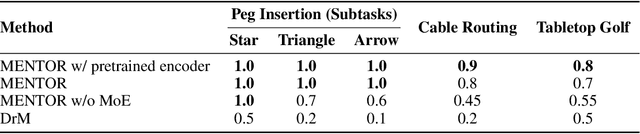
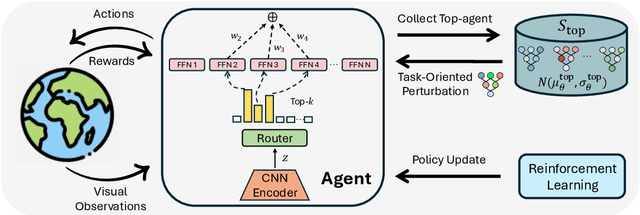
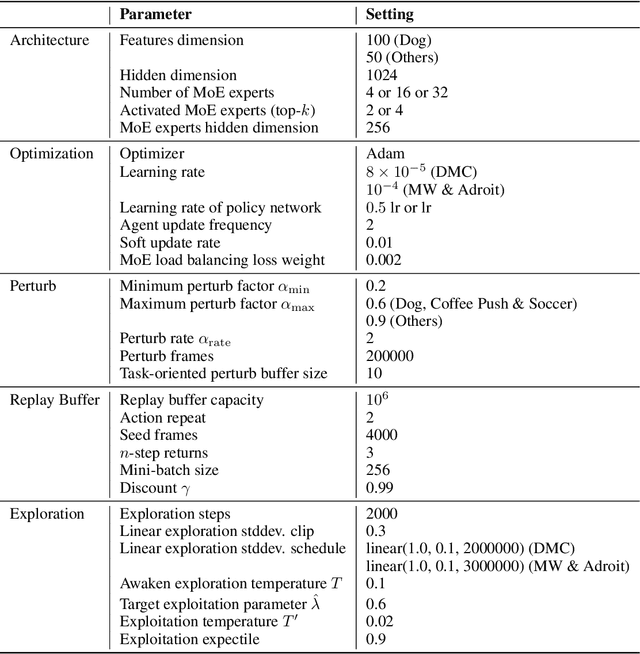
Visual deep reinforcement learning (RL) enables robots to acquire skills from visual input for unstructured tasks. However, current algorithms suffer from low sample efficiency, limiting their practical applicability. In this work, we present MENTOR, a method that improves both the architecture and optimization of RL agents. Specifically, MENTOR replaces the standard multi-layer perceptron (MLP) with a mixture-of-experts (MoE) backbone, enhancing the agent's ability to handle complex tasks by leveraging modular expert learning to avoid gradient conflicts. Furthermore, MENTOR introduces a task-oriented perturbation mechanism, which heuristically samples perturbation candidates containing task-relevant information, leading to more targeted and effective optimization. MENTOR outperforms state-of-the-art methods across three simulation domains -- DeepMind Control Suite, Meta-World, and Adroit. Additionally, MENTOR achieves an average of 83% success rate on three challenging real-world robotic manipulation tasks including peg insertion, cable routing, and tabletop golf, which significantly surpasses the success rate of 32% from the current strongest model-free visual RL algorithm. These results underscore the importance of sample efficiency in advancing visual RL for real-world robotics. Experimental videos are available at https://suninghuang19.github.io/mentor_page.
Key-Grid: Unsupervised 3D Keypoints Detection using Grid Heatmap Features
Oct 03, 2024

