 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning in Modern Hopfield Networks with an Application to Diffusion Models
May 28, 2026Generative models, including diffusion models, are increasingly used as foundation models and adapted through sequential fine-tuning, making continual learning an essential problem setting. However, continual learning in such generative models remains poorly understood: after a task change, what aspects of the learned distribution are most easily lost, and what replay samples should be prioritized? We address these questions through the modern Hopfield energy. Recent links between modern Hopfield networks (MHNs) and diffusion models allow analyses in MHNs to be transferred to diffusion models. We introduce intrinsic forgetting as an increase in Hopfield energy after the task change. In tractable settings in an MHN, we prove that high-energy, outlier-like samples undergo a larger energy increase than cluster-like samples, implying that samples located in sharp, isolated basins are more forgettable. We further analyze memory replay and show that replay is particularly effective for high-energy samples, enabling an energy-based selection of replay samples. We validate these predictions in experiments on MHNs and two diffusion models under continual-learning settings: Stable Diffusion and a pixel-space DDPM. In these diffusion models, Hopfield energy tracks reconstruction-based forgetting, and replay experiments reveal energy-dependent mitigation of forgetting that is consistent with the MHN analysis.
A Unified Framework for Critical Scaling of Inverse Temperature in Self-Attention
May 12, 2026Length-dependent logit rescaling is widely used to stabilize long-context self-attention, but existing analyses and methods suggest conflicting inverse-temperature laws for the context length $n$, ranging from $(\log n)^{1/2}$ to $\log n$ and $(\log n)^2$. We provide a general theory showing that the desirable scale is determined by the gap-counting function $N_n$ of each attention row. Counting how many competitors lie within each gap from the maximum, we define an upper-tail accumulation scale and prove that it gives the critical inverse-temperature scale for softmax concentration: below this scale, the top competitors remain unseparated, whereas above it, the attention entropy collapses. This framework unifies prior scaling laws as different $N_n$ and yields a direct diagnostic for attention-score families, from idealized theoretical models to more practical transformers.
The Impact of Anisotropic Covariance Structure on the Training Dynamics and Generalization Error of Linear Networks
Jan 11, 2026The success of deep neural networks largely depends on the statistical structure of the training data. While learning dynamics and generalization on isotropic data are well-established, the impact of pronounced anisotropy on these crucial aspects is not yet fully understood. We examine the impact of data anisotropy, represented by a spiked covariance structure, a canonical yet tractable model, on the learning dynamics and generalization error of a two-layer linear network in a linear regression setting. Our analysis reveals that the learning dynamics proceed in two distinct phases, governed initially by the input-output correlation and subsequently by other principal directions of the data structure. Furthermore, we derive an analytical expression for the generalization error, quantifying how the alignment of the spike structure of the data with the learning task improves performance. Our findings offer deep theoretical insights into how data anisotropy shapes the learning trajectory and final performance, providing a foundation for understanding complex interactions in more advanced network architectures.
Recurrent Self-Attention Dynamics: An Energy-Agnostic Perspective from Jacobians
May 26, 2025



The theoretical understanding of self-attention (SA) has been steadily progressing. A prominent line of work studies a class of SA layers that admit an energy function decreased by state updates. While it provides valuable insights into inherent biases in signal propagation, it often relies on idealized assumptions or additional constraints not necessarily present in standard SA. Thus, to broaden our understanding, this work aims to relax these energy constraints and provide an energy-agnostic characterization of inference dynamics by dynamical systems analysis. In more detail, we first consider relaxing the symmetry and single-head constraints traditionally required in energy-based formulations. Next, to investigate more general SA architectures capable of oscillatory dynamics without necessarily admitting an energy function, we analyze the Jacobian matrix of the state. We reveal that normalization layers effectively normalize the Jacobian's complex eigenvalues, forcing the dynamics close to a critical state. This significantly enhances inference performance. Furthermore, we utilize the Jacobian perspective to develop regularization methods for training and a pseudo-energy for monitoring inference dynamics.
