 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Context-Conditioned Anomaly Detection for Tabular Data
Sep 10, 2025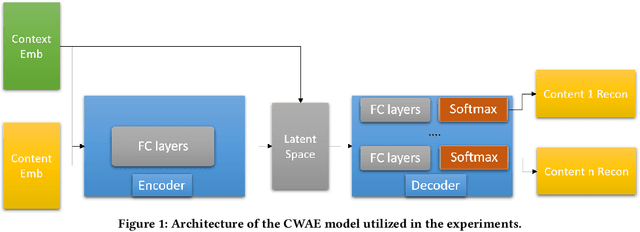
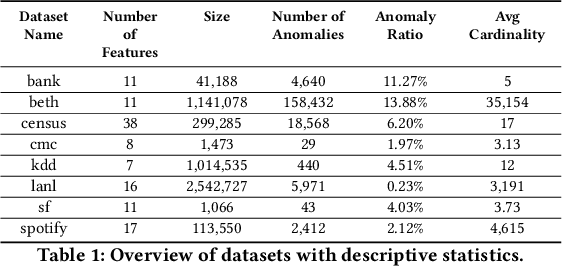
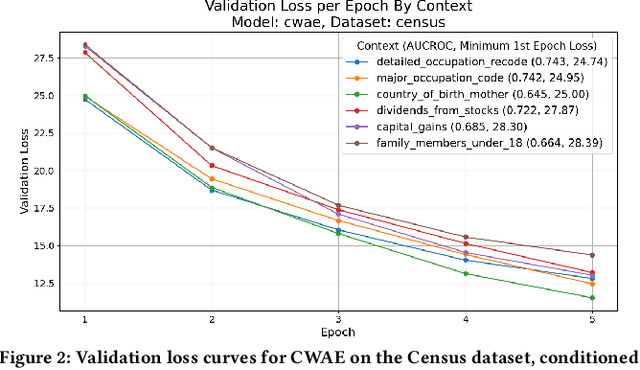
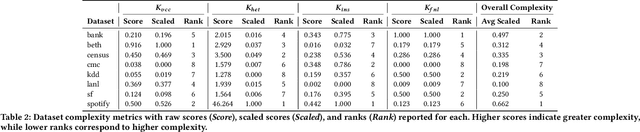
Anomaly detection is critical in domains such as cybersecurity and finance, especially when working with large-scale tabular data. Yet, unsupervised anomaly detection -- where no labeled anomalies are available -- remains a significant challenge. Although various deep learning methods have been proposed to model a dataset's joint distribution, real-world tabular data often contain heterogeneous contexts (e.g., different users), making globally rare events normal under certain contexts. Consequently, relying on a single global distribution can overlook these contextual nuances, degrading detection performance. In this paper, we present a context-conditional anomaly detection framework tailored for tabular datasets. Our approach automatically identifies context features and models the conditional data distribution using a simple deep autoencoder. Extensive experiments on multiple tabular benchmark datasets demonstrate that our method outperforms state-of-the-art approaches, underscoring the importance of context in accurately distinguishing anomalous from normal instances.
SIEVE: Effective Filtered Vector Search with Collection of Indexes
Jul 16, 2025Many real-world tasks such as recommending videos with the kids tag can be reduced to finding most similar vectors associated with hard predicates. This task, filtered vector search, is challenging as prior state-of-the-art graph-based (unfiltered) similarity search techniques quickly degenerate when hard constraints are considered. That is, effective graph-based filtered similarity search relies on sufficient connectivity for reaching the most similar items within just a few hops. To consider predicates, recent works propose modifying graph traversal to visit only the items that may satisfy predicates. However, they fail to offer the just-a-few-hops property for a wide range of predicates: they must restrict predicates significantly or lose efficiency if only a small fraction of items satisfy predicates. We propose an opposite approach: instead of constraining traversal, we build many indexes each serving different predicate forms. For effective construction, we devise a three-dimensional analytical model capturing relationships among index size, search time, and recall, with which we follow a workload-aware approach to pack as many useful indexes as possible into a collection. At query time, the analytical model is employed yet again to discern the one that offers the fastest search at a given recall. We show superior performance and support on datasets with varying selectivities and forms: our approach achieves up to 8.06x speedup while having as low as 1% build time versus other indexes, with less than 2.15x memory of a standard HNSW graph and modest knowledge of past workloads.
