 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks
Aug 26, 2025Empirical scaling laws have driven the evolution of large language models (LLMs), yet their coefficients shift whenever the model architecture or data pipeline changes. Mixture-of-Experts (MoE) models, now standard in state-of-the-art systems, introduce a new sparsity dimension that current dense-model frontiers overlook. We investigate how MoE sparsity influences two distinct capability regimes: memorization and reasoning. We train families of MoE Transformers that systematically vary total parameters, active parameters, and top-$k$ routing while holding the compute budget fixed. For every model we record pre-training loss, downstream task loss, and task accuracy, allowing us to separate the train-test generalization gap from the loss-accuracy gap. Memorization benchmarks improve monotonically with total parameters, mirroring training loss. By contrast, reasoning performance saturates and can even regress despite continued gains in both total parameters and training loss. Altering top-$k$ alone has little effect when active parameters are constant, and classic hyperparameters such as learning rate and initialization modulate the generalization gap in the same direction as sparsity. Neither post-training reinforcement learning (GRPO) nor extra test-time compute rescues the reasoning deficit of overly sparse models. Our model checkpoints, code and logs are open-source at https://github.com/rioyokotalab/optimal-sparsity.
PhiNet v2: A Mask-Free Brain-Inspired Vision Foundation Model from Video
May 16, 2025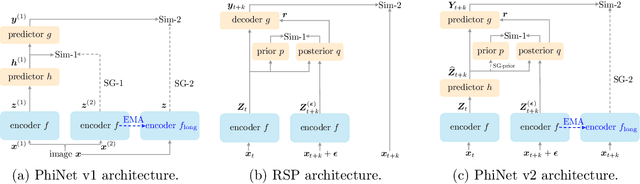

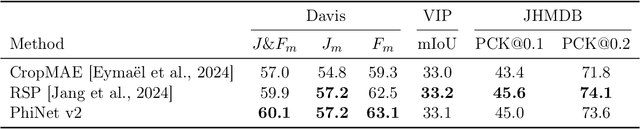

Recent advances in self-supervised learning (SSL) have revolutionized computer vision through innovative architectures and learning objectives, yet they have not fully leveraged insights from biological visual processing systems. Recently, a brain-inspired SSL model named PhiNet was proposed; it is based on a ResNet backbone and operates on static image inputs with strong augmentation. In this paper, we introduce PhiNet v2, a novel Transformer-based architecture that processes temporal visual input (that is, sequences of images) without relying on strong augmentation. Our model leverages variational inference to learn robust visual representations from continuous input streams, similar to human visual processing. Through extensive experimentation, we demonstrate that PhiNet v2 achieves competitive performance compared to state-of-the-art vision foundation models, while maintaining the ability to learn from sequential input without strong data augmentation. This work represents a significant step toward more biologically plausible computer vision systems that process visual information in a manner more closely aligned with human cognitive processes.
Lion Cub: Minimizing Communication Overhead in Distributed Lion
Nov 25, 2024Communication overhead is a key challenge in distributed deep learning, especially on slower Ethernet interconnects, and given current hardware trends, communication is likely to become a major bottleneck. While gradient compression techniques have been explored for SGD and Adam, the Lion optimizer has the distinct advantage that its update vectors are the output of a sign operation, enabling straightforward quantization. However, simply compressing updates for communication and using techniques like majority voting fails to lead to end-to-end speedups due to inefficient communication algorithms and reduced convergence. We analyze three factors critical to distributed learning with Lion: optimizing communication methods, identifying effective quantization methods, and assessing the necessity of momentum synchronization. Our findings show that quantization techniques adapted to Lion and selective momentum synchronization can significantly reduce communication costs while maintaining convergence. We combine these into Lion Cub, which enables up to 5x speedups in end-to-end training compared to Lion. This highlights Lion's potential as a communication-efficient solution for distributed training.
Local Loss Optimization in the Infinite Width: Stable Parameterization of Predictive Coding Networks and Target Propagation
Nov 04, 2024Local learning, which trains a network through layer-wise local targets and losses, has been studied as an alternative to backpropagation (BP) in neural computation. However, its algorithms often become more complex or require additional hyperparameters because of the locality, making it challenging to identify desirable settings in which the algorithm progresses in a stable manner. To provide theoretical and quantitative insights, we introduce the maximal update parameterization ($\mu$P) in the infinite-width limit for two representative designs of local targets: predictive coding (PC) and target propagation (TP). We verified that $\mu$P enables hyperparameter transfer across models of different widths. Furthermore, our analysis revealed unique and intriguing properties of $\mu$P that are not present in conventional BP. By analyzing deep linear networks, we found that PC's gradients interpolate between first-order and Gauss-Newton-like gradients, depending on the parameterization. We demonstrate that, in specific standard settings, PC in the infinite-width limit behaves more similarly to the first-order gradient. For TP, even with the standard scaling of the last layer, which differs from classical $\mu$P, its local loss optimization favors the feature learning regime over the kernel regime.
PhiNets: Brain-inspired Non-contrastive Learning Based on Temporal Prediction Hypothesis
May 23, 2024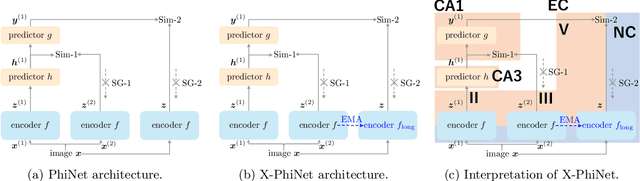

