 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Invariance in Agentic AI
Mar 16, 2026Large Language Models (LLMs) increasingly serve as autonomous reasoning agents in decision support, scientific problem-solving, and multi-agent coordination systems. However, deploying LLM agents in consequential applications requires assurance that their reasoning remains stable under semantically equivalent input variations, a property we term semantic invariance. Standard benchmark evaluations, which assess accuracy on fixed, canonical problem formulations, fail to capture this critical reliability dimension. To address this shortcoming, in this paper we present a metamorphic testing framework for systematically assessing the robustness of LLM reasoning agents, applying eight semantic-preserving transformations (identity, paraphrase, fact reordering, expansion, contraction, academic context, business context, and contrastive formulation) across seven foundation models spanning four distinct architectural families: Hermes (70B, 405B), Qwen3 (30B-A3B, 235B-A22B), DeepSeek-R1, and gpt-oss (20B, 120B). Our evaluation encompasses 19 multi-step reasoning problems across eight scientific domains. The results reveal that model scale does not predict robustness: the smaller Qwen3-30B-A3B achieves the highest stability (79.6% invariant responses, semantic similarity 0.91), while larger models exhibit greater fragility.
On the use of LLMs to generate a dataset of Neural Networks
Feb 04, 2026Neural networks are increasingly used to support decision-making. To verify their reliability and adaptability, researchers and practitioners have proposed a variety of tools and methods for tasks such as NN code verification, refactoring, and migration. These tools play a crucial role in guaranteeing both the correctness and maintainability of neural network architectures, helping to prevent implementation errors, simplify model updates, and ensure that complex networks can be reliably extended and reused. Yet, assessing their effectiveness remains challenging due to the lack of publicly diverse datasets of neural networks that would allow systematic evaluation. To address this gap, we leverage large language models (LLMs) to automatically generate a dataset of neural networks that can serve as a benchmark for validation. The dataset is designed to cover diverse architectural components and to handle multiple input data types and tasks. In total, 608 samples are generated, each conforming to a set of precise design choices. To further ensure their consistency, we validate the correctness of the generated networks using static analysis and symbolic tracing. We make the dataset publicly available to support the community in advancing research on neural network reliability and adaptability.
Cross-Platform Evaluation of Reasoning Capabilities in Foundation Models
Oct 30, 2025This paper presents a comprehensive cross-platform evaluation of reasoning capabilities in contemporary foundation models, establishing an infrastructure-agnostic benchmark across three computational paradigms: HPC supercomputing (MareNostrum 5), cloud platforms (Nebius AI Studio), and university clusters (a node with eight H200 GPUs). We evaluate 15 foundation models across 79 problems spanning eight academic domains (Physics, Mathematics, Chemistry, Economics, Biology, Statistics, Calculus, and Optimization) through three experimental phases: (1) Baseline establishment: Six models (Mixtral-8x7B, Phi-3, LLaMA 3.1-8B, Gemma-2-9b, Mistral-7B, OLMo-7B) evaluated on 19 problems using MareNostrum 5, establishing methodology and reference performance; (2) Infrastructure validation: The 19-problem benchmark repeated on university cluster (seven models including Falcon-Mamba state-space architecture) and Nebius AI Studio (nine state-of-the-art models: Hermes-4 70B/405B, LLaMA 3.1-405B/3.3-70B, Qwen3 30B/235B, DeepSeek-R1, GPT-OSS 20B/120B) to confirm infrastructure-agnostic reproducibility; (3) Extended evaluation: Full 79-problem assessment on both university cluster and Nebius platforms, probing generalization at scale across architectural diversity. The findings challenge conventional scaling assumptions, establish training data quality as more critical than model size, and provide actionable guidelines for model selection across educational, production, and research contexts. The tri-infrastructure methodology and 79-problem benchmark enable longitudinal tracking of reasoning capabilities as foundation models evolve.
