 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Distinction Maximization Loss: Efficiently Improving Classification Accuracy, Uncertainty Estimation, and Out-of-Distribution Detection Simply Replacing the Loss and Calibrating
May 19, 2022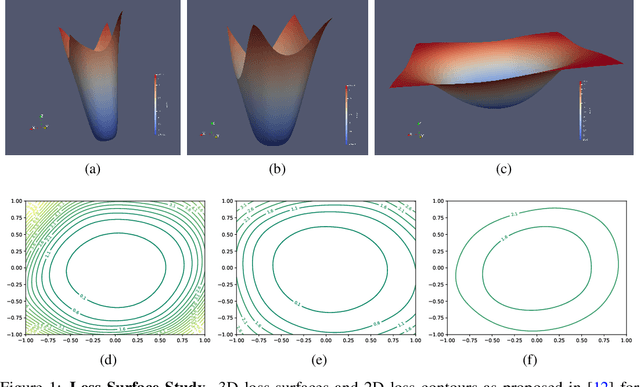
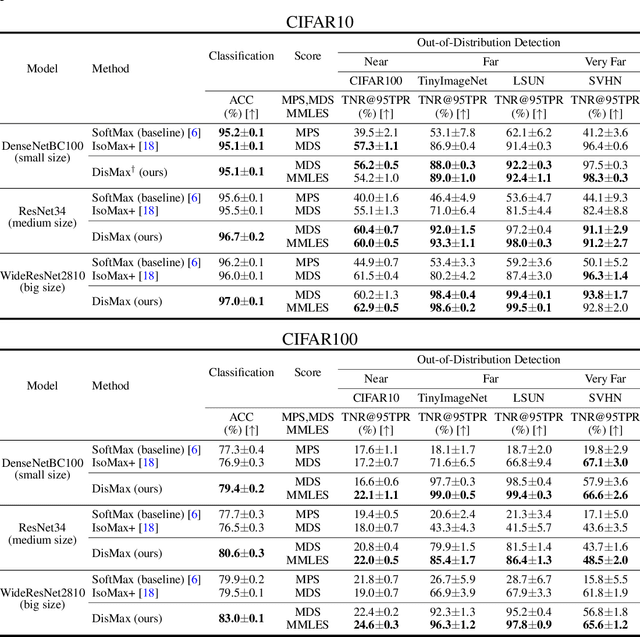
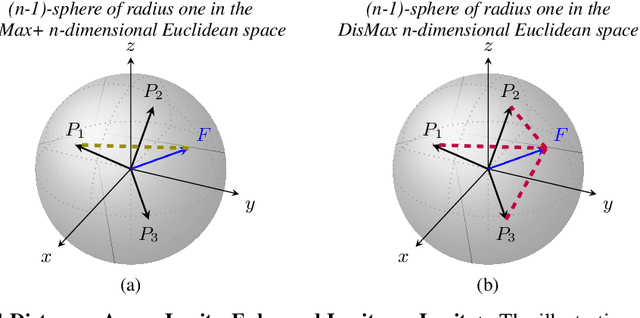
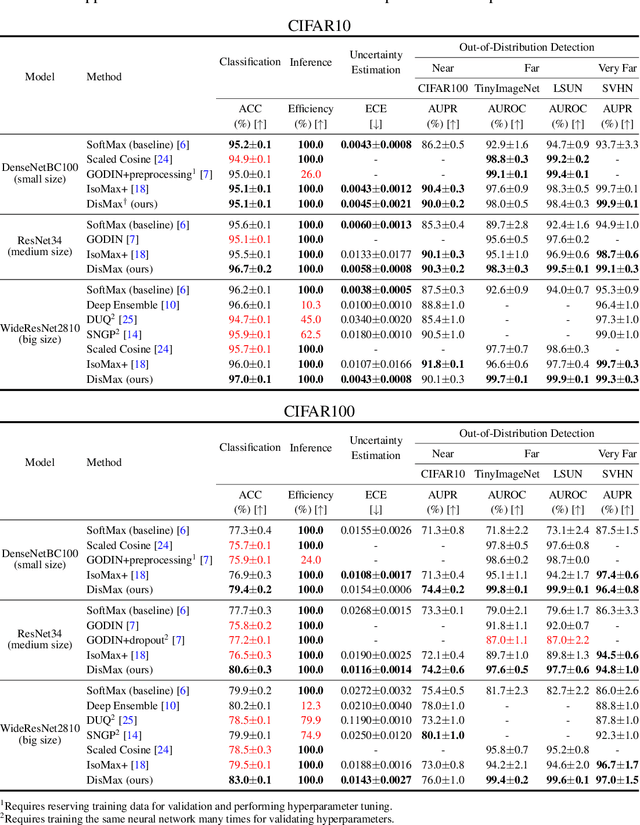
Building robust deterministic neural networks remains a challenge. On the one hand, some approaches improve out-of-distribution detection at the cost of reducing classification accuracy in some situations. On the other hand, some methods simultaneously increase classification accuracy, uncertainty estimation, and out-of-distribution detection at the expense of reducing the inference efficiency and requiring training the same model many times to tune hyperparameters. In this paper, we propose training deterministic neural networks using our DisMax loss, which works as a drop-in replacement for the usual SoftMax loss (i.e., the combination of the linear output layer, the SoftMax activation, and the cross-entropy loss). Starting from the IsoMax+ loss, we create each logit based on the distances to all prototypes rather than just the one associated with the correct class. We also introduce a mechanism to combine images to construct what we call fractional probability regularization. Moreover, we present a fast way to calibrate the network after training. Finally, we propose a composite score to perform out-of-distribution detection. Our experiments show that DisMax usually outperforms current approaches simultaneously in classification accuracy, uncertainty estimation, and out-of-distribution detection while maintaining deterministic neural network inference efficiency and avoiding training the same model repetitively for hyperparameter tuning. The code to reproduce the results is available at https://github.com/dlmacedo/distinction-maximization-loss.
Metodos de Agrupamentos em dois Estagios
Aug 02, 2021This work investigates the use of two-stage clustering methods. Four techniques were proposed: SOMK, SOMAK, ASCAK and SOINAK. SOMK is composed of a SOM (Self-Organizing Maps) followed by the K-means algorithm, SOMAK is a combination of SOM followed by the Ant K-means (AK) algorithm, ASCAK is composed by the ASCA (Ant System-based Clustering Algorithm) and AK algorithms, SOINAK is composed by the Self-Organizing Incremental Neural Network (SOINN) and AK. SOINAK presented a better performance among the four proposed techniques when applied to pattern recognition problems.
Otimizacao de pesos e funcoes de ativacao de redes neurais aplicadas na previsao de series temporais
