 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents
Jan 28, 2026AI coding agents such as Codex and Claude Code are increasingly used to autonomously contribute to software repositories. However, little is known about how repository-level configuration artifacts affect operational efficiency of the agents. In this paper, we study the impact of AGENTS$.$md files on the runtime and token consumption of AI coding agents operating on GitHub pull requests. We analyze 10 repositories and 124 pull requests, executing agents under two conditions: with and without an AGENTS$.$md file. We measure wall-clock execution time and token usage during agent execution. Our results show that the presence of AGENTS$.$md is associated with a lower median runtime ($Δ28.64$%) and reduced output token consumption ($Δ16.58$%), while maintaining a comparable task completion behavior. Based on these results, we discuss immediate implications for the configuration and deployment of AI coding agents in practice, and outline a broader research agenda on the role of repository-level instructions in shaping the behavior, efficiency, and integration of AI coding agents in software development workflows.
Effective Code Membership Inference for Code Completion Models via Adversarial Prompts
Nov 19, 2025Membership inference attacks (MIAs) on code completion models offer an effective way to assess privacy risks by inferring whether a given code snippet was part of the training data. Existing black- and gray-box MIAs rely on expensive surrogate models or manually crafted heuristic rules, which limit their ability to capture the nuanced memorization patterns exhibited by over-parameterized code language models. To address these challenges, we propose AdvPrompt-MIA, a method specifically designed for code completion models, combining code-specific adversarial perturbations with deep learning. The core novelty of our method lies in designing a series of adversarial prompts that induce variations in the victim code model's output. By comparing these outputs with the ground-truth completion, we construct feature vectors to train a classifier that automatically distinguishes member from non-member samples. This design allows our method to capture richer memorization patterns and accurately infer training set membership. We conduct comprehensive evaluations on widely adopted models, such as Code Llama 7B, over the APPS and HumanEval benchmarks. The results show that our approach consistently outperforms state-of-the-art baselines, with AUC gains of up to 102%. In addition, our method exhibits strong transferability across different models and datasets, underscoring its practical utility and generalizability.
Walking the Tightrope of LLMs for Software Development: A Practitioners' Perspective
Nov 09, 2025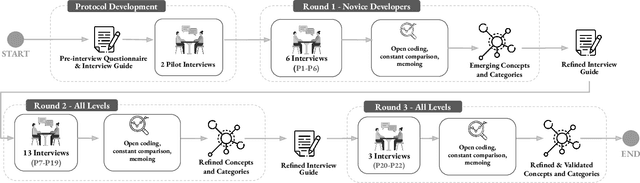
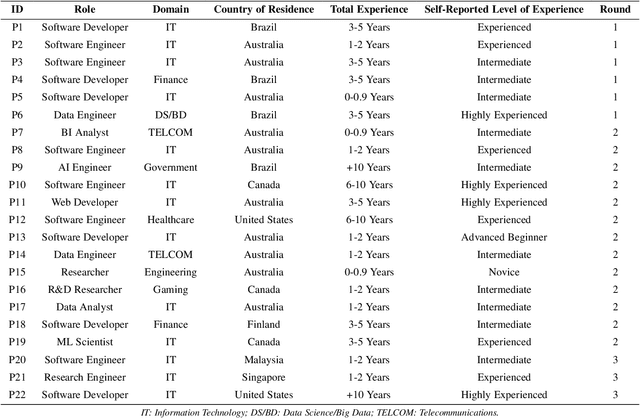

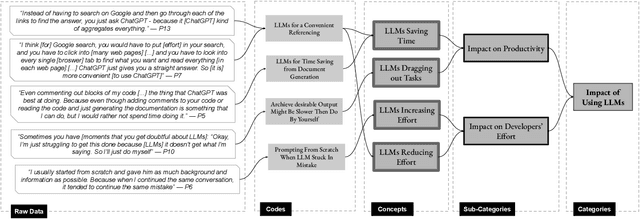
Background: Large Language Models emerged with the potential of provoking a revolution in software development (e.g., automating processes, workforce transformation). Although studies have started to investigate the perceived impact of LLMs for software development, there is a need for empirical studies to comprehend how to balance forward and backward effects of using LLMs. Objective: We investigated how LLMs impact software development and how to manage the impact from a software developer's perspective. Method: We conducted 22 interviews with software practitioners across 3 rounds of data collection and analysis, between October (2024) and September (2025). We employed socio-technical grounded theory (STGT) for data analysis to rigorously analyse interview participants' responses. Results: We identified the benefits (e.g., maintain software development flow, improve developers' mental model, and foster entrepreneurship) and disadvantages (e.g., negative impact on developers' personality and damage to developers' reputation) of using LLMs at individual, team, organisation, and society levels; as well as best practices on how to adopt LLMs. Conclusion: Critically, we present the trade-offs that software practitioners, teams, and organisations face in working with LLMs. Our findings are particularly useful for software team leaders and IT managers to assess the viability of LLMs within their specific context.