Low-code to fight climate change: the Climaborough project
Jun 17, 2025

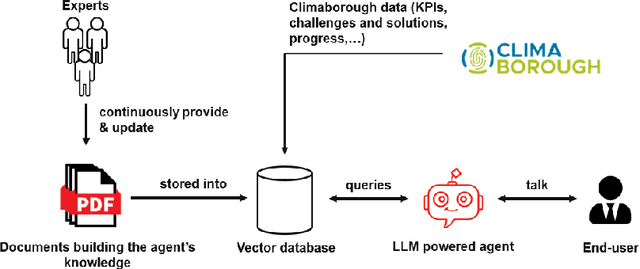
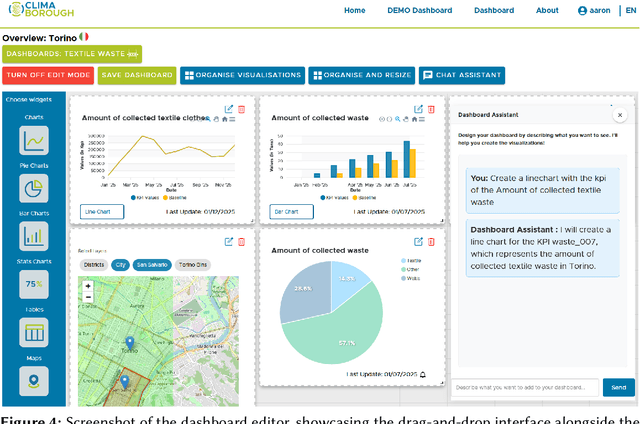
The EU-funded Climaborough project supports European cities to achieve carbon neutrality by 2030. Eleven cities in nine countries will deploy in real conditions products and services fostering climate transition in their local environment. The Climaborough City Platform is being developed to monitor the cities' overall progress towards their climate goals by aggregating historic and real-time data and displaying the results in user-friendly dashboards that will be used by non-technical experts to evaluate the effectiveness of local experimental initiatives, identify those that yield significant impact, and assess the potential consequences of scaling them up to a broader level. In this paper, we explain how we have put in place a low-code/no-code strategy in Climaborough in response to the project's aim to quickly deploy climate dashboards. A low-code strategy is used to accelerate the development of the dashboards. The dashboards embed a no-code philosophy that enables all types of citizen profiles to configure and adapt the dashboard to their specific needs.
Mind the Language Gap: Automated and Augmented Evaluation of Bias in LLMs for High- and Low-Resource Languages
Apr 19, 2025



Large Language Models (LLMs) have exhibited impressive natural language processing capabilities but often perpetuate social biases inherent in their training data. To address this, we introduce MultiLingual Augmented Bias Testing (MLA-BiTe), a framework that improves prior bias evaluation methods by enabling systematic multilingual bias testing. MLA-BiTe leverages automated translation and paraphrasing techniques to support comprehensive assessments across diverse linguistic settings. In this study, we evaluate the effectiveness of MLA-BiTe by testing four state-of-the-art LLMs in six languages -- including two low-resource languages -- focusing on seven sensitive categories of discrimination.
Testing Low-Resource Language Support in LLMs Using Language Proficiency Exams: the Case of Luxembourgish
Apr 03, 2025
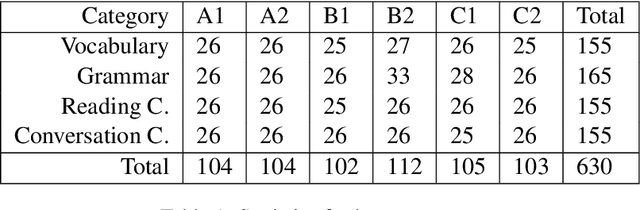
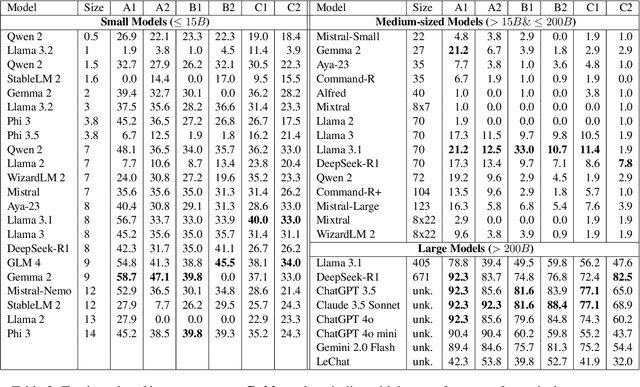
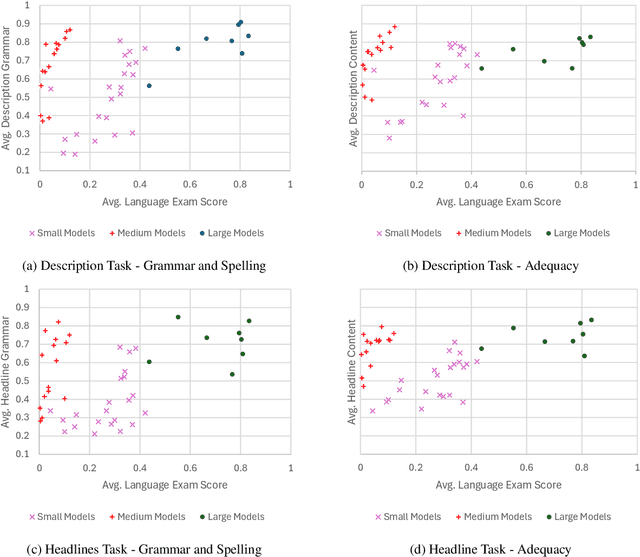
Large Language Models (LLMs) have become an increasingly important tool in research and society at large. While LLMs are regularly used all over the world by experts and lay-people alike, they are predominantly developed with English-speaking users in mind, performing well in English and other wide-spread languages while less-resourced languages such as Luxembourgish are seen as a lower priority. This lack of attention is also reflected in the sparsity of available evaluation tools and datasets. In this study, we investigate the viability of language proficiency exams as such evaluation tools for the Luxembourgish language. We find that large models such as ChatGPT, Claude and DeepSeek-R1 typically achieve high scores, while smaller models show weak performances. We also find that the performances in such language exams can be used to predict performances in other NLP tasks.