Qwen2.5-VL Technical Report
Feb 19, 2025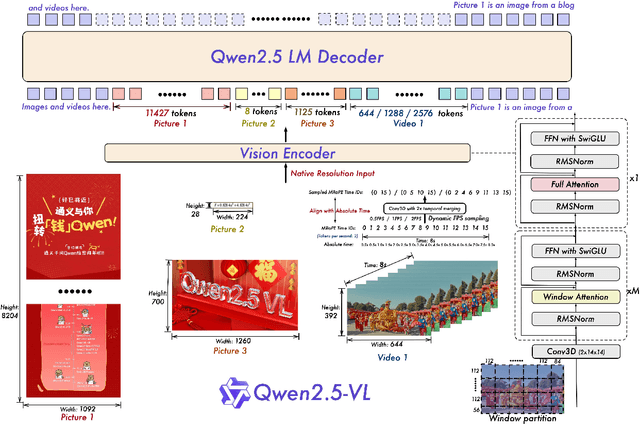
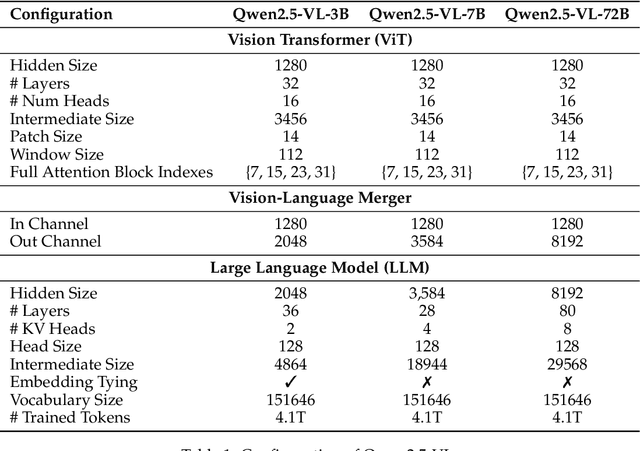
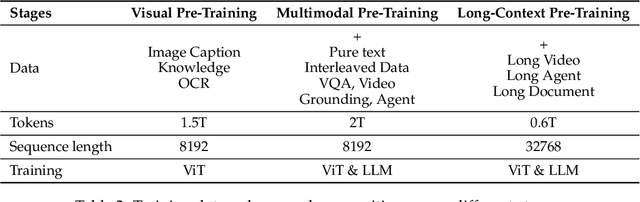
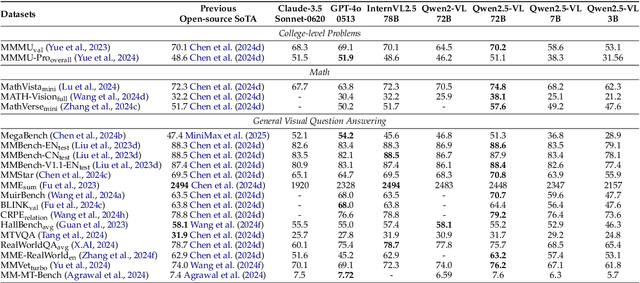
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
SteLLA: A Structured Grading System Using LLMs with RAG
Jan 15, 2025Large Language Models (LLMs) have shown strong general capabilities in many applications. However, how to make them reliable tools for some specific tasks such as automated short answer grading (ASAG) remains a challenge. We present SteLLA (Structured Grading System Using LLMs with RAG) in which a) Retrieval Augmented Generation (RAG) approach is used to empower LLMs specifically on the ASAG task by extracting structured information from the highly relevant and reliable external knowledge based on the instructor-provided reference answer and rubric, b) an LLM performs a structured and question-answering-based evaluation of student answers to provide analytical grades and feedback. A real-world dataset that contains students' answers in an exam was collected from a college-level Biology course. Experiments show that our proposed system can achieve substantial agreement with the human grader while providing break-down grades and feedback on all the knowledge points examined in the problem. A qualitative and error analysis of the feedback generated by GPT4 shows that GPT4 is good at capturing facts while may be prone to inferring too much implication from the given text in the grading task which provides insights into the usage of LLMs in the ASAG system.