CodeReviewQA: The Code Review Comprehension Assessment for Large Language Models
Mar 20, 2025



State-of-the-art large language models (LLMs) have demonstrated impressive code generation capabilities but struggle with real-world software engineering tasks, such as revising source code to address code reviews, hindering their practical use. Code review comments are often implicit, ambiguous, and colloquial, requiring models to grasp both code and human intent. This challenge calls for evaluating large language models' ability to bridge both technical and conversational contexts. While existing work has employed the automated code refinement (ACR) task to resolve these comments, current evaluation methods fall short, relying on text matching metrics that provide limited insight into model failures and remain susceptible to training data contamination. To address these limitations, we introduce a novel evaluation benchmark, $\textbf{CodeReviewQA}$ that enables us to conduct fine-grained assessment of model capabilities and mitigate data contamination risks. In CodeReviewQA, we decompose the generation task of code refinement into $\textbf{three essential reasoning steps}$: $\textit{change type recognition}$ (CTR), $\textit{change localisation}$ (CL), and $\textit{solution identification}$ (SI). Each step is reformulated as multiple-choice questions with varied difficulty levels, enabling precise assessment of model capabilities, while mitigating data contamination risks. Our comprehensive evaluation spans 72 recently released large language models on $\textbf{900 manually curated, high-quality examples}$ across nine programming languages. Our results show that CodeReviewQA is able to expose specific model weaknesses in code review comprehension, disentangled from their generative automated code refinement results.
Enhancing High-Quality Code Generation in Large Language Models with Comparative Prefix-Tuning
Mar 12, 2025Large Language Models (LLMs) have been widely adopted in commercial code completion engines, significantly enhancing coding efficiency and productivity. However, LLMs may generate code with quality issues that violate coding standards and best practices, such as poor code style and maintainability, even when the code is functionally correct. This necessitates additional effort from developers to improve the code, potentially negating the efficiency gains provided by LLMs. To address this problem, we propose a novel comparative prefix-tuning method for controllable high-quality code generation. Our method introduces a single, property-specific prefix that is prepended to the activations of the LLM, serving as a lightweight alternative to fine-tuning. Unlike existing methods that require training multiple prefixes, our approach trains only one prefix and leverages pairs of high-quality and low-quality code samples, introducing a sequence-level ranking loss to guide the model's training. This comparative approach enables the model to better understand the differences between high-quality and low-quality code, focusing on aspects that impact code quality. Additionally, we design a data construction pipeline to collect and annotate pairs of high-quality and low-quality code, facilitating effective training. Extensive experiments on the Code Llama 7B model demonstrate that our method improves code quality by over 100% in certain task categories, while maintaining functional correctness. We also conduct ablation studies and generalization experiments, confirming the effectiveness of our method's components and its strong generalization capability.