Local Loss Optimization in the Infinite Width: Stable Parameterization of Predictive Coding Networks and Target Propagation
Nov 04, 2024Local learning, which trains a network through layer-wise local targets and losses, has been studied as an alternative to backpropagation (BP) in neural computation. However, its algorithms often become more complex or require additional hyperparameters because of the locality, making it challenging to identify desirable settings in which the algorithm progresses in a stable manner. To provide theoretical and quantitative insights, we introduce the maximal update parameterization ($\mu$P) in the infinite-width limit for two representative designs of local targets: predictive coding (PC) and target propagation (TP). We verified that $\mu$P enables hyperparameter transfer across models of different widths. Furthermore, our analysis revealed unique and intriguing properties of $\mu$P that are not present in conventional BP. By analyzing deep linear networks, we found that PC's gradients interpolate between first-order and Gauss-Newton-like gradients, depending on the parameterization. We demonstrate that, in specific standard settings, PC in the infinite-width limit behaves more similarly to the first-order gradient. For TP, even with the standard scaling of the last layer, which differs from classical $\mu$P, its local loss optimization favors the feature learning regime over the kernel regime.
Optimal Layer Selection for Latent Data Augmentation
Aug 24, 2024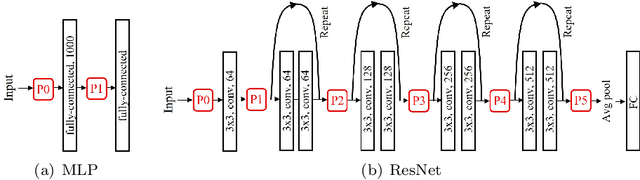
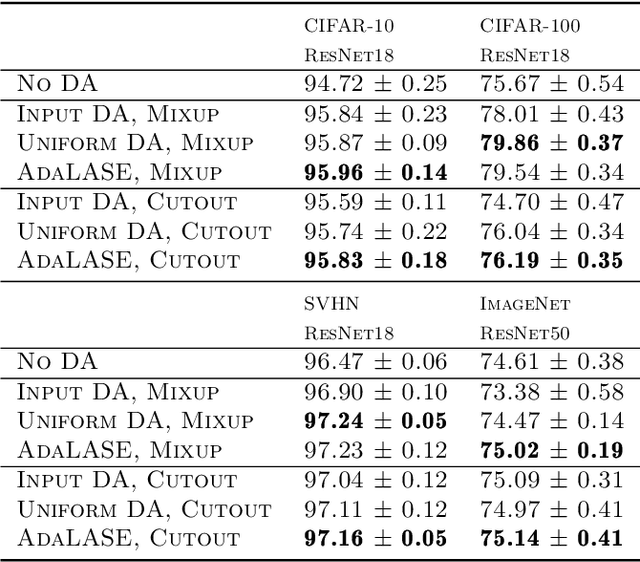

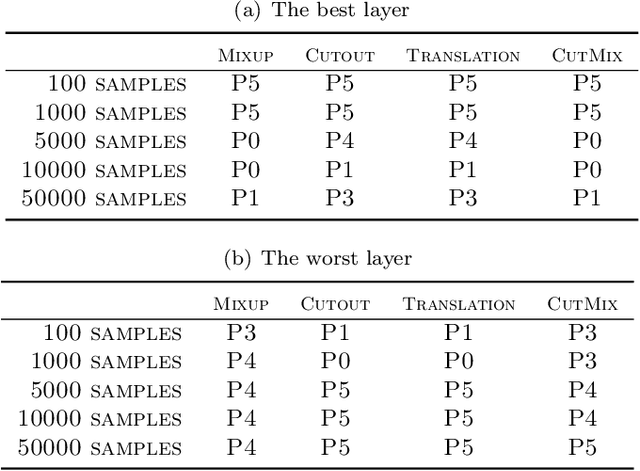
While data augmentation (DA) is generally applied to input data, several studies have reported that applying DA to hidden layers in neural networks, i.e., feature augmentation, can improve performance. However, in previous studies, the layers to which DA is applied have not been carefully considered, often being applied randomly and uniformly or only to a specific layer, leaving room for arbitrariness. Thus, in this study, we investigated the trends of suitable layers for applying DA in various experimental configurations, e.g., training from scratch, transfer learning, various dataset settings, and different models. In addition, to adjust the suitable layers for DA automatically, we propose the adaptive layer selection (AdaLASE) method, which updates the ratio to perform DA for each layer based on the gradient descent method during training. The experimental results obtained on several image classification datasets indicate that the proposed AdaLASE method altered the ratio as expected and achieved high overall test accuracy.