TreeMatch: A Fully Unsupervised WSD System Using Dependency Knowledge on a Specific Domain
Jan 05, 2025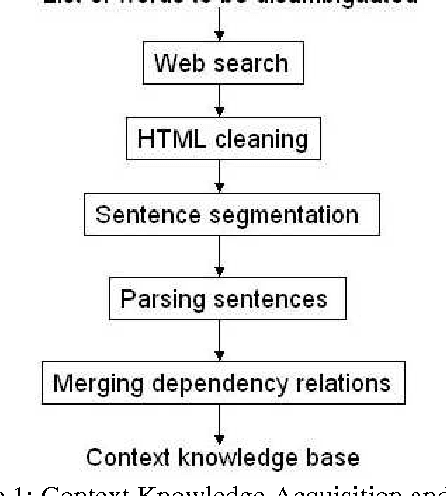
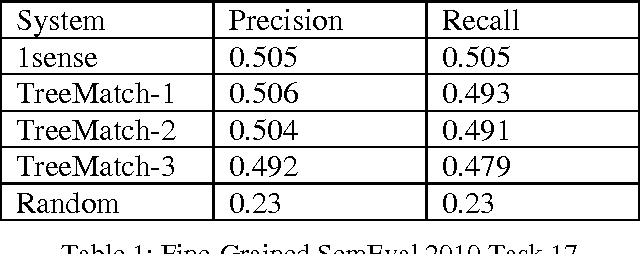
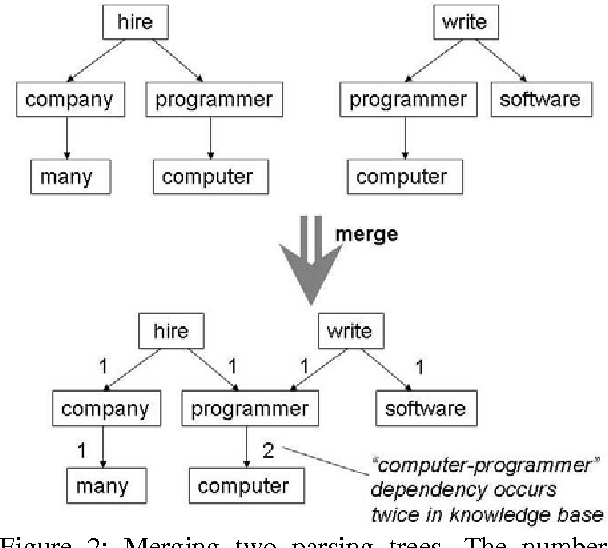
Word sense disambiguation (WSD) is one of the main challenges in Computational Linguistics. TreeMatch is a WSD system originally developed using data from SemEval 2007 Task 7 (Coarse-grained English All-words Task) that has been adapted for use in SemEval 2010 Task 17 (All-words Word Sense Disambiguation on a Specific Domain). The system is based on a fully unsupervised method using dependency knowledge drawn from a domain specific knowledge base that was built for this task. When evaluated on the task, the system precision performs above the Most Frequent Selection baseline.
