 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillScope: A Tool to Predict Fine-Grained Skills Needed to Solve Issues on GitHub
Jan 27, 2025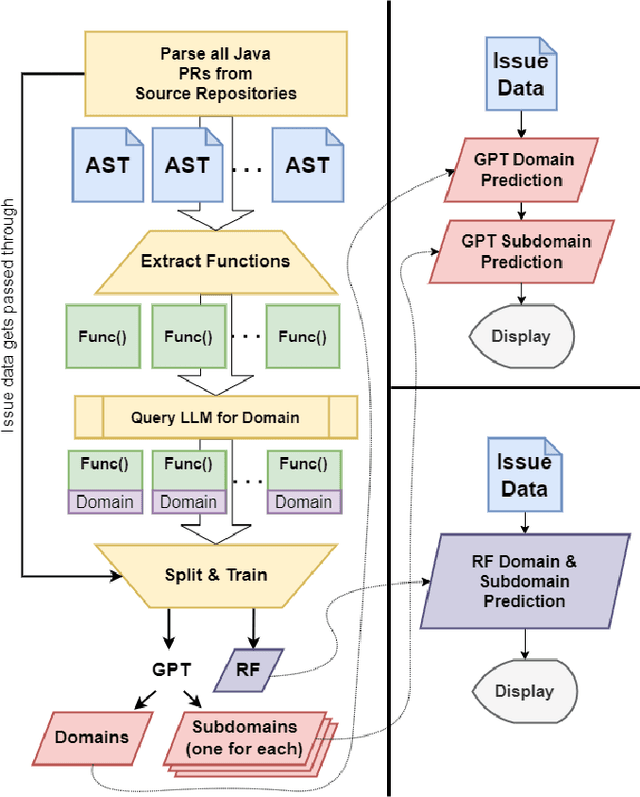
New contributors often struggle to find tasks that they can tackle when onboarding onto a new Open Source Software (OSS) project. One reason for this difficulty is that issue trackers lack explanations about the knowledge or skills needed to complete a given task successfully. These explanations can be complex and time-consuming to produce. Past research has partially addressed this problem by labeling issues with issue types, issue difficulty level, and issue skills. However, current approaches are limited to a small set of labels and lack in-depth details about their semantics, which may not sufficiently help contributors identify suitable issues. To surmount this limitation, this paper explores large language models (LLMs) and Random Forest (RF) to predict the multilevel skills required to solve the open issues. We introduce a novel tool, SkillScope, which retrieves current issues from Java projects hosted on GitHub and predicts the multilevel programming skills required to resolve these issues. In a case study, we demonstrate that SkillScope could predict 217 multilevel skills for tasks with 91% precision, 88% recall, and 89% F-measure on average. Practitioners can use this tool to better delegate or choose tasks to solve in OSS projects.
How Developers Interact with AI: A Taxonomy of Human-AI Collaboration in Software Engineering
Jan 15, 2025
Artificial intelligence (AI), including large language models and generative AI, is emerging as a significant force in software development, offering developers powerful tools that span the entire development lifecycle. Although software engineering research has extensively studied AI tools in software development, the specific types of interactions between developers and these AI-powered tools have only recently begun to receive attention. Understanding and improving these interactions has the potential to improve productivity, trust, and efficiency in AI-driven workflows. In this paper, we propose a taxonomy of interaction types between developers and AI tools, identifying eleven distinct interaction types, such as auto-complete code suggestions, command-driven actions, and conversational assistance. Building on this taxonomy, we outline a research agenda focused on optimizing AI interactions, improving developer control, and addressing trust and usability challenges in AI-assisted development. By establishing a structured foundation for studying developer-AI interactions, this paper aims to stimulate research on creating more effective, adaptive AI tools for software development.