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
LangBiTe: A Platform for Testing Bias in Large Language Models
Apr 29, 2024



The integration of Large Language Models (LLMs) into various software applications raises concerns about their potential biases. Typically, those models are trained on a vast amount of data scrapped from forums, websites, social media and other internet sources, which may instill harmful and discriminating behavior into the model. To address this issue, we present LangBiTe, a testing platform to systematically assess the presence of biases within an LLM. LangBiTe enables development teams to tailor their test scenarios, and automatically generate and execute the test cases according to a set of user-defined ethical requirements. Each test consists of a prompt fed into the LLM and a corresponding test oracle that scrutinizes the LLM's response for the identification of biases. LangBite provides users with the bias evaluation of LLMs, and end-to-end traceability between the initial ethical requirements and the insights obtained.
A Framework to Model ML Engineering Processes
Apr 29, 2024


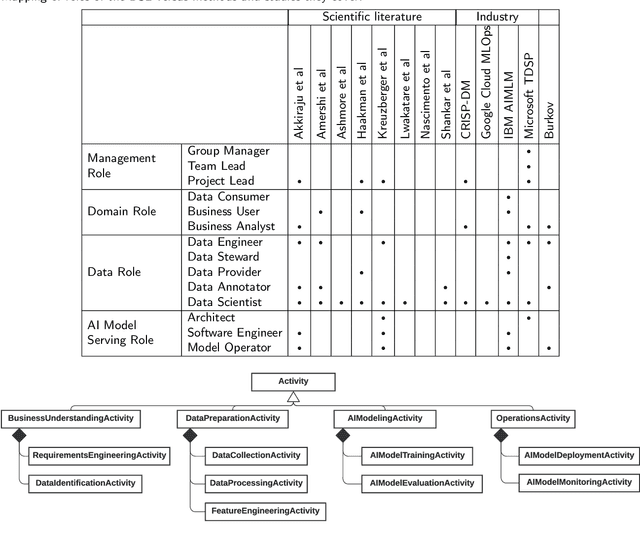
The development of Machine Learning (ML) based systems is complex and requires multidisciplinary teams with diverse skill sets. This may lead to communication issues or misapplication of best practices. Process models can alleviate these challenges by standardizing task orchestration, providing a common language to facilitate communication, and nurturing a collaborative environment. Unfortunately, current process modeling languages are not suitable for describing the development of such systems. In this paper, we introduce a framework for modeling ML-based software development processes, built around a domain-specific language and derived from an analysis of scientific and gray literature. A supporting toolkit is also available.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024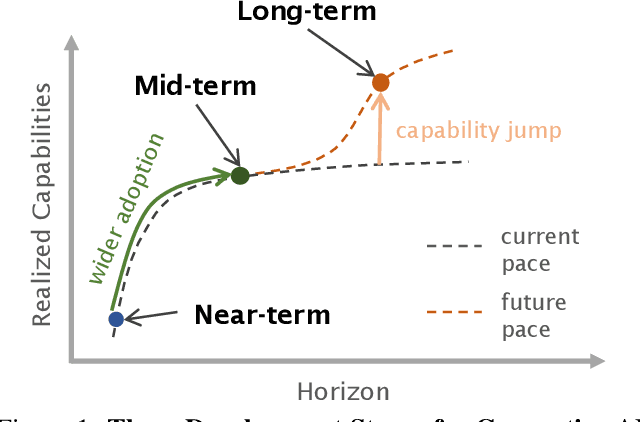
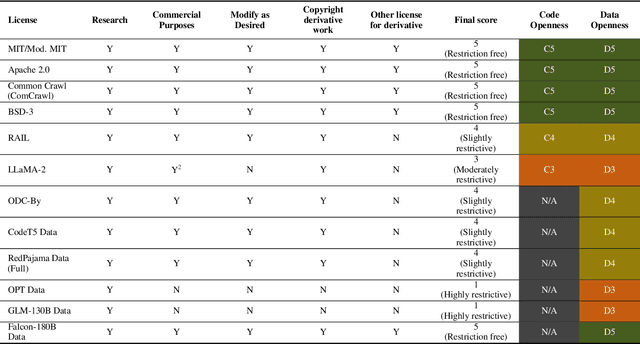