AToM-Bot: Embodied Fulfillment of Unspoken Human Needs with Affective Theory of Mind
Jun 12, 2024



We propose AToM-Bot, a novel task generation and execution framework for proactive robot-human interaction, which leverages the human mental and physical state inference capabilities of the Vision Language Model (VLM) prompted by the Affective Theory of Mind (AToM). Without requiring explicit commands by humans, AToM-Bot proactively generates and follows feasible tasks to improve general human well-being. When around humans, AToM-Bot first detects current human needs based on inferred human states and observations of the surrounding environment. It then generates tasks to fulfill these needs, taking into account its embodied constraints. We designed 16 daily life scenarios spanning 4 common scenes and tasked the same visual stimulus to 59 human subjects and our robot. We used the similarity between human open-ended answers and robot output, and the human satisfaction scores to metric robot performance. AToM-Bot received high human evaluations in need detection (6.42/7, 91.7%), embodied solution (6.15/7, 87.8%) and task execution (6.17/7, 88.1%). We show that AToM-Bot excels in generating and executing feasible plans to fulfill unspoken human needs. Videos and code are available at https://affective-tom-bot.github.io.
Alignment is not sufficient to prevent large language models from generating harmful information: A psychoanalytic perspective
Nov 14, 2023Large Language Models (LLMs) are central to a multitude of applications but struggle with significant risks, notably in generating harmful content and biases. Drawing an analogy to the human psyche's conflict between evolutionary survival instincts and societal norm adherence elucidated in Freud's psychoanalysis theory, we argue that LLMs suffer a similar fundamental conflict, arising between their inherent desire for syntactic and semantic continuity, established during the pre-training phase, and the post-training alignment with human values. This conflict renders LLMs vulnerable to adversarial attacks, wherein intensifying the models' desire for continuity can circumvent alignment efforts, resulting in the generation of harmful information. Through a series of experiments, we first validated the existence of the desire for continuity in LLMs, and further devised a straightforward yet powerful technique, such as incomplete sentences, negative priming, and cognitive dissonance scenarios, to demonstrate that even advanced LLMs struggle to prevent the generation of harmful information. In summary, our study uncovers the root of LLMs' vulnerabilities to adversarial attacks, hereby questioning the efficacy of solely relying on sophisticated alignment methods, and further advocates for a new training idea that integrates modal concepts alongside traditional amodal concepts, aiming to endow LLMs with a more nuanced understanding of real-world contexts and ethical considerations.
Dual Adversarial Alignment for Realistic Support-Query Shift Few-shot Learning
Sep 05, 2023Support-query shift few-shot learning aims to classify unseen examples (query set) to labeled data (support set) based on the learned embedding in a low-dimensional space under a distribution shift between the support set and the query set. However, in real-world scenarios the shifts are usually unknown and varied, making it difficult to estimate in advance. Therefore, in this paper, we propose a novel but more difficult challenge, RSQS, focusing on Realistic Support-Query Shift few-shot learning. The key feature of RSQS is that the individual samples in a meta-task are subjected to multiple distribution shifts in each meta-task. In addition, we propose a unified adversarial feature alignment method called DUal adversarial ALignment framework (DuaL) to relieve RSQS from two aspects, i.e., inter-domain bias and intra-domain variance. On the one hand, for the inter-domain bias, we corrupt the original data in advance and use the synthesized perturbed inputs to train the repairer network by minimizing distance in the feature level. On the other hand, for intra-domain variance, we proposed a generator network to synthesize hard, i.e., less similar, examples from the support set in a self-supervised manner and introduce regularized optimal transportation to derive a smooth optimal transportation plan. Lastly, a benchmark of RSQS is built with several state-of-the-art baselines among three datasets (CIFAR100, mini-ImageNet, and Tiered-Imagenet). Experiment results show that DuaL significantly outperforms the state-of-the-art methods in our benchmark.
