 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Studying Reinforcement Learning and Sim-to-Real in Robot Soccer
Aug 18, 2020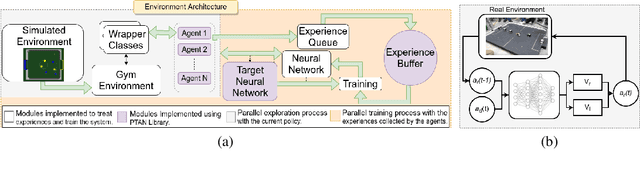
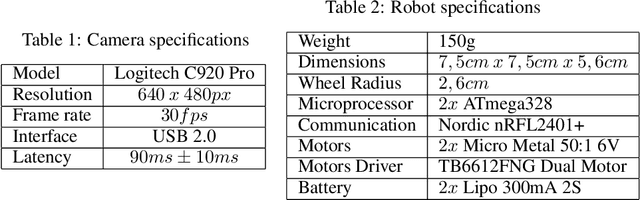

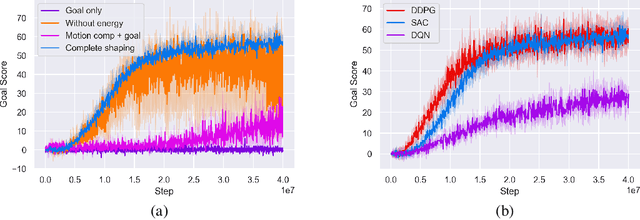
This article introduces an open framework, called VSSS-RL, for studying Reinforcement Learning (RL) and sim-to-real in robot soccer, focusing on the IEEE Very Small Size Soccer (VSSS) league. We propose a simulated environment in which continuous or discrete control policies can be trained to control the complete behavior of soccer agents and a sim-to-real method based on domain adaptation to adapt the obtained policies to real robots. Our results show that the trained policies learned a broad repertoire of behaviors that are difficult to implement with handcrafted control policies. With VSSS-RL, we were able to beat human-designed policies in the 2019 Latin American Robotics Competition (LARC), achieving 4th place out of 21 teams, being the first to apply Reinforcement Learning (RL) successfully in this competition. Both environment and hardware specifications are available open-source to allow reproducibility of our results and further studies.
Learning to Play Soccer by Reinforcement and Applying Sim-to-Real to Compete in the Real World
Mar 24, 2020
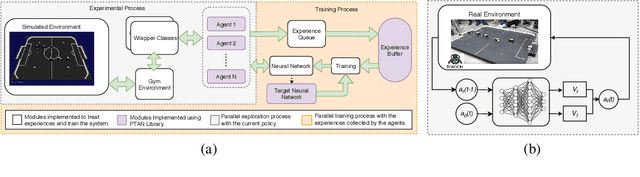
This work presents an application of Reinforcement Learning (RL) for the complete control of real soccer robots of the IEEE Very Small Size Soccer (VSSS), a traditional league in the Latin American Robotics Competition (LARC). In the VSSS league, two teams of three small robots play against each other. We propose a simulated environment in which continuous or discrete control policies can be trained, and a Sim-to-Real method to allow using the obtained policies to control a robot in the real world. The results show that the learned policies display a broad repertoire of behaviors that are difficult to specify by hand. This approach, called VSSS-RL, was able to beat the human-designed policy for the striker of the team ranked 3rd place in the 2018 LARC, in 1-vs-1 matches.