Junior Software Developers' Perspectives on Adopting LLMs for Software Engineering: a Systematic Literature Review
Mar 10, 2025Many studies exploring the adoption of Large Language Model-based tools for software development by junior developers have emerged in recent years. These studies have sought to understand developers' perspectives about using those tools, a fundamental pillar for successfully adopting LLM-based tools in Software Engineering. The aim of this paper is to provide an overview of junior software developers' perspectives and use of LLM-based tools for software engineering (LLM4SE). We conducted a systematic literature review (SLR) following guidelines by Kitchenham et al. on 56 primary studies, applying the definition for junior software developers as software developers with equal or less than five years of experience, including Computer Science/Software Engineering students. We found that the majority of the studies focused on comprehending the different aspects of integrating AI tools in SE. Only 8.9\% of the studies provide a clear definition for junior software developers, and there is no uniformity. Searching for relevant information is the most common task using LLM tools. ChatGPT was the most common LLM tool present in the studies (and experiments). A majority of the studies (83.9\%) report both positive and negative perceptions about the impact of adopting LLM tools. We also found and categorised advantages, challenges, and recommendations regarding LLM adoption. Our results indicate that developers are using LLMs not just for code generation, but also to improve their development skills. Critically, they are not just experiencing the benefits of adopting LLM tools, but they are also aware of at least a few LLM limitations, such as the generation of wrong suggestions, potential data leaking, and AI hallucination. Our findings offer implications for software engineering researchers, educators, and developers.
Generative AI and Empirical Software Engineering: A Paradigm Shift
Feb 12, 2025
The widespread adoption of generative AI in software engineering marks a paradigm shift, offering new opportunities to design and utilize software engineering tools while influencing both developers and the artifacts they create. Traditional empirical methods in software engineering, including quantitative, qualitative, and mixed-method approaches, are well established. However, this paradigm shift introduces novel data types and redefines many concepts in the software engineering process. The roles of developers, users, agents, and researchers increasingly overlap, blurring the distinctions between these social and technical actors within the field. This paper examines how integrating AI into software engineering challenges traditional research paradigms. It focuses on the research phenomena that we investigate, the methods and theories that we employ, the data we analyze, and the threats to validity that emerge in this new context. Through this exploration, our goal is to understand how AI adoption disrupts established software development practices that creates new opportunities for empirical software engineering research.
How Developers Interact with AI: A Taxonomy of Human-AI Collaboration in Software Engineering
Jan 15, 2025Artificial intelligence (AI), including large language models and generative AI, is emerging as a significant force in software development, offering developers powerful tools that span the entire development lifecycle. Although software engineering research has extensively studied AI tools in software development, the specific types of interactions between developers and these AI-powered tools have only recently begun to receive attention. Understanding and improving these interactions has the potential to improve productivity, trust, and efficiency in AI-driven workflows. In this paper, we propose a taxonomy of interaction types between developers and AI tools, identifying eleven distinct interaction types, such as auto-complete code suggestions, command-driven actions, and conversational assistance. Building on this taxonomy, we outline a research agenda focused on optimizing AI interactions, improving developer control, and addressing trust and usability challenges in AI-assisted development. By establishing a structured foundation for studying developer-AI interactions, this paper aims to stimulate research on creating more effective, adaptive AI tools for software development.
Can LLMs Replace Manual Annotation of Software Engineering Artifacts?
