 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LRP Diverges from Leave-One-Out in Transformers
Oct 21, 2025


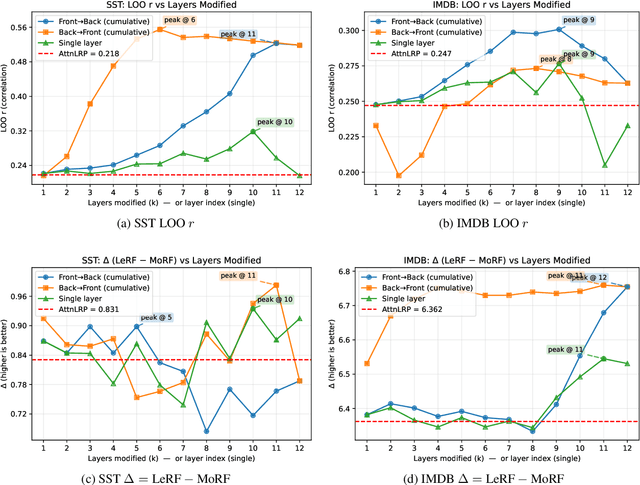
Leave-One-Out (LOO) provides an intuitive measure of feature importance but is computationally prohibitive. While Layer-Wise Relevance Propagation (LRP) offers a potentially efficient alternative, its axiomatic soundness in modern Transformers remains largely under-examined. In this work, we first show that the bilinear propagation rules used in recent advances of AttnLRP violate the implementation invariance axiom. We prove this analytically and confirm it empirically in linear attention layers. Second, we also revisit CP-LRP as a diagnostic baseline and find that bypassing relevance propagation through the softmax layer -- backpropagating relevance only through the value matrices -- significantly improves alignment with LOO, particularly in middle-to-late Transformer layers. Overall, our results suggest that (i) bilinear factorization sensitivity and (ii) softmax propagation error potentially jointly undermine LRP's ability to approximate LOO in Transformers.
PhiNet v2: A Mask-Free Brain-Inspired Vision Foundation Model from Video
May 16, 2025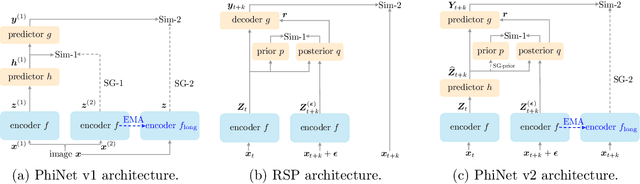

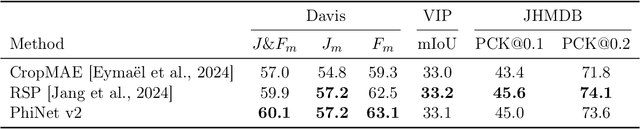

Recent advances in self-supervised learning (SSL) have revolutionized computer vision through innovative architectures and learning objectives, yet they have not fully leveraged insights from biological visual processing systems. Recently, a brain-inspired SSL model named PhiNet was proposed; it is based on a ResNet backbone and operates on static image inputs with strong augmentation. In this paper, we introduce PhiNet v2, a novel Transformer-based architecture that processes temporal visual input (that is, sequences of images) without relying on strong augmentation. Our model leverages variational inference to learn robust visual representations from continuous input streams, similar to human visual processing. Through extensive experimentation, we demonstrate that PhiNet v2 achieves competitive performance compared to state-of-the-art vision foundation models, while maintaining the ability to learn from sequential input without strong data augmentation. This work represents a significant step toward more biologically plausible computer vision systems that process visual information in a manner more closely aligned with human cognitive processes.
Efficient Model Editing with Task Vector Bases: A Theoretical Framework and Scalable Approach
Feb 03, 2025

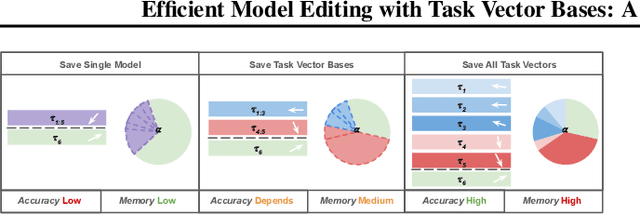

Task vectors, which are derived from the difference between pre-trained and fine-tuned model weights, enable flexible task adaptation and model merging through arithmetic operations such as addition and negation. However, existing approaches often rely on heuristics with limited theoretical support, often leading to performance gaps comparing to direct task fine tuning. Meanwhile, although it is easy to manipulate saved task vectors with arithmetic for different purposes, such compositional flexibility demands high memory usage, especially when dealing with a huge number of tasks, limiting scalability. This work addresses these issues with a theoretically grounded framework that explains task vector arithmetic and introduces the task vector bases framework. Building upon existing task arithmetic literature, our method significantly reduces the memory cost for downstream arithmetic with little effort, while achieving competitive performance and maintaining compositional advantage, providing a practical solution for large-scale task arithmetic.
On Verbalized Confidence Scores for LLMs
Dec 19, 2024
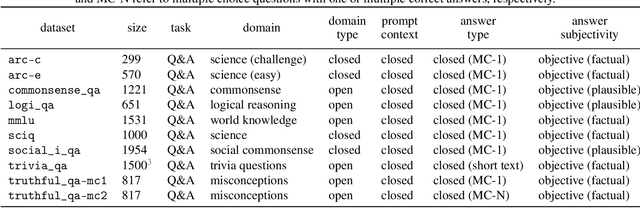