Jul 29, 2021Neural Networks have been applied for time series prediction with good experimental results that indicate the high capacity to approximate functions with good precision. Most neural models used in these applications use activation functions with fixed parameters. However, it is known that the choice of activation function strongly influences the complexity and performance of the neural network and that a limited number of activation functions have been used. In this work, we propose the use of a family of free parameter asymmetric activation functions for neural networks and show that this family of defined activation functions satisfies the requirements of the universal approximation theorem. A methodology for the global optimization of this family of activation functions with free parameter and the weights of the connections between the processing units of the neural network is used. The central idea of the proposed methodology is to simultaneously optimize the weights and the activation function used in a multilayer perceptron network (MLP), through an approach that combines the advantages of simulated annealing, tabu search and a local learning algorithm, with the purpose of improving performance in the adjustment and forecasting of time series. We chose two learning algorithms: backpropagation with the term momentum (BPM) and LevenbergMarquardt (LM).
Otimizacao de Redes Neurais atraves de Algoritmos Geneticos Celulares
Jul 18, 2021This works proposes a methodology to searching for automatically Artificial Neural Networks (ANN) by using Cellular Genetic Algorithm (CGA). The goal of this methodology is to find compact networks whit good performance for classification problems. The main reason for developing this work is centered at the difficulties of configuring compact ANNs with good performance rating. The use of CGAs aims at seeking the components of the RNA in the same way that a common Genetic Algorithm (GA), but it has the differential of incorporating a Cellular Automaton (CA) to give location for the GA individuals. The location imposed by the CA aims to control the spread of solutions in the populations to maintain the genetic diversity for longer time. This genetic diversity is important for obtain good results with the GAs.
Uso de GSO cooperativos com decaimentos de pesos para otimizacao de redes neurais
Jul 05, 2021Training of Artificial Neural Networks is a complex task of great importance in supervised learning problems. Evolutionary Algorithms are widely used as global optimization techniques and these approaches have been used for Artificial Neural Networks to perform various tasks. An optimization algorithm, called Group Search Optimizer (GSO), was proposed and inspired by the search behaviour of animals. In this article we present two new hybrid approaches: CGSO-Hk-WD and CGSO-Sk-WD. Cooperative GSOs are based on the divide-and-conquer paradigm, employing cooperative behaviour between GSO groups to improve the performance of the standard GSO. We also apply the weight decay strategy (WD, acronym for Weight Decay) to increase the generalizability of the networks. The results show that cooperative GSOs are able to achieve better performance than traditional GSO for classification problems in benchmark datasets such as Cancer, Diabetes, Ecoli and Glass datasets.
