 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBox-Constrained Softmax Function and Its Application for Post-Hoc Calibration
Jun 12, 2025Controlling the output probabilities of softmax-based models is a common problem in modern machine learning. Although the $\mathrm{Softmax}$ function provides soft control via its temperature parameter, it lacks the ability to enforce hard constraints, such as box constraints, on output probabilities, which can be critical in certain applications requiring reliable and trustworthy models. In this work, we propose the box-constrained softmax ($\mathrm{BCSoftmax}$) function, a novel generalization of the $\mathrm{Softmax}$ function that explicitly enforces lower and upper bounds on output probabilities. While $\mathrm{BCSoftmax}$ is formulated as the solution to a box-constrained optimization problem, we develop an exact and efficient computation algorithm for $\mathrm{BCSoftmax}$. As a key application, we introduce two post-hoc calibration methods based on $\mathrm{BCSoftmax}$. The proposed methods mitigate underconfidence and overconfidence in predictive models by learning the lower and upper bounds of the output probabilities or logits after model training, thereby enhancing reliability in downstream decision-making tasks. We demonstrate the effectiveness of our methods experimentally using the TinyImageNet, CIFAR-100, and 20NewsGroups datasets, achieving improvements in calibration metrics.
Analyzing Social Biases in Japanese Large Language Models
Jun 04, 2024With the development of Large Language Models (LLMs), social biases in the LLMs have become a crucial issue. While various benchmarks for social biases have been provided across languages, the extent to which Japanese LLMs exhibit social biases has not been fully investigated. In this study, we construct the Japanese Bias Benchmark dataset for Question Answering (JBBQ) based on the English bias benchmark BBQ, and analyze social biases in Japanese LLMs. The results show that while current Japanese LLMs improve their accuracies on JBBQ by instruction-tuning, their bias scores become larger. In addition, augmenting their prompts with warning about social biases reduces the effect of biases in some models.
Will Large-scale Generative Models Corrupt Future Datasets?
Nov 15, 2022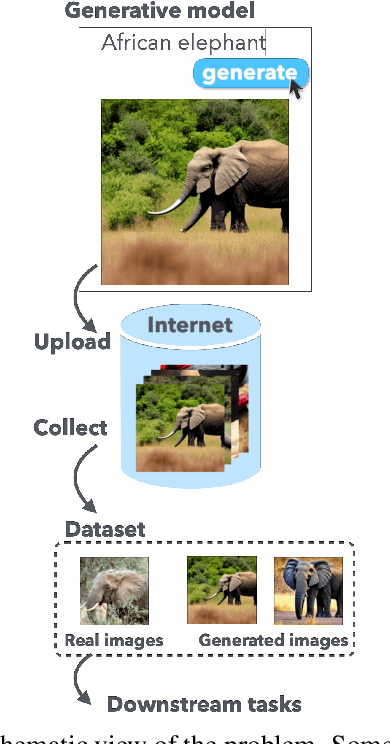
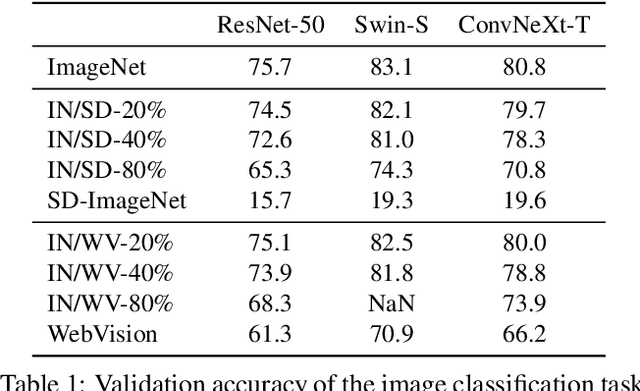

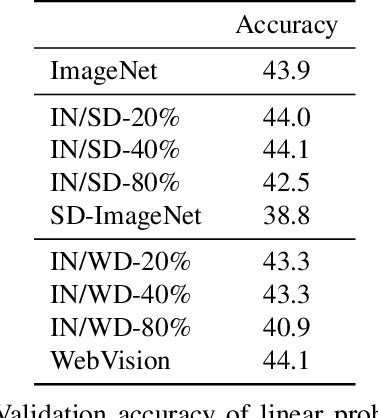
Recently proposed large-scale text-to-image generative models such as DALL$\cdot$E 2, Midjourney, and StableDiffusion can generate high-quality and realistic images from users' prompts. Not limited to the research community, ordinary Internet users enjoy these generative models, and consequently a tremendous amount of generated images have been shared on the Internet. Meanwhile, today's success of deep learning in the computer vision field owes a lot to images collected from the Internet. These trends lead us to a research question: "will such generated images impact the quality of future datasets and the performance of computer vision models positively or negatively?" This paper empirically answers this question by simulating contamination. Namely, we generate ImageNet-scale and COCO-scale datasets using a state-of-the-art generative model and evaluate models trained on ``contaminated'' datasets on various tasks including image classification and image generation. Throughout experiments, we conclude that generated images negatively affect downstream performance, while the significance depends on tasks and the amount of generated images. The generated datasets are available via https://github.com/moskomule/dataset-contamination.