Distinction Maximization Loss: Fast, Scalable, Turnkey, and Native Neural Networks Out-of-Distribution Detection simply by Replacing the SoftMax Loss
Aug 20, 2019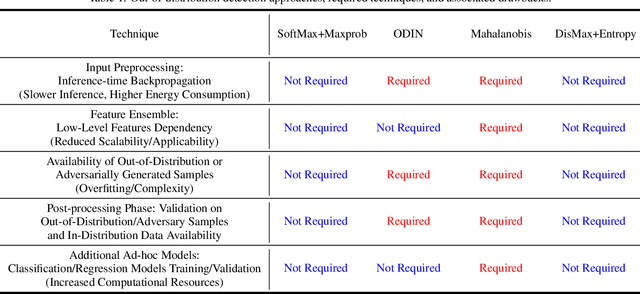

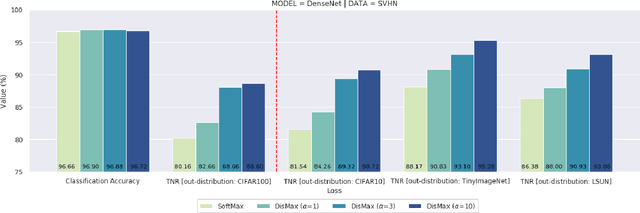
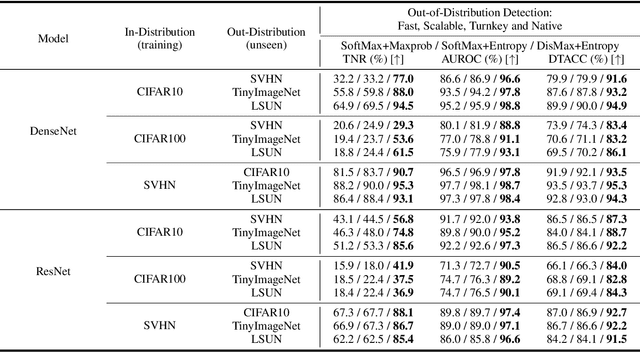
Recently, many methods to reduce neural networks uncertainty have been proposed. However, most of the techniques used in these solutions usually present severe drawbacks. In this paper, we argue that neural networks low out-of-distribution detection performance is mainly due to the SoftMax loss anisotropy. Therefore, we built an isotropic loss to reduce neural networks uncertainty in a fast, scalable, turnkey, and native approach. Our experiments show that replacing SoftMax with the proposed loss does not affect classification accuracy. Moreover, our proposal overcomes ODIN typically by a large margin while producing usually competitive results against a state-of-the-art Mahalanobis method despite avoiding their limitations. Hence, neural networks uncertainty may be significantly reduced by a simple loss change without relying on special procedures such as data augmentation, adversarial training/validation, ensembles, or additional classification/regression models.
Agnostic data debiasing through a local sanitizer learnt from an adversarial network approach
Jun 19, 2019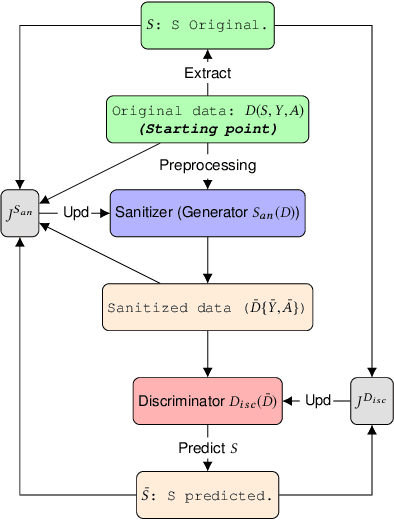


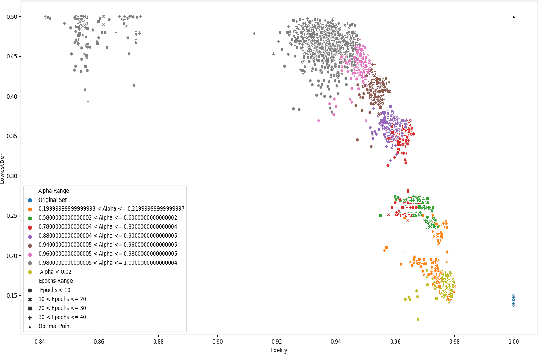
The widespread use of automated decision processes in many areas of our society raises serious ethical issues concerning the fairness of the process and the possible resulting discriminations. In this work, we propose a novel approach called \gansan whose objective is to prevent the possibility of \emph{any} discrimination i.e., direct and indirect) based on a sensitive attribute by removing the attribute itself as well as the existing correlations with the remaining attributes. Our sanitization algorithm \gansan is partially inspired by the powerful framework of generative adversarial networks (in particuler the Cycle-GANs), which offers a flexible way to learn a distribution empirically or to translate between two different distributions. In contrast to prior work, one of the strengths of our approach is that the sanitization is performed in the same space as the original data by only modifying the other attributes as little as possible and thus preserving the interpretability of the sanitized data. As a consequence, once the sanitizer is trained, it can be applied to new data, such as for instance, locally by an individual on his profile before releasing it. Finally, experiments on a real dataset demonstrate the effectiveness of the proposed approach as well as the achievable trade-off between fairness and utility.