SimSiam is a prominent self-supervised learning method that achieves impressive results in various vision tasks under static environments. However, it has two critical issues: high sensitivity to hyperparameters, especially weight decay, and unsatisfactory performance in online and continual learning, where neuroscientists believe that powerful memory functions are necessary, as in brains. In this paper, we propose PhiNet, inspired by a hippocampal model based on the temporal prediction hypothesis. Unlike SimSiam, which aligns two augmented views of the original image, PhiNet integrates an additional predictor block that estimates the original image representation to imitate the CA1 region in the hippocampus. Moreover, we model the neocortex inspired by the Complementary Learning Systems theory with a momentum encoder block as a slow learner, which works as long-term memory. We demonstrate through analysing the learning dynamics that PhiNet benefits from the additional predictor to prevent the complete collapse of learned representations, a notorious challenge in non-contrastive learning. This dynamics analysis may partially corroborate why this hippocampal model is biologically plausible. Experimental results demonstrate that PhiNet is more robust to weight decay and performs better than SimSiam in memory-intensive tasks like online and continual learning.
On the Parameterization of Second-Order Optimization Effective Towards the Infinite Width
Dec 19, 2023Second-order optimization has been developed to accelerate the training of deep neural networks and it is being applied to increasingly larger-scale models. In this study, towards training on further larger scales, we identify a specific parameterization for second-order optimization that promotes feature learning in a stable manner even if the network width increases significantly. Inspired by a maximal update parameterization, we consider a one-step update of the gradient and reveal the appropriate scales of hyperparameters including random initialization, learning rates, and damping terms. Our approach covers two major second-order optimization algorithms, K-FAC and Shampoo, and we demonstrate that our parameterization achieves higher generalization performance in feature learning. In particular, it enables us to transfer the hyperparameters across models with different widths.
ASDL: A Unified Interface for Gradient Preconditioning in PyTorch
May 08, 2023



Gradient preconditioning is a key technique to integrate the second-order information into gradients for improving and extending gradient-based learning algorithms. In deep learning, stochasticity, nonconvexity, and high dimensionality lead to a wide variety of gradient preconditioning methods, with implementation complexity and inconsistent performance and feasibility. We propose the Automatic Second-order Differentiation Library (ASDL), an extension library for PyTorch, which offers various implementations and a plug-and-play unified interface for gradient preconditioning. ASDL enables the study and structured comparison of a range of gradient preconditioning methods.