Characterizing the risk of fairwashing
Jun 14, 2021
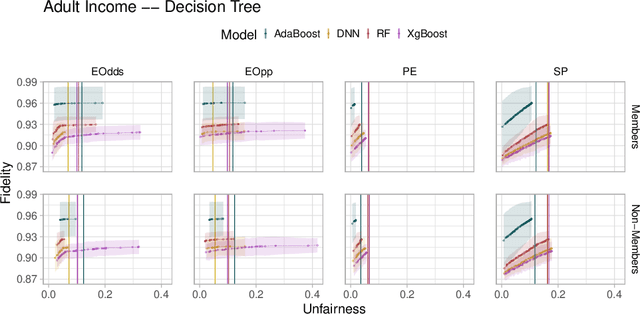
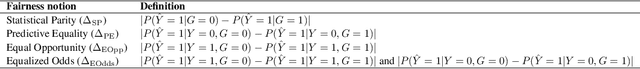

Fairwashing refers to the risk that an unfair black-box model can be explained by a fairer model through post-hoc explanations' manipulation. However, to realize this, the post-hoc explanation model must produce different predictions than the original black-box on some inputs, leading to a decrease in the fidelity imposed by the difference in unfairness. In this paper, our main objective is to characterize the risk of fairwashing attacks, in particular by investigating the fidelity-unfairness trade-off. First, we demonstrate through an in-depth empirical study on black-box models trained on several real-world datasets and for several statistical notions of fairness that it is possible to build high-fidelity explanation models with low unfairness. For instance, we find that fairwashed explanation models can exhibit up to $99.20\%$ fidelity to the black-box models they explain while being $50\%$ less unfair. These results suggest that fidelity alone should not be used as a proxy for the quality of black-box explanations. Second, we show that fairwashed explanation models can generalize beyond the suing group (\emph{i.e.}, data points that are being explained), which will only worsen as more stable fairness methods get developed. Finally, we demonstrate that fairwashing attacks can transfer across black-box models, meaning that other black-box models can perform fairwashing without explicitly using their predictions.
Fairwashing: the risk of rationalization
Jan 28, 2019
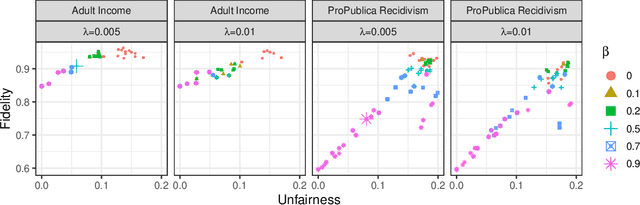
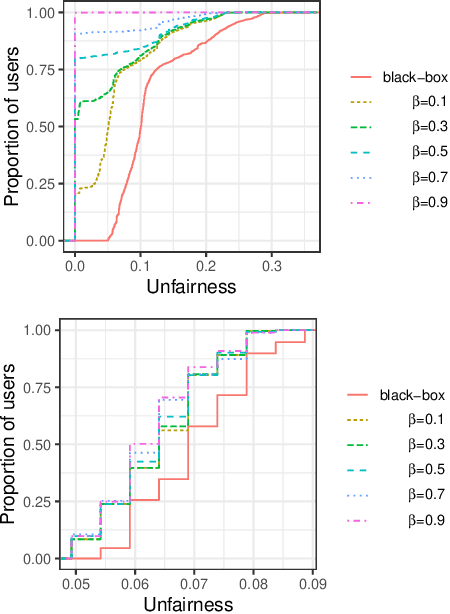
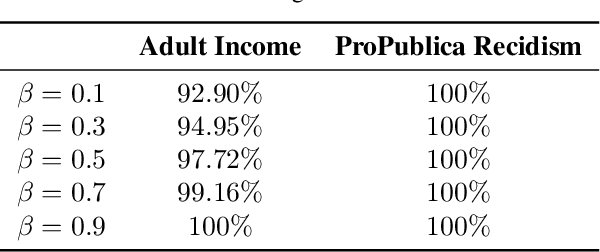
Black-box explanation is the problem of explaining how a machine learning model -- whose internal logic is hidden to the auditor and generally complex -- produces its outcomes. Current approaches for solving this problem include model explanation, outcome explanation as well as model inspection. While these techniques can be beneficial by providing interpretability, they can be used in a negative manner to perform fairwashing, which we define as promoting the perception that a machine learning model respects some ethical values while it might not be the case. In particular, we demonstrate that it is possible to systematically rationalize decisions taken by an unfair black-box model using the model explanation as well as the outcome explanation approaches with a given fairness metric. Our solution, LaundryML, is based on a regularized rule list enumeration algorithm whose objective is to search for fair rule lists approximating an unfair black-box model. We empirically evaluate our rationalization technique on black-box models trained on real-world datasets and show that one can obtain rule lists with high fidelity to the black-box model while being considerably less unfair at the same time.