Towards Lossless Encoding of Sentences
Jun 04, 2019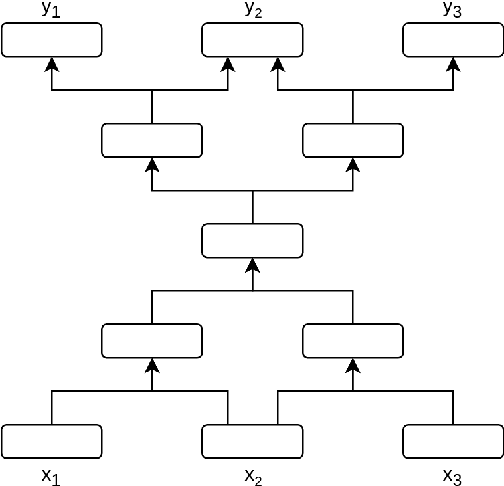
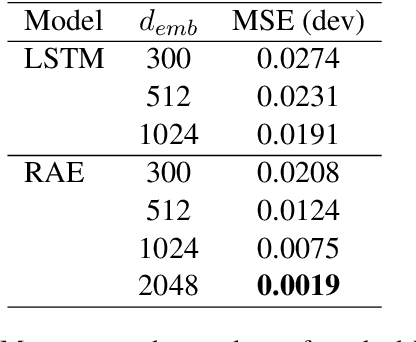
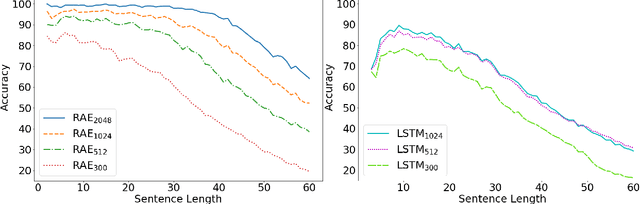

A lot of work has been done in the field of image compression via machine learning, but not much attention has been given to the compression of natural language. Compressing text into lossless representations while making features easily retrievable is not a trivial task, yet has huge benefits. Most methods designed to produce feature rich sentence embeddings focus solely on performing well on downstream tasks and are unable to properly reconstruct the original sequence from the learned embedding. In this work, we propose a near lossless method for encoding long sequences of texts as well as all of their sub-sequences into feature rich representations. We test our method on sentiment analysis and show good performance across all sub-sentence and sentence embeddings.
