 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Data Scaling Law for Meta Learning via Complexity Minimization
Jun 01, 2026Pre-training has become a fundamental paradigm in modern machine learning, with one of its key empirical benefits being reduced downstream sample complexity as the scale of pre-training data increases. However, existing theoretical frameworks for pre-training do not fully explain this phenomenon. In this paper, we introduce complexity minimization, a novel meta-representation learning framework designed to enable theoretical analysis of this scaling behavior, which learns representations by evaluating the downstream model complexity best suited to each domain and minimizing the worst-case such complexity across source domains. Our end-to-end theoretical analysis, spanning pre-training through downstream regression, shows that this framework provably captures this scaling behavior; in particular, we show that the error rate of few-shot adaptation improves as the amount of meta-training data grows. Empirically, we demonstrate that incorporating complexity regularization into existing meta-learning methods consistently improves downstream sample efficiency.
Provable Target Sample Complexity Improvements as Pre-Trained Models Scale
Feb 04, 2026Pre-trained models have become indispensable for efficiently building models across a broad spectrum of downstream tasks. The advantages of pre-trained models have been highlighted by empirical studies on scaling laws, which demonstrate that larger pre-trained models can significantly reduce the sample complexity of downstream learning. However, existing theoretical investigations of pre-trained models lack the capability to explain this phenomenon. In this paper, we provide a theoretical investigation by introducing a novel framework, caulking, inspired by parameter-efficient fine-tuning (PEFT) methods such as adapter-based fine-tuning, low-rank adaptation, and partial fine-tuning. Our analysis establishes that improved pre-trained models provably decrease the sample complexity of downstream tasks, thereby offering theoretical justification for the empirically observed scaling laws relating pre-trained model size to downstream performance, a relationship not covered by existing results.
Automatic Domain Adaptation by Transformers in In-Context Learning
May 27, 2024Selecting or designing an appropriate domain adaptation algorithm for a given problem remains challenging. This paper presents a Transformer model that can provably approximate and opt for domain adaptation methods for a given dataset in the in-context learning framework, where a foundation model performs new tasks without updating its parameters at test time. Specifically, we prove that Transformers can approximate instance-based and feature-based unsupervised domain adaptation algorithms and automatically select an algorithm suited for a given dataset. Numerical results indicate that in-context learning demonstrates an adaptive domain adaptation surpassing existing methods.
Quantum Circuit $C^*$-algebra Net
Apr 09, 2024



This paper introduces quantum circuit $C^*$-algebra net, which provides a connection between $C^*$-algebra nets proposed in classical machine learning and quantum circuits. Using $C^*$-algebra, a generalization of the space of complex numbers, we can represent quantum gates as weight parameters of a neural network. By introducing additional parameters, we can induce interaction among multiple circuits constructed by quantum gates. This interaction enables the circuits to share information among them, which contributes to improved generalization performance in machine learning tasks. As an application, we propose to use the quantum circuit $C^*$-algebra net to encode classical data into quantum states, which enables us to integrate classical data into quantum algorithms. Numerical results demonstrate that the interaction among circuits improves performance significantly in image classification, and encoded data by the quantum circuit $C^*$-algebra net are useful for downstream quantum machine learning tasks.