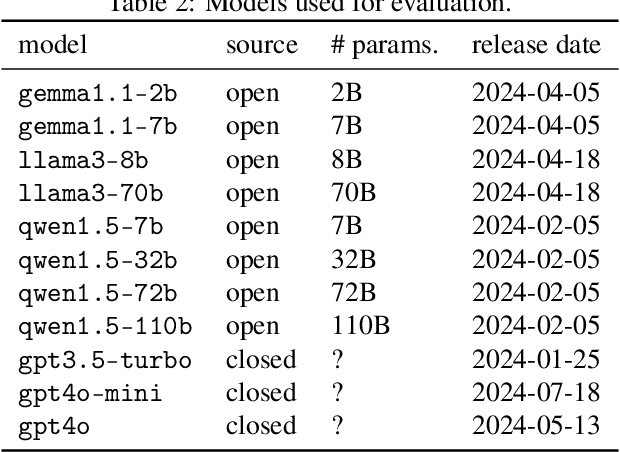
The rise of large language models (LLMs) and their tight integration into our daily life make it essential to dedicate efforts towards their trustworthiness. Uncertainty quantification for LLMs can establish more human trust into their responses, but also allows LLM agents to make more informed decisions based on each other's uncertainty. To estimate the uncertainty in a response, internal token logits, task-specific proxy models, or sampling of multiple responses are commonly used. This work focuses on asking the LLM itself to verbalize its uncertainty with a confidence score as part of its output tokens, which is a promising way for prompt- and model-agnostic uncertainty quantification with low overhead. Using an extensive benchmark, we assess the reliability of verbalized confidence scores with respect to different datasets, models, and prompt methods. Our results reveal that the reliability of these scores strongly depends on how the model is asked, but also that it is possible to extract well-calibrated confidence scores with certain prompt methods. We argue that verbalized confidence scores can become a simple but effective and versatile uncertainty quantification method in the future. Our code is available at https://github.com/danielyxyang/llm-verbalized-uq .
KPConvX: Modernizing Kernel Point Convolution with Kernel Attention
May 21, 2024



In the field of deep point cloud understanding, KPConv is a unique architecture that uses kernel points to locate convolutional weights in space, instead of relying on Multi-Layer Perceptron (MLP) encodings. While it initially achieved success, it has since been surpassed by recent MLP networks that employ updated designs and training strategies. Building upon the kernel point principle, we present two novel designs: KPConvD (depthwise KPConv), a lighter design that enables the use of deeper architectures, and KPConvX, an innovative design that scales the depthwise convolutional weights of KPConvD with kernel attention values. Using KPConvX with a modern architecture and training strategy, we are able to outperform current state-of-the-art approaches on the ScanObjectNN, Scannetv2, and S3DIS datasets. We validate our design choices through ablation studies and release our code and models.
Efficient Non-Parametric Uncertainty Quantification for Black-Box Large Language Models and Decision Planning
Feb 01, 2024Step-by-step decision planning with large language models (LLMs) is gaining attention in AI agent development. This paper focuses on decision planning with uncertainty estimation to address the hallucination problem in language models. Existing approaches are either white-box or computationally demanding, limiting use of black-box proprietary LLMs within budgets. The paper's first contribution is a non-parametric uncertainty quantification method for LLMs, efficiently estimating point-wise dependencies between input-decision on the fly with a single inference, without access to token logits. This estimator informs the statistical interpretation of decision trustworthiness. The second contribution outlines a systematic design for a decision-making agent, generating actions like ``turn on the bathroom light'' based on user prompts such as ``take a bath''. Users will be asked to provide preferences when more than one action has high estimated point-wise dependencies. In conclusion, our uncertainty estimation and decision-making agent design offer a cost-efficient approach for AI agent development.
An Empirical Study of Simplicial Representation Learning with Wasserstein Distance
Oct 16, 2023In this paper, we delve into the problem of simplicial representation learning utilizing the 1-Wasserstein distance on a tree structure (a.k.a., Tree-Wasserstein distance (TWD)), where TWD is defined as the L1 distance between two tree-embedded vectors. Specifically, we consider a framework for simplicial representation estimation employing a self-supervised learning approach based on SimCLR with a negative TWD as a similarity measure. In SimCLR, the cosine similarity with real-vector embeddings is often utilized; however, it has not been well studied utilizing L1-based measures with simplicial embeddings. A key challenge is that training the L1 distance is numerically challenging and often yields unsatisfactory outcomes, and there are numerous choices for probability models. Thus, this study empirically investigates a strategy for optimizing self-supervised learning with TWD and find a stable training procedure. More specifically, we evaluate the combination of two types of TWD (total variation and ClusterTree) and several simplicial models including the softmax function, the ArcFace probability model, and simplicial embedding. Moreover, we propose a simple yet effective Jeffrey divergence-based regularization method to stabilize the optimization. Through empirical experiments on STL10, CIFAR10, CIFAR100, and SVHN, we first found that the simple combination of softmax function and TWD can obtain significantly lower results than the standard SimCLR (non-simplicial model and cosine similarity). We found that the model performance depends on the combination of TWD and the simplicial model, and the Jeffrey divergence regularization usually helps model training. Finally, we inferred that the appropriate choice of combination of TWD and simplicial models outperformed cosine similarity based representation learning.
Multimodal Large Language Model for Visual Navigation
Oct 12, 2023Recent efforts to enable visual navigation using large language models have mainly focused on developing complex prompt systems. These systems incorporate instructions, observations, and history into massive text prompts, which are then combined with pre-trained large language models to facilitate visual navigation. In contrast, our approach aims to fine-tune large language models for visual navigation without extensive prompt engineering. Our design involves a simple text prompt, current observations, and a history collector model that gathers information from previous observations as input. For output, our design provides a probability distribution of possible actions that the agent can take during navigation. We train our model using human demonstrations and collision signals from the Habitat-Matterport 3D Dataset (HM3D). Experimental results demonstrate that our method outperforms state-of-the-art behavior cloning methods and effectively reduces collision rates.
Human Following in Mobile Platforms with Person Re-Identification
Sep 21, 2023