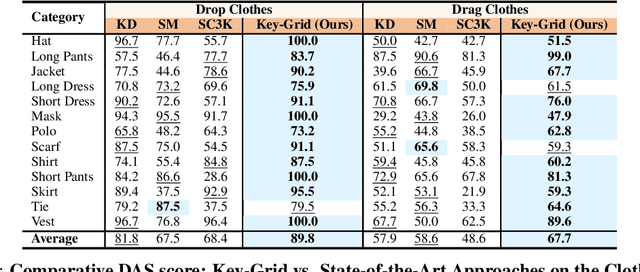
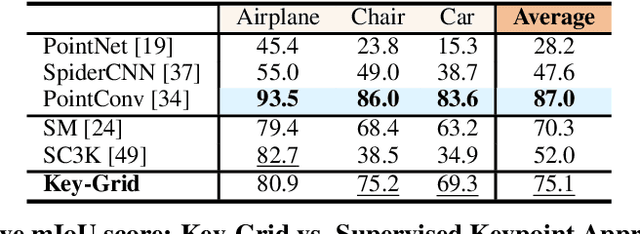
Detecting 3D keypoints with semantic consistency is widely used in many scenarios such as pose estimation, shape registration and robotics. Currently, most unsupervised 3D keypoint detection methods focus on the rigid-body objects. However, when faced with deformable objects, the keypoints they identify do not preserve semantic consistency well. In this paper, we introduce an innovative unsupervised keypoint detector Key-Grid for both the rigid-body and deformable objects, which is an autoencoder framework. The encoder predicts keypoints and the decoder utilizes the generated keypoints to reconstruct the objects. Unlike previous work, we leverage the identified keypoint in formation to form a 3D grid feature heatmap called grid heatmap, which is used in the decoder section. Grid heatmap is a novel concept that represents the latent variables for grid points sampled uniformly in the 3D cubic space, where these variables are the shortest distance between the grid points and the skeleton connected by keypoint pairs. Meanwhile, we incorporate the information from each layer of the encoder into the decoder section. We conduct an extensive evaluation of Key-Grid on a list of benchmark datasets. Key-Grid achieves the state-of-the-art performance on the semantic consistency and position accuracy of keypoints. Moreover, we demonstrate the robustness of Key-Grid to noise and downsampling. In addition, we achieve SE-(3) invariance of keypoints though generalizing Key-Grid to a SE(3)-invariant backbone.
AToM-Bot: Embodied Fulfillment of Unspoken Human Needs with Affective Theory of Mind
Jun 12, 2024



We propose AToM-Bot, a novel task generation and execution framework for proactive robot-human interaction, which leverages the human mental and physical state inference capabilities of the Vision Language Model (VLM) prompted by the Affective Theory of Mind (AToM). Without requiring explicit commands by humans, AToM-Bot proactively generates and follows feasible tasks to improve general human well-being. When around humans, AToM-Bot first detects current human needs based on inferred human states and observations of the surrounding environment. It then generates tasks to fulfill these needs, taking into account its embodied constraints. We designed 16 daily life scenarios spanning 4 common scenes and tasked the same visual stimulus to 59 human subjects and our robot. We used the similarity between human open-ended answers and robot output, and the human satisfaction scores to metric robot performance. AToM-Bot received high human evaluations in need detection (6.42/7, 91.7%), embodied solution (6.15/7, 87.8%) and task execution (6.17/7, 88.1%). We show that AToM-Bot excels in generating and executing feasible plans to fulfill unspoken human needs. Videos and code are available at https://affective-tom-bot.github.io.
RiEMann: Near Real-Time SE-Equivariant Robot Manipulation without Point Cloud Segmentation
Mar 28, 2024



We present RiEMann, an end-to-end near Real-time SE(3)-Equivariant Robot Manipulation imitation learning framework from scene point cloud input. Compared to previous methods that rely on descriptor field matching, RiEMann directly predicts the target poses of objects for manipulation without any object segmentation. RiEMann learns a manipulation task from scratch with 5 to 10 demonstrations, generalizes to unseen SE(3) transformations and instances of target objects, resists visual interference of distracting objects, and follows the near real-time pose change of the target object. The scalable action space of RiEMann facilitates the addition of custom equivariant actions such as the direction of turning the faucet, which makes articulated object manipulation possible for RiEMann. In simulation and real-world 6-DOF robot manipulation experiments, we test RiEMann on 5 categories of manipulation tasks with a total of 25 variants and show that RiEMann outperforms baselines in both task success rates and SE(3) geodesic distance errors on predicted poses (reduced by 68.6%), and achieves a 5.4 frames per second (FPS) network inference speed. Code and video results are available at https://riemann-web.github.io/.