Glocal Hypergradient Estimation with Koopman Operator
Feb 05, 2024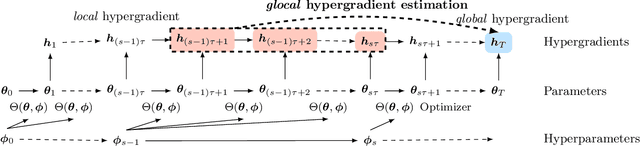
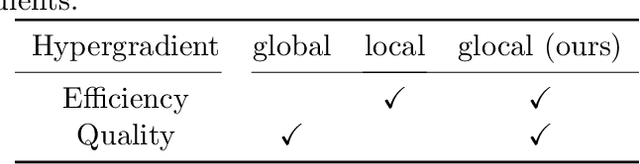
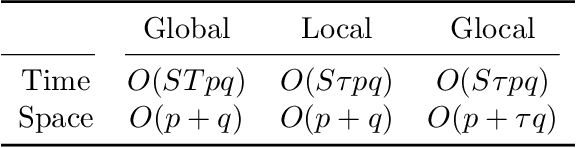
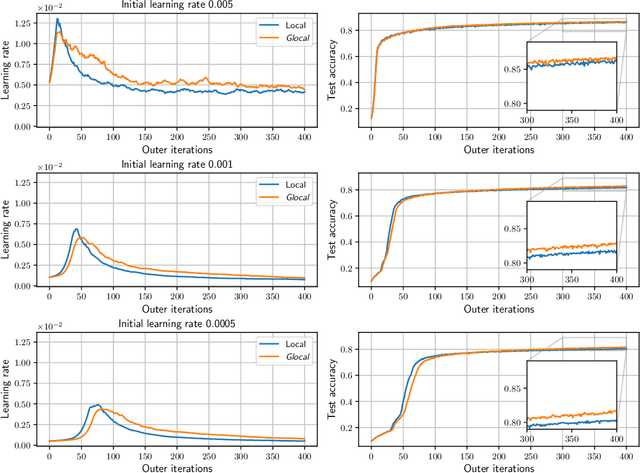
Gradient-based hyperparameter optimization methods update hyperparameters using hypergradients, gradients of a meta criterion with respect to hyperparameters. Previous research used two distinct update strategies: optimizing hyperparameters using global hypergradients obtained after completing model training or local hypergradients derived after every few model updates. While global hypergradients offer reliability, their computational cost is significant; conversely, local hypergradients provide speed but are often suboptimal. In this paper, we propose glocal hypergradient estimation, blending "global" quality with "local" efficiency. To this end, we use the Koopman operator theory to linearize the dynamics of hypergradients so that the global hypergradients can be efficiently approximated only by using a trajectory of local hypergradients. Consequently, we can optimize hyperparameters greedily using estimated global hypergradients, achieving both reliability and efficiency simultaneously. Through numerical experiments of hyperparameter optimization, including optimization of optimizers, we demonstrate the effectiveness of the glocal hypergradient estimation.
Self-attention Networks Localize When QK-eigenspectrum Concentrates
Feb 03, 2024



The self-attention mechanism prevails in modern machine learning. It has an interesting functionality of adaptively selecting tokens from an input sequence by modulating the degree of attention localization, which many researchers speculate is the basis of the powerful model performance but complicates the underlying mechanism of the learning dynamics. In recent years, mainly two arguments have connected attention localization to the model performances. One is the rank collapse, where the embedded tokens by a self-attention block become very similar across different tokens, leading to a less expressive network. The other is the entropy collapse, where the attention probability approaches non-uniform and entails low entropy, making the learning dynamics more likely to be trapped in plateaus. These two failure modes may apparently contradict each other because the rank and entropy collapses are relevant to uniform and non-uniform attention, respectively. To this end, we characterize the notion of attention localization by the eigenspectrum of query-key parameter matrices and reveal that a small eigenspectrum variance leads attention to be localized. Interestingly, the small eigenspectrum variance prevents both rank and entropy collapse, leading to better model expressivity and trainability.
An Empirical Investigation of Pre-trained Model Selection for Out-of-Distribution Generalization and Calibration
Jul 17, 2023In the realm of out-of-distribution generalization tasks, finetuning has risen as a key strategy. While the most focus has been on optimizing learning algorithms, our research highlights the influence of pre-trained model selection in finetuning on out-of-distribution performance and inference uncertainty. Balancing model size constraints of a single GPU, we examined the impact of varying pre-trained datasets and model parameters on performance metrics like accuracy and expected calibration error. Our findings underscore the significant influence of pre-trained model selection, showing marked performance improvements over algorithm choice. Larger models outperformed others, though the balance between memorization and true generalization merits further investigation. Ultimately, our research emphasizes the importance of pre-trained model selection for enhancing out-of-distribution generalization.