Human following is a crucial feature of human-robot interaction, yet it poses numerous challenges to mobile agents in real-world scenarios. Some major hurdles are that the target person may be in a crowd, obstructed by others, or facing away from the agent. To tackle these challenges, we present a novel person re-identification module composed of three parts: a 360-degree visual registration, a neural-based person re-identification using human faces and torsos, and a motion tracker that records and predicts the target person's future position. Our human-following system also addresses other challenges, including identifying fast-moving targets with low latency, searching for targets that move out of the camera's sight, collision avoidance, and adaptively choosing different following mechanisms based on the distance between the target person and the mobile agent. Extensive experiments show that our proposed person re-identification module significantly enhances the human-following feature compared to other baseline variants.
Object Goal Navigation with End-to-End Self-Supervision
Dec 09, 2022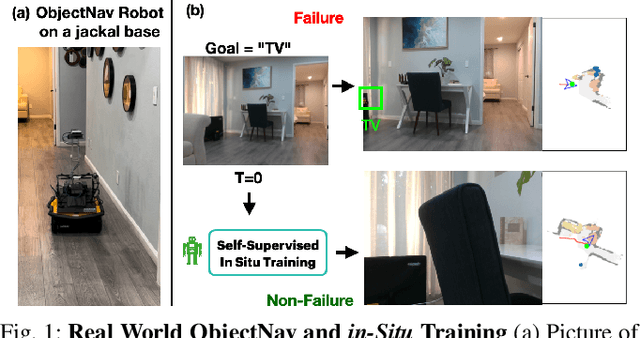
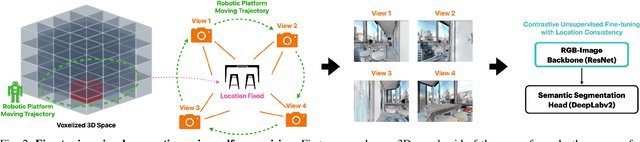
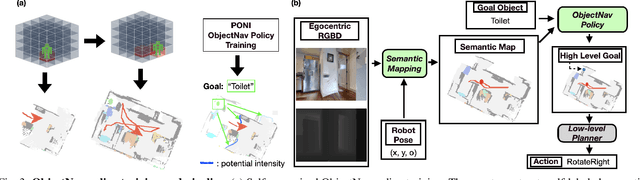
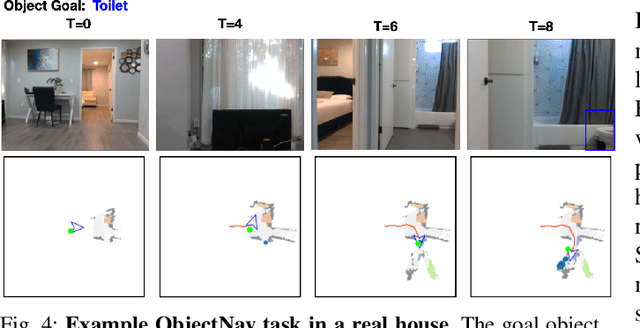
A household robot should be able to navigate to target locations without requiring users to first annotate everything in their home. Current approaches to this object navigation challenge do not test on real robots and rely on expensive semantically labeled 3D meshes. In this work, our aim is an agent that builds self-supervised models of the world via exploration, the same as a child might. We propose an end-to-end self-supervised embodied agent that leverages exploration to train a semantic segmentation model of 3D objects, and uses those representations to learn an object navigation policy purely from self-labeled 3D meshes. The key insight is that embodied agents can leverage location consistency as a supervision signal - collecting images from different views/angles and applying contrastive learning to fine-tune a semantic segmentation model. In our experiments, we observe that our framework performs better than other self-supervised baselines and competitively with supervised baselines, in both simulation and when deployed in real houses.