Fairwashing: the risk of rationalization
Jan 28, 2019
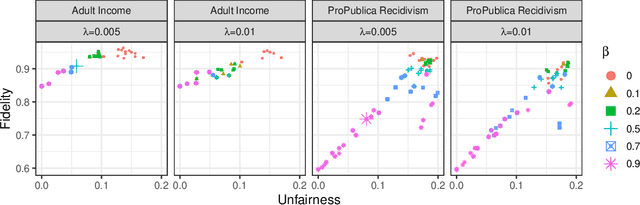
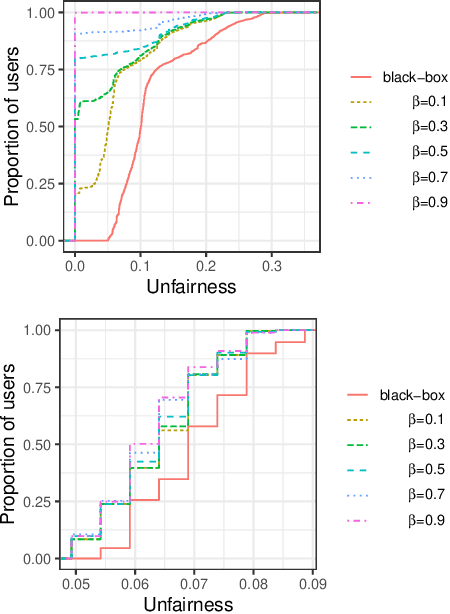
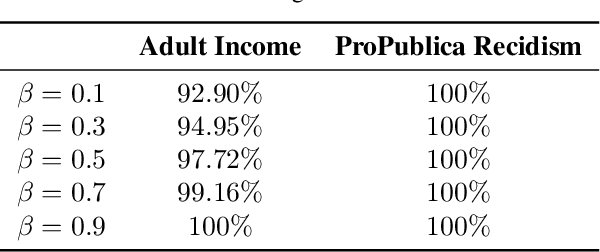
Black-box explanation is the problem of explaining how a machine learning model -- whose internal logic is hidden to the auditor and generally complex -- produces its outcomes. Current approaches for solving this problem include model explanation, outcome explanation as well as model inspection. While these techniques can be beneficial by providing interpretability, they can be used in a negative manner to perform fairwashing, which we define as promoting the perception that a machine learning model respects some ethical values while it might not be the case. In particular, we demonstrate that it is possible to systematically rationalize decisions taken by an unfair black-box model using the model explanation as well as the outcome explanation approaches with a given fairness metric. Our solution, LaundryML, is based on a regularized rule list enumeration algorithm whose objective is to search for fair rule lists approximating an unfair black-box model. We empirically evaluate our rationalization technique on black-box models trained on real-world datasets and show that one can obtain rule lists with high fidelity to the black-box model while being considerably less unfair at the same time.
A new approach in machine learning
Sep 14, 2014
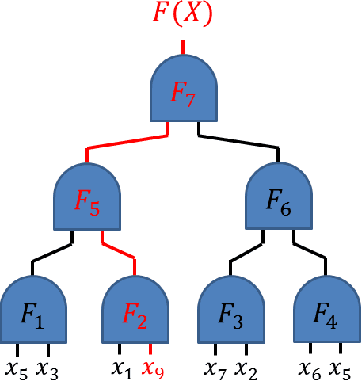
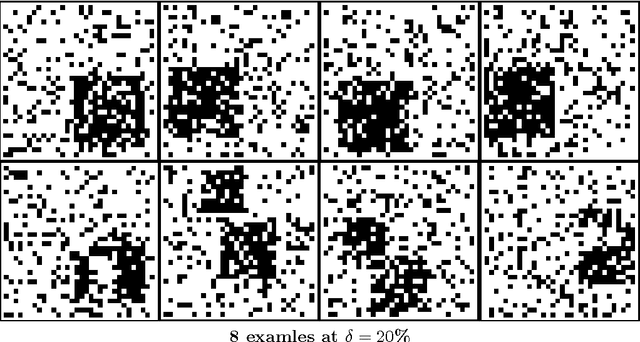
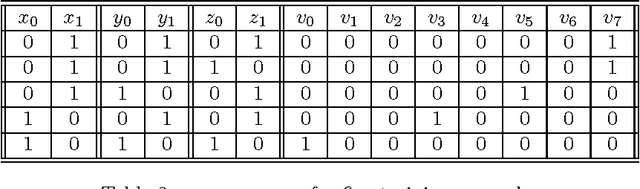
In this technical report we presented a novel approach to machine learning. Once the new framework is presented, we will provide a simple and yet very powerful learning algorithm which will be benchmark on various dataset. The framework we proposed is based on booleen circuits; more specifically the classifier produced by our algorithm have that form. Using bits and boolean gates instead of real numbers and multiplication enable the the learning algorithm and classifier to use very efficient boolean vector operations. This enable both the learning algorithm and classifier to be extremely efficient. The accuracy of the classifier we obtain with our framework compares very favorably those produced by conventional techniques, both in terms of efficiency and accuracy.