MNISQ: A Large-Scale Quantum Circuit Dataset for Machine Learning on/for Quantum Computers in the NISQ era
Jun 29, 2023



We introduce the first large-scale dataset, MNISQ, for both the Quantum and the Classical Machine Learning community during the Noisy Intermediate-Scale Quantum era. MNISQ consists of 4,950,000 data points organized in 9 subdatasets. Building our dataset from the quantum encoding of classical information (e.g., MNIST dataset), we deliver a dataset in a dual form: in quantum form, as circuits, and in classical form, as quantum circuit descriptions (quantum programming language, QASM). In fact, also the Machine Learning research related to quantum computers undertakes a dual challenge: enhancing machine learning exploiting the power of quantum computers, while also leveraging state-of-the-art classical machine learning methodologies to help the advancement of quantum computing. Therefore, we perform circuit classification on our dataset, tackling the task with both quantum and classical models. In the quantum endeavor, we test our circuit dataset with Quantum Kernel methods, and we show excellent results up to $97\%$ accuracy. In the classical world, the underlying quantum mechanical structures within the quantum circuit data are not trivial. Nevertheless, we test our dataset on three classical models: Structured State Space sequence model (S4), Transformer and LSTM. In particular, the S4 model applied on the tokenized QASM sequences reaches an impressive $77\%$ accuracy. These findings illustrate that quantum circuit-related datasets are likely to be quantum advantageous, but also that state-of-the-art machine learning methodologies can competently classify and recognize quantum circuits. We finally entrust the quantum and classical machine learning community the fundamental challenge to build more quantum-classical datasets like ours and to build future benchmarks from our experiments. The dataset is accessible on GitHub and its circuits are easily run in qulacs or qiskit.
Sketch-based Medical Image Retrieval
Mar 07, 2023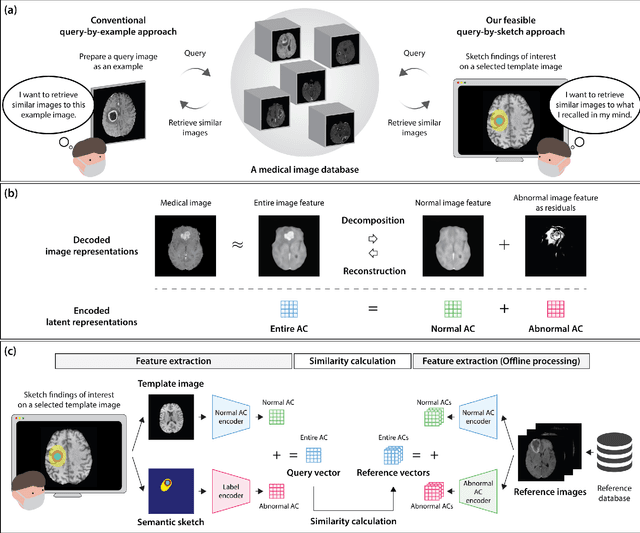
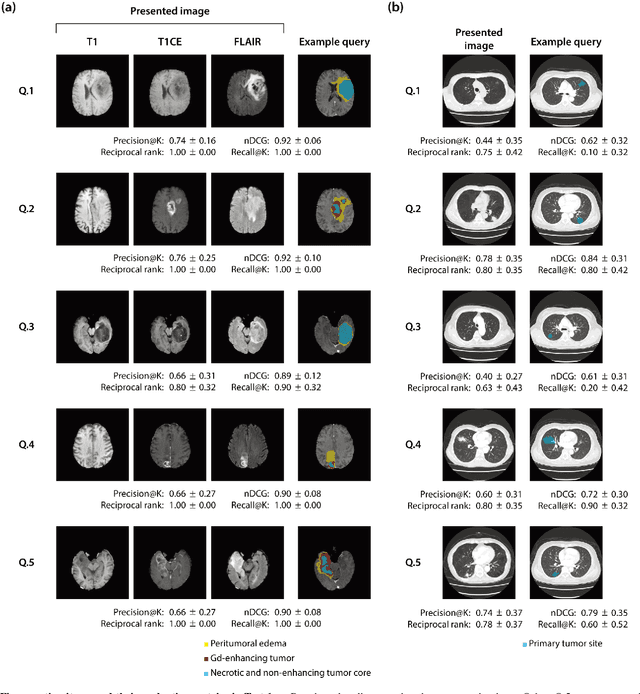
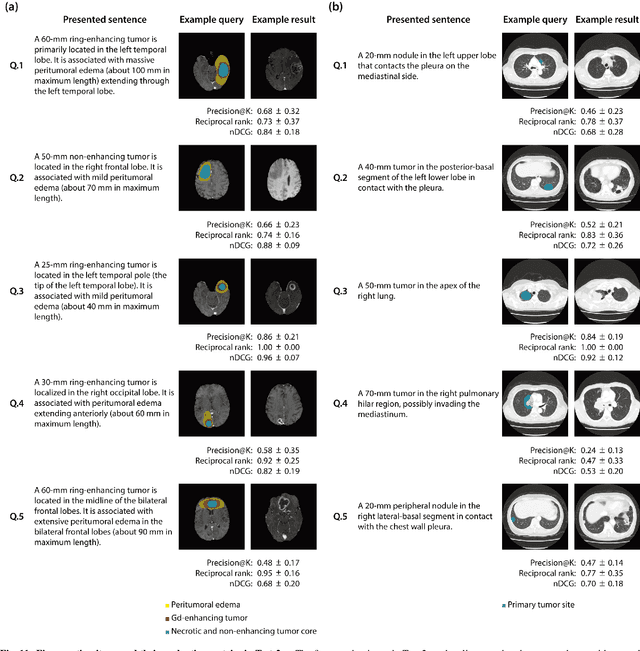
