 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Energy Consumption Models Based On Smartphone User's Usage Patterns
Dec 15, 2020



The increasing usage of smartphones in everyday tasks has been motivated many studies on energy consumption characterization aiming to improve smartphone devices' effectiveness and increase user usage time. In this scenario, it is essential to study mechanisms capable of characterizing user usage patterns, so smartphones' components can be adapted to promote the best user experience with lower energy consumption. The goal of this study is to build an energy consumption model based on user usage patterns aiming to provide the best accurate model to be used by application developers and automated optimization. To develop the energy consumption models, we established a method to identify the components with the most influence in the smartphone's energy consumption and identify the states of each influential device. Besides that, we established a method to prove the robustness of the models constructed using inaccurate hardware and a strategy to assess the accuracy of the model built. After training and testing each strategy to model the energy consumption based on the user's usage and perform the Nemenyi test, we demonstrated that it is possible to get a Mean Absolute Error of 158.57mW when the smartphone's average power is 1970.1mW. Some studies show that the leading smartphone's workload is the user. Based on this fact, we developed an automatic model building methodology that is capable of analyzing the user's usage data and build smart models that can estimate the smartphone's energy consumption based on the user's usage pattern. With the automatic model building methodology, we can adopt strategies to minimize the usage of components that drain the battery.
Similarity Based Stratified Splitting: an approach to train better classifiers
Oct 13, 2020
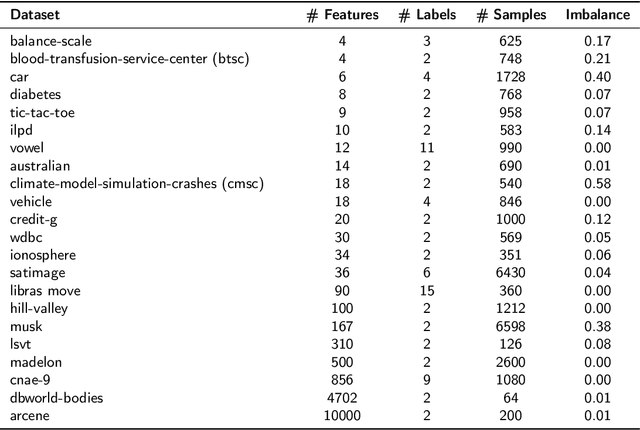
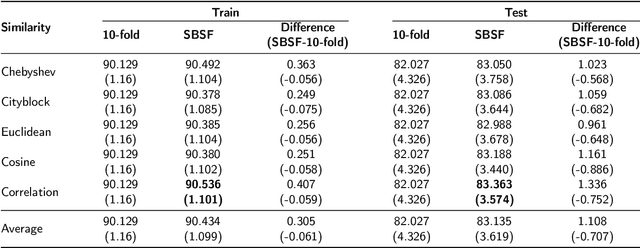
We propose a Similarity-Based Stratified Splitting (SBSS) technique, which uses both the output and input space information to split the data. The splits are generated using similarity functions among samples to place similar samples in different splits. This approach allows for a better representation of the data in the training phase. This strategy leads to a more realistic performance estimation when used in real-world applications. We evaluate our proposal in twenty-two benchmark datasets with classifiers such as Multi-Layer Perceptron, Support Vector Machine, Random Forest and K-Nearest Neighbors, and five similarity functions Cityblock, Chebyshev, Cosine, Correlation, and Euclidean. According to the Wilcoxon Sign-Rank test, our approach consistently outperformed ordinary stratified 10-fold cross-validation in 75\% of the assessed scenarios.