Improving Entropic Out-of-Distribution Detection using Isometric Distances and the Minimum Distance Score
Jun 23, 2021
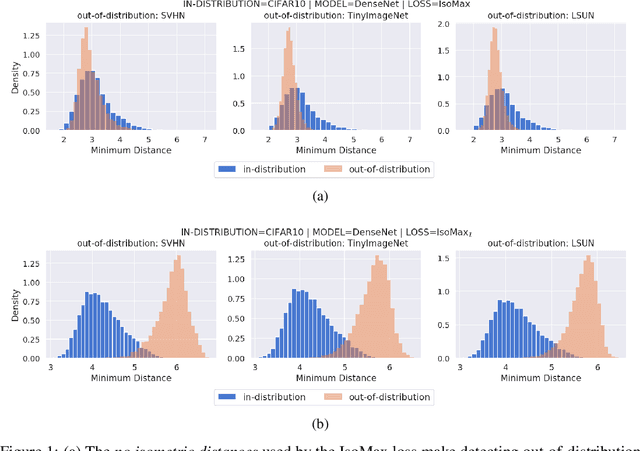

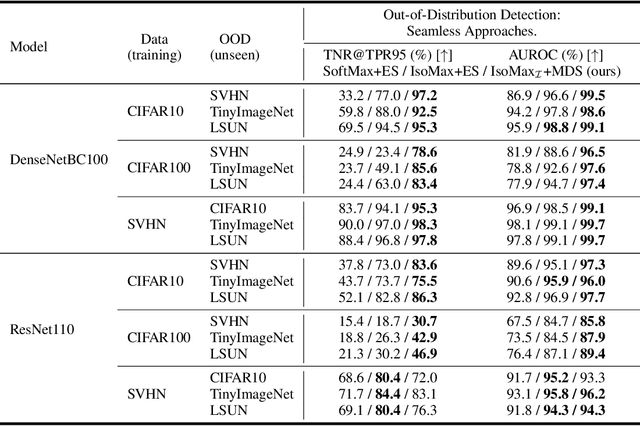
Current out-of-distribution detection approaches usually present special requirements (e.g., collecting outlier data and hyperparameter validation) and produce side effects (classification accuracy drop and slow/inefficient inferences). Recently, entropic out-of-distribution detection has been proposed as a seamless approach (i.e., a solution that avoids all the previously mentioned drawbacks). The entropic out-of-distribution detection solution comprises the IsoMax loss for training and the entropic score for out-of-distribution detection. The IsoMax loss works as a SoftMax loss drop-in replacement because swapping the SoftMax loss with the IsoMax loss requires no changes in the model's architecture or training procedures/hyperparameters. In this paper, we propose to perform what we call an isometrization of the distances used in the IsoMax loss. Additionally, we propose to replace the entropic score with the minimum distance score. Our experiments showed that these simple modifications increase out-of-distribution detection performance while keeping the solution seamless.