The amount of medical images stored in hospitals is increasing faster than ever; however, utilizing the accumulated medical images has been limited. This is because existing content-based medical image retrieval (CBMIR) systems usually require example images to construct query vectors; nevertheless, example images cannot always be prepared. Besides, there can be images with rare characteristics that make it difficult to find similar example images, which we call isolated samples. Here, we introduce a novel sketch-based medical image retrieval (SBMIR) system that enables users to find images of interest without example images. The key idea lies in feature decomposition of medical images, whereby the entire feature of a medical image can be decomposed into and reconstructed from normal and abnormal features. By extending this idea, our SBMIR system provides an easy-to-use two-step graphical user interface: users first select a template image to specify a normal feature and then draw a semantic sketch of the disease on the template image to represent an abnormal feature. Subsequently, it integrates the two kinds of input to construct a query vector and retrieves reference images with the closest reference vectors. Using two datasets, ten healthcare professionals with various clinical backgrounds participated in the user test for evaluation. As a result, our SBMIR system enabled users to overcome previous challenges, including image retrieval based on fine-grained image characteristics, image retrieval without example images, and image retrieval for isolated samples. Our SBMIR system achieves flexible medical image retrieval on demand, thereby expanding the utility of medical image databases.
Nystrom Method for Accurate and Scalable Implicit Differentiation
Feb 20, 2023The essential difficulty of gradient-based bilevel optimization using implicit differentiation is to estimate the inverse Hessian vector product with respect to neural network parameters. This paper proposes to tackle this problem by the Nystrom method and the Woodbury matrix identity, exploiting the low-rankness of the Hessian. Compared to existing methods using iterative approximation, such as conjugate gradient and the Neumann series approximation, the proposed method avoids numerical instability and can be efficiently computed in matrix operations without iterations. As a result, the proposed method works stably in various tasks and is faster than iterative approximations. Throughout experiments including large-scale hyperparameter optimization and meta learning, we demonstrate that the Nystrom method consistently achieves comparable or even superior performance to other approaches. The source code is available from https://github.com/moskomule/hypergrad.