Aug 10, 2024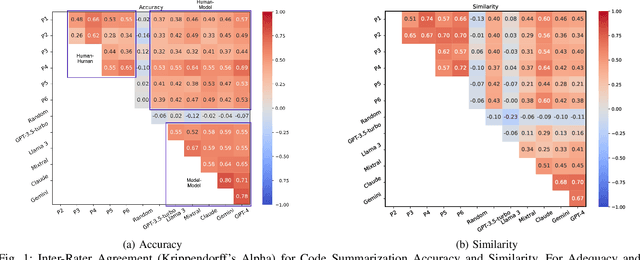
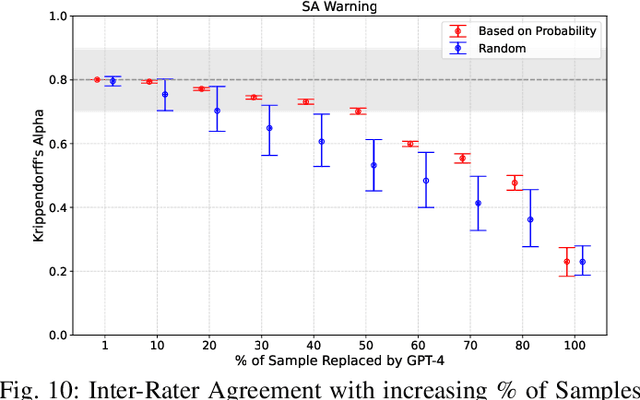
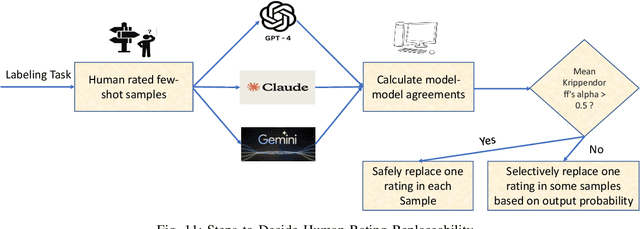
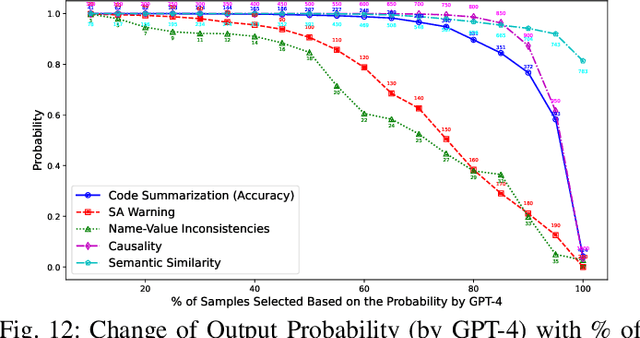
Experimental evaluations of software engineering innovations, e.g., tools and processes, often include human-subject studies as a component of a multi-pronged strategy to obtain greater generalizability of the findings. However, human-subject studies in our field are challenging, due to the cost and difficulty of finding and employing suitable subjects, ideally, professional programmers with varying degrees of experience. Meanwhile, large language models (LLMs) have recently started to demonstrate human-level performance in several areas. This paper explores the possibility of substituting costly human subjects with much cheaper LLM queries in evaluations of code and code-related artifacts. We study this idea by applying six state-of-the-art LLMs to ten annotation tasks from five datasets created by prior work, such as judging the accuracy of a natural language summary of a method or deciding whether a code change fixes a static analysis warning. Our results show that replacing some human annotation effort with LLMs can produce inter-rater agreements equal or close to human-rater agreement. To help decide when and how to use LLMs in human-subject studies, we propose model-model agreement as a predictor of whether a given task is suitable for LLMs at all, and model confidence as a means to select specific samples where LLMs can safely replace human annotators. Overall, our work is the first step toward mixed human-LLM evaluations in software engineering.
The Impact Of Bug Localization Based on Crash Report Mining: A Developers' Perspective
Mar 16, 2024Developers often use crash reports to understand the root cause of bugs. However, locating the buggy source code snippet from such information is a challenging task, mainly when the log database contains many crash reports. To mitigate this issue, recent research has proposed and evaluated approaches for grouping crash report data and using stack trace information to locate bugs. The effectiveness of such approaches has been evaluated by mainly comparing the candidate buggy code snippets with the actual changed code in bug-fix commits -- which happens in the context of retrospective repository mining studies. Therefore, the existing literature still lacks discussing the use of such approaches in the daily life of a software company, which could explain the developers' perceptions on the use of these approaches. In this paper, we report our experience of using an approach for grouping crash reports and finding buggy code on a weekly basis for 18 months, within three development teams in a software company. We grouped over 750,000 crash reports, opened over 130 issues, and collected feedback from 18 developers and team leaders. Among other results, we observe that the amount of system logs related to a crash report group is not the only criteria developers use to choose a candidate bug to be analyzed. Instead, other factors were considered, such as the need to deliver customer-prioritized features and the difficulty of solving complex crash reports (e.g., architectural debts), to cite some. The approach investigated in this study correctly suggested the buggy file most of the time -- the approach's precision was around 80%. In this study, the developers also shared their perspectives on the usefulness of the suspicious files and methods extracted from crash reports to fix related bugs.