Training Aware Sigmoidal Optimizer
Feb 17, 2021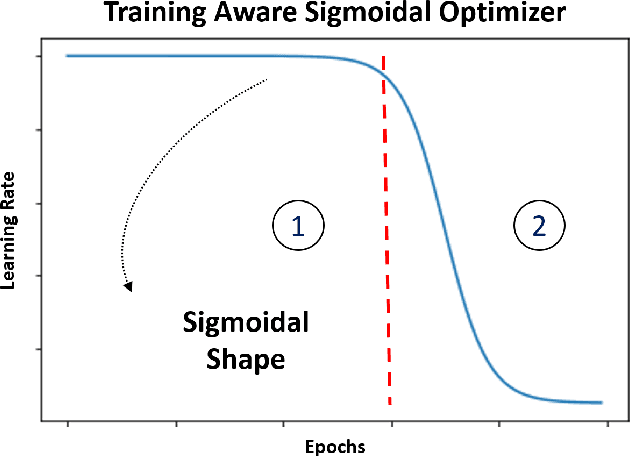

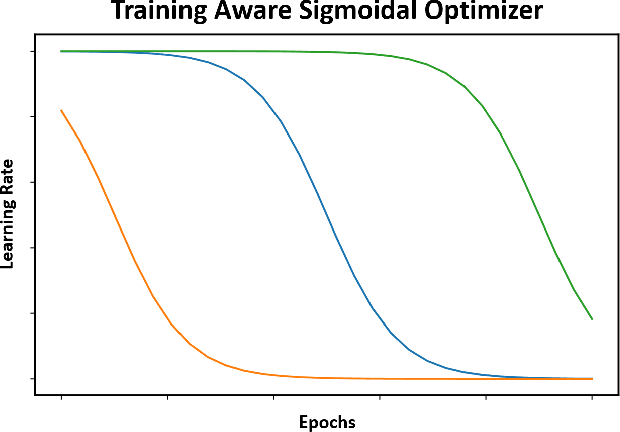
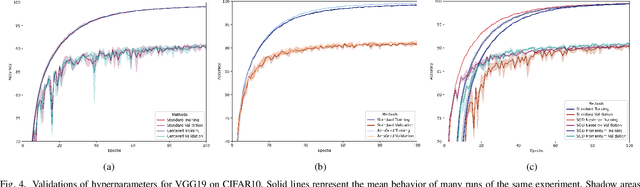
Proper optimization of deep neural networks is an open research question since an optimal procedure to change the learning rate throughout training is still unknown. Manually defining a learning rate schedule involves troublesome time-consuming try and error procedures to determine hyperparameters such as learning rate decay epochs and learning rate decay rates. Although adaptive learning rate optimizers automatize this process, recent studies suggest they may produce overffiting and reduce performance when compared to fine-tuned learning rate schedules. Considering that deep neural networks loss functions present landscapes with much more saddle points than local minima, we proposed the Training Aware Sigmoidal Optimizer (TASO), which consists of a two-phases automated learning rate schedule. The first phase uses a high learning rate to fast traverse the numerous saddle point, while the second phase uses low learning rate to slowly approach the center of the local minimum previously found. We compared the proposed approach with commonly used adaptive learning rate schedules such as Adam, RMSProp, and Adagrad. Our experiments showed that TASO outperformed all competing methods in both optimal (i.e., performing hyperparameter validation) and suboptimal (i.e., using default hyperparameters) scenarios.
Similarity Based Stratified Splitting: an approach to train better classifiers
Oct 13, 2020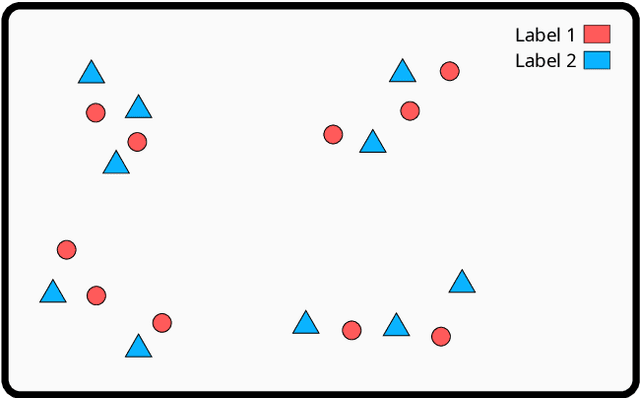
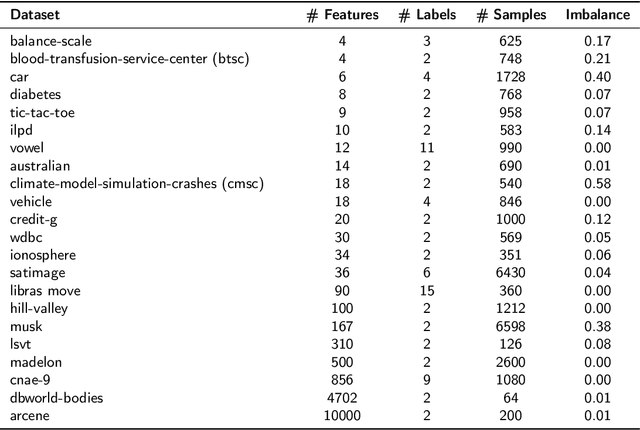
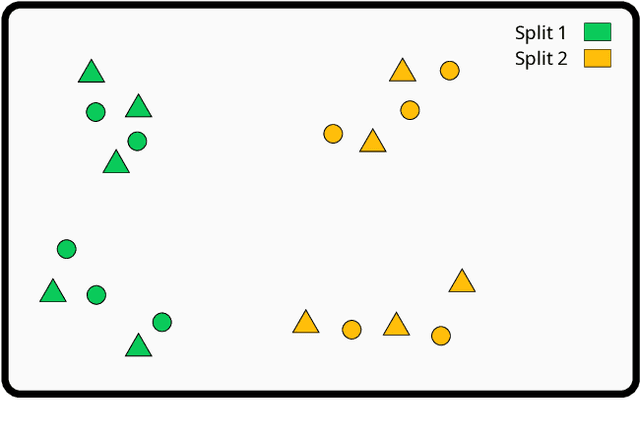
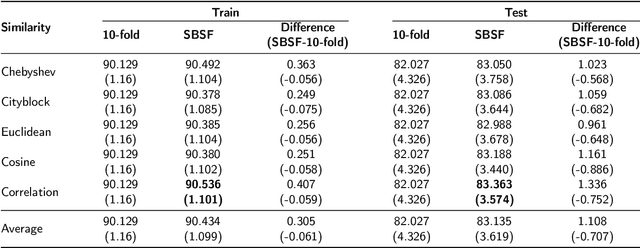
We propose a Similarity-Based Stratified Splitting (SBSS) technique, which uses both the output and input space information to split the data. The splits are generated using similarity functions among samples to place similar samples in different splits. This approach allows for a better representation of the data in the