Applying Large Language Models API to Issue Classification Problem
Jan 09, 2024Effective prioritization of issue reports is crucial in software engineering to optimize resource allocation and address critical problems promptly. However, the manual classification of issue reports for prioritization is laborious and lacks scalability. Alternatively, many open source software (OSS) projects employ automated processes for this task, albeit relying on substantial datasets for adequate training. This research seeks to devise an automated approach that ensures reliability in issue prioritization, even when trained on smaller datasets. Our proposed methodology harnesses the power of Generative Pre-trained Transformers (GPT), recognizing their potential to efficiently handle this task. By leveraging the capabilities of such models, we aim to develop a robust system for prioritizing issue reports accurately, mitigating the necessity for extensive training data while maintaining reliability. In our research, we have developed a reliable GPT-based approach to accurately label and prioritize issue reports with a reduced training dataset. By reducing reliance on massive data requirements and focusing on few-shot fine-tuning, our methodology offers a more accessible and efficient solution for issue prioritization in software engineering. Our model predicted issue types in individual projects up to 93.2% in precision, 95% in recall, and 89.3% in F1-score.
Anticipating User Needs: Insights from Design Fiction on Conversational Agents for Computational Thinking
Nov 12, 2023Computational thinking, and by extension, computer programming, is notoriously challenging to learn. Conversational agents and generative artificial intelligence (genAI) have the potential to facilitate this learning process by offering personalized guidance, interactive learning experiences, and code generation. However, current genAI-based chatbots focus on professional developers and may not adequately consider educational needs. Involving educators in conceiving educational tools is critical for ensuring usefulness and usability. We enlisted \numParticipants{} instructors to engage in design fiction sessions in which we elicited abilities such a conversational agent supported by genAI should display. Participants envisioned a conversational agent that guides students stepwise through exercises, tuning its method of guidance with an awareness of the educational background, skills and deficits, and learning preferences. The insights obtained in this paper can guide future implementations of tutoring conversational agents oriented toward teaching computational thinking and computer programming.
Tag that issue: Applying API-domain labels in issue tracking systems
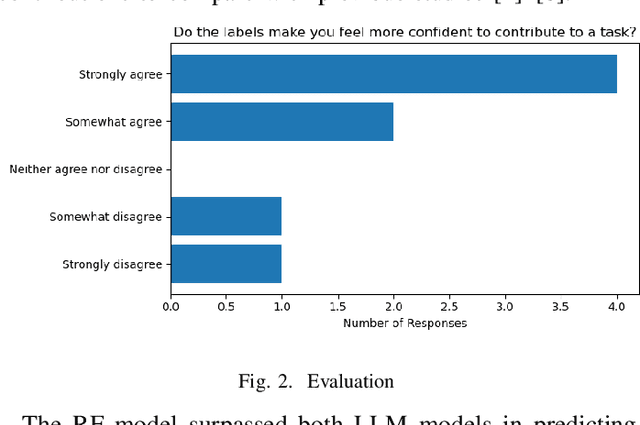
Apr 06, 2023Labeling issues with the skills required to complete them can help contributors to choose tasks in Open Source Software projects. However, manually labeling issues is time-consuming and error-prone, and current automated approaches are mostly limited to classifying issues as bugs/non-bugs. We investigate the feasibility and relevance of automatically labeling issues with what we call "API-domains," which are high-level categories of APIs. Therefore, we posit that the APIs used in the source code affected by an issue can be a proxy for the type of skills (e.g., DB, security, UI) needed to work on the issue. We ran a user study (n=74) to assess API-domain labels' relevancy to potential contributors, leveraged the issues' descriptions and the project history to build prediction models, and validated the predictions with contributors (n=20) of the projects. Our results show that (i) newcomers to the project consider API-domain labels useful in choosing tasks, (ii) labels can be predicted with a precision of 84% and a recall of 78.6% on average, (iii) the results of the predictions reached up to 71.3% in precision and 52.5% in recall when training with a project and testing in another (transfer learning), and (iv) project contributors consider most of the predictions helpful in identifying needed skills. These findings suggest our approach can be applied in practice to automatically label issues, assisting developers in finding tasks that better match their skills.