Hierarchical Associative Memory, Parallelized MLP-Mixer, and Symmetry Breaking
Jun 18, 2024Transformers have established themselves as the leading neural network model in natural language processing and are increasingly foundational in various domains. In vision, the MLP-Mixer model has demonstrated competitive performance, suggesting that attention mechanisms might not be indispensable. Inspired by this, recent research has explored replacing attention modules with other mechanisms, including those described by MetaFormers. However, the theoretical framework for these models remains underdeveloped. This paper proposes a novel perspective by integrating Krotov's hierarchical associative memory with MetaFormers, enabling a comprehensive representation of the entire Transformer block, encompassing token-/channel-mixing modules, layer normalization, and skip connections, as a single Hopfield network. This approach yields a parallelized MLP-Mixer derived from a three-layer Hopfield network, which naturally incorporates symmetric token-/channel-mixing modules and layer normalization. Empirical studies reveal that symmetric interaction matrices in the model hinder performance in image recognition tasks. Introducing symmetry-breaking effects transitions the performance of the symmetric parallelized MLP-Mixer to that of the vanilla MLP-Mixer. This indicates that during standard training, weight matrices of the vanilla MLP-Mixer spontaneously acquire a symmetry-breaking configuration, enhancing their effectiveness. These findings offer insights into the intrinsic properties of Transformers and MLP-Mixers and their theoretical underpinnings, providing a robust framework for future model design and optimization.
Self-attention Networks Localize When QK-eigenspectrum Concentrates
Feb 03, 2024



The self-attention mechanism prevails in modern machine learning. It has an interesting functionality of adaptively selecting tokens from an input sequence by modulating the degree of attention localization, which many researchers speculate is the basis of the powerful model performance but complicates the underlying mechanism of the learning dynamics. In recent years, mainly two arguments have connected attention localization to the model performances. One is the rank collapse, where the embedded tokens by a self-attention block become very similar across different tokens, leading to a less expressive network. The other is the entropy collapse, where the attention probability approaches non-uniform and entails low entropy, making the learning dynamics more likely to be trapped in plateaus. These two failure modes may apparently contradict each other because the rank and entropy collapses are relevant to uniform and non-uniform attention, respectively. To this end, we characterize the notion of attention localization by the eigenspectrum of query-key parameter matrices and reveal that a small eigenspectrum variance leads attention to be localized. Interestingly, the small eigenspectrum variance prevents both rank and entropy collapse, leading to better model expressivity and trainability.
On the Parameterization of Second-Order Optimization Effective Towards the Infinite Width
Dec 19, 2023Second-order optimization has been developed to accelerate the training of deep neural networks and it is being applied to increasingly larger-scale models. In this study, towards training on further larger scales, we identify a specific parameterization for second-order optimization that promotes feature learning in a stable manner even if the network width increases significantly. Inspired by a maximal update parameterization, we consider a one-step update of the gradient and reveal the appropriate scales of hyperparameters including random initialization, learning rates, and damping terms. Our approach covers two major second-order optimization algorithms, K-FAC and Shampoo, and we demonstrate that our parameterization achieves higher generalization performance in feature learning. In particular, it enables us to transfer the hyperparameters across models with different widths.
MLP-Mixer as a Wide and Sparse MLP
Jun 02, 2023Multi-layer perceptron (MLP) is a fundamental component of deep learning that has been extensively employed for various problems. However, recent empirical successes in MLP-based architectures, particularly the progress of the MLP-Mixer, have revealed that there is still hidden potential in improving MLPs to achieve better performance. In this study, we reveal that the MLP-Mixer works effectively as a wide MLP with certain sparse weights. Initially, we clarify that the mixing layer of the Mixer has an effective expression as a wider MLP whose weights are sparse and represented by the Kronecker product. This expression naturally defines a permuted-Kronecker (PK) family, which can be regarded as a general class of mixing layers and is also regarded as an approximation of Monarch matrices. Subsequently, because the PK family effectively constitutes a wide MLP with sparse weights, one can apply the hypothesis proposed by Golubeva, Neyshabur and Gur-Ari (2021) that the prediction performance improves as the width (sparsity) increases when the number of weights is fixed. We empirically verify this hypothesis by maximizing the effective width of the MLP-Mixer, which enables us to determine the appropriate size of the mixing layers quantitatively.