training phase. This strategy leads to a more realistic performance estimation when used in real-world applications. We evaluate our proposal in twenty-two benchmark datasets with classifiers such as Multi-Layer Perceptron, Support Vector Machine, Random Forest and K-Nearest Neighbors, and five similarity functions Cityblock, Chebyshev, Cosine, Correlation, and Euclidean. According to the Wilcoxon Sign-Rank test, our approach consistently outperformed ordinary stratified 10-fold cross-validation in 75\% of the assessed scenarios.
Neural Networks Out-of-Distribution Detection: Hyperparameter-Free Isotropic Maximization Loss, The Principle of Maximum Entropy, Cold Training, and Branched Inferences
Jun 07, 2020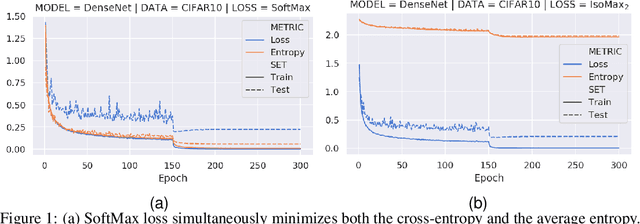

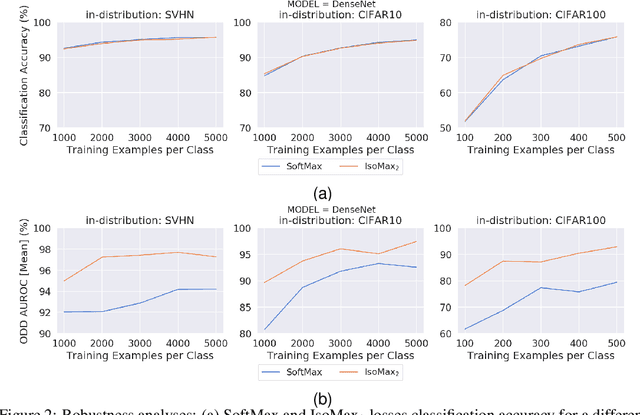

Current out-of-distribution detection (ODD) approaches present severe drawbacks that make impracticable their large scale adoption in real-world applications. In this paper, we propose a novel loss called Hyperparameter-Free IsoMax that overcomes these limitations. We modified the original IsoMax loss to improve ODD performance while maintaining benefits such as high classification accuracy, fast and energy-efficient inference, and scalability. The global hyperparameter is replaced by learnable parameters to increase performance. Additionally, a theoretical motivation to explain the high ODD performance of the proposed loss is presented. Finally, to keep high classification performance, slightly different inference mathematical expressions for classification and ODD are developed. No access to out-of-distribution samples is required, as there is no hyperparameter to tune. Our solution works as a straightforward SoftMax loss drop-in replacement that can be incorporated without relying on adversarial training or validation, model structure chances, ensembles methods, or generative approaches. The experiments showed that our approach is competitive against state-of-the-art solutions while avoiding their additional requirements and undesired side effects.