GiveMeLabeledIssues: An Open Source Issue Recommendation System
Mar 23, 2023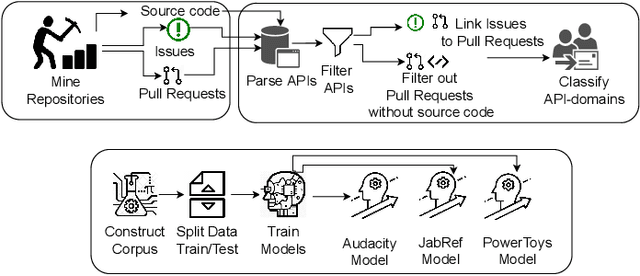


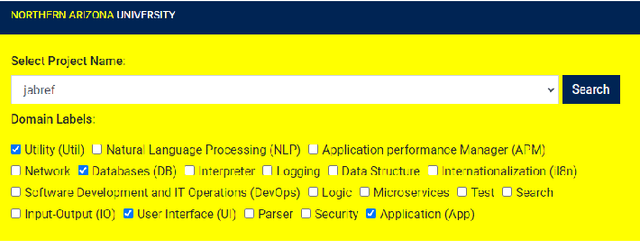
Developers often struggle to navigate an Open Source Software (OSS) project's issue-tracking system and find a suitable task. Proper issue labeling can aid task selection, but current tools are limited to classifying the issues according to their type (e.g., bug, question, good first issue, feature, etc.). In contrast, this paper presents a tool (GiveMeLabeledIssues) that mines project repositories and labels issues based on the skills required to solve them. We leverage the domain of the APIs involved in the solution (e.g., User Interface (UI), Test, Databases (DB), etc.) as a proxy for the required skills. GiveMeLabeledIssues facilitates matching developers' skills to tasks, reducing the burden on project maintainers. The tool obtained a precision of 83.9% when predicting the API domains involved in the issues. The replication package contains instructions on executing the tool and including new projects. A demo video is available at https://www.youtube.com/watch?v=ic2quUue7i8
The Present and Future of Bots in Software Engineering
Jul 04, 2022We are witnessing a massive adoption of software engineering bots, applications that react to events triggered by tools and messages posted by users and run automated tasks in response, in a variety of domains. This thematic issues describes experiences and challenges with these bots.
CoNCRA: A Convolutional Neural Network Code Retrieval Approach
Sep 03, 2020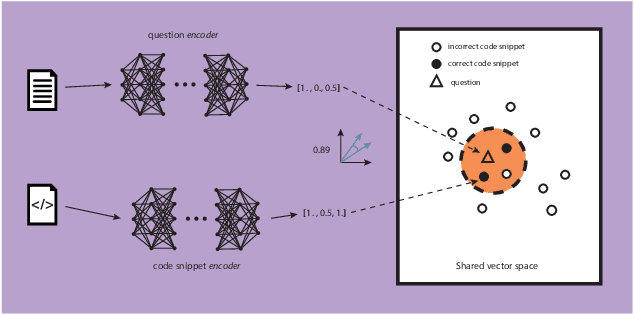


Software developers routinely search for code using general-purpose search engines. However, these search engines cannot find code semantically unless it has an accompanying description. We propose a technique for semantic code search: A Convolutional Neural Network approach to code retrieval (CoNCRA). Our technique aims to find the code snippet that most closely matches the developer's intent, expressed in natural language. We evaluated our approach's efficacy on a dataset composed of questions and code snippets collected from Stack Overflow. Our preliminary results showed that our technique, which prioritizes local interactions (words nearby), improved the state-of-the-art (SOTA) by 5% on average, retrieving the most relevant code snippets in the top 3 (three) positions by almost 80% of the time. Therefore, our technique is promising and can improve the efficacy of semantic code retrieval.