 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Goal Navigation with End-to-End Self-Supervision
Paper and Code
Dec 09, 2022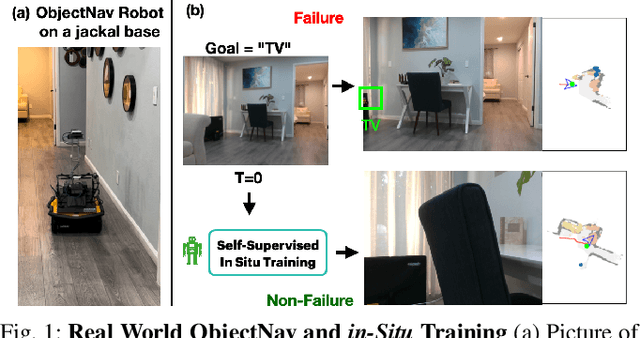
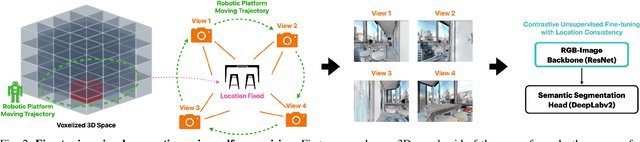
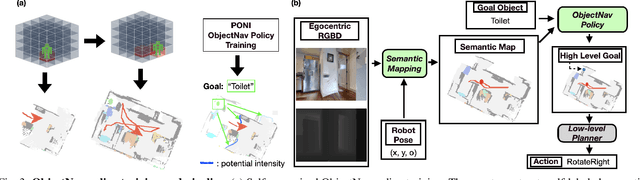
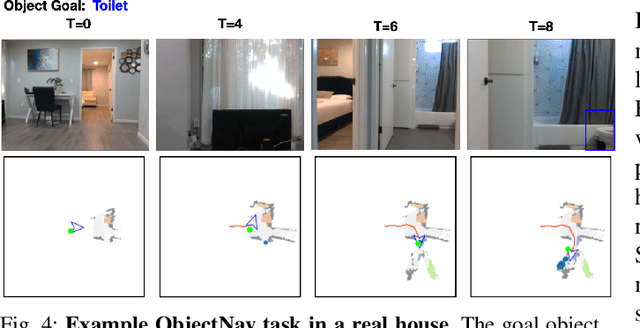
A household robot should be able to navigate to target locations without requiring users to first annotate everything in their home. Current approaches to this object navigation challenge do not test on real robots and rely on expensive semantically labeled 3D meshes. In this work, our aim is an agent that builds self-supervised models of the world via exploration, the same as a child might. We propose an end-to-end self-supervised embodied agent that leverages exploration to train a semantic segmentation model of 3D objects, and uses those representations to learn an object navigation policy purely from self-labeled 3D meshes. The key insight is that embodied agents can leverage location consistency as a supervision signal - collecting images from different views/angles and applying contrastive learning to fine-tune a semantic segmentation model. In our experiments, we observe that our framework performs better than other self-supervised baselines and competitively with supervised baselines, in both simulation and when deployed in real houses.