Object Goal Navigation with End-to-End Self-Supervision
Dec 09, 2022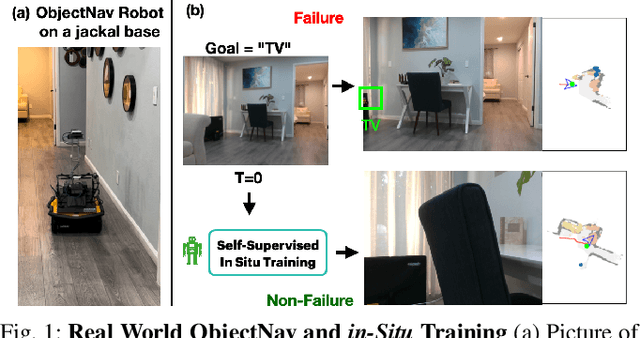
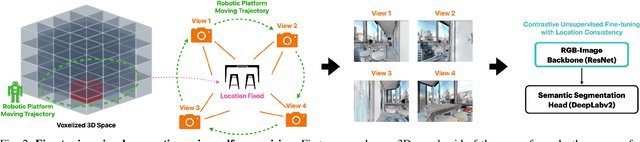
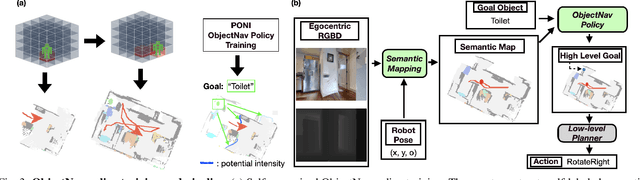
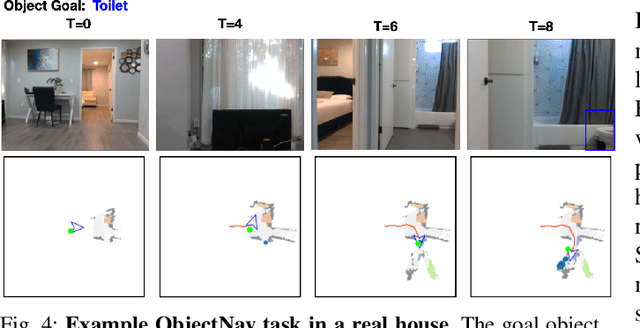
A household robot should be able to navigate to target locations without requiring users to first annotate everything in their home. Current approaches to this object navigation challenge do not test on real robots and rely on expensive semantically labeled 3D meshes. In this work, our aim is an agent that builds self-supervised models of the world via exploration, the same as a child might. We propose an end-to-end self-supervised embodied agent that leverages exploration to train a semantic segmentation model of 3D objects, and uses those representations to learn an object navigation policy purely from self-labeled 3D meshes. The key insight is that embodied agents can leverage location consistency as a supervision signal - collecting images from different views/angles and applying contrastive learning to fine-tune a semantic segmentation model. In our experiments, we observe that our framework performs better than other self-supervised baselines and competitively with supervised baselines, in both simulation and when deployed in real houses.
Generalized Category Discovery with Decoupled Prototypical Network
Nov 28, 2022Generalized Category Discovery (GCD) aims to recognize both known and novel categories from a set of unlabeled data, based on another dataset labeled with only known categories. Without considering differences between known and novel categories, current methods learn about them in a coupled manner, which can hurt model's generalization and discriminative ability. Furthermore, the coupled training approach prevents these models transferring category-specific knowledge explicitly from labeled data to unlabeled data, which can lose high-level semantic information and impair model performance. To mitigate above limitations, we present a novel model called Decoupled Prototypical Network (DPN). By formulating a bipartite matching problem for category prototypes, DPN can not only decouple known and novel categories to achieve different training targets effectively, but also align known categories in labeled and unlabeled data to transfer category-specific knowledge explicitly and capture high-level semantics. Furthermore, DPN can learn more discriminative features for both known and novel categories through our proposed Semantic-aware Prototypical Learning (SPL). Besides capturing meaningful semantic information, SPL can also alleviate the noise of hard pseudo labels through semantic-weighted soft assignment. Extensive experiments show that DPN outperforms state-of-the-art models by a large margin on all evaluation metrics across multiple benchmark datasets. Code and data are available at https://github.com/Lackel/DPN.