 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Effective AI Governance: A Review of Principles
May 29, 2025Artificial Intelligence (AI) governance is the practice of establishing frameworks, policies, and procedures to ensure the responsible, ethical, and safe development and deployment of AI systems. Although AI governance is a core pillar of Responsible AI, current literature still lacks synthesis across such governance frameworks and practices. Objective: To identify which frameworks, principles, mechanisms, and stakeholder roles are emphasized in secondary literature on AI governance. Method: We conducted a rapid tertiary review of nine peer-reviewed secondary studies from IEEE and ACM (20202024), using structured inclusion criteria and thematic semantic synthesis. Results: The most cited frameworks include the EU AI Act and NIST RMF; transparency and accountability are the most common principles. Few reviews detail actionable governance mechanisms or stakeholder strategies. Conclusion: The review consolidates key directions in AI governance and highlights gaps in empirical validation and inclusivity. Findings inform both academic inquiry and practical adoption in organizations.
Automatically Categorising GitHub Repositories by Application Domain
Jul 30, 2022

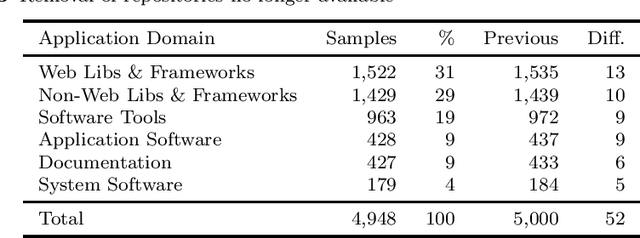

GitHub is the largest host of open source software on the Internet. This large, freely accessible database has attracted the attention of practitioners and researchers alike. But as GitHub's growth continues, it is becoming increasingly hard to navigate the plethora of repositories which span a wide range of domains. Past work has shown that taking the application domain into account is crucial for tasks such as predicting the popularity of a repository and reasoning about project quality. In this work, we build on a previously annotated dataset of 5,000 GitHub repositories to design an automated classifier for categorising repositories by their application domain. The classifier uses state-of-the-art natural language processing techniques and machine learning to learn from multiple data sources and catalogue repositories according to five application domains. We contribute with (1) an automated classifier that can assign popular repositories to each application domain with at least 70% precision, (2) an investigation of the approach's performance on less popular repositories, and (3) a practical application of this approach to answer how the adoption of software engineering practices differs across application domains. Our work aims to help the GitHub community identify repositories of interest and opens promising avenues for future work investigating differences between repositories from different application domains.
Building Energy Consumption Models Based On Smartphone User's Usage Patterns
Dec 15, 2020



The increasing usage of smartphones in everyday tasks has been motivated many studies on energy consumption characterization aiming to improve smartphone devices' effectiveness and increase user usage time. In this scenario, it is essential to study mechanisms capable of characterizing user usage patterns, so smartphones' components can be adapted to promote the best user experience with lower energy consumption. The goal of this study is to build an energy consumption model based on user usage patterns aiming to provide the best accurate model to be used by application developers and automated optimization. To develop the energy consumption models, we established a method to identify the components with the most influence in the smartphone's energy consumption and identify the states of each influential device. Besides that, we established a method to prove the robustness of the models constructed using inaccurate hardware and a strategy to assess the accuracy of the model built. After training and testing each strategy to model the energy consumption based on the user's usage and perform the Nemenyi test, we demonstrated that it is possible to get a Mean Absolute Error of 158.57mW when the smartphone's average power is 1970.1mW. Some studies show that the leading smartphone's workload is the user. Based on this fact, we developed an automatic model building methodology that is capable of analyzing the user's usage data and build smart models that can estimate the smartphone's energy consumption based on the user's usage pattern. With the automatic model building methodology, we can adopt strategies to minimize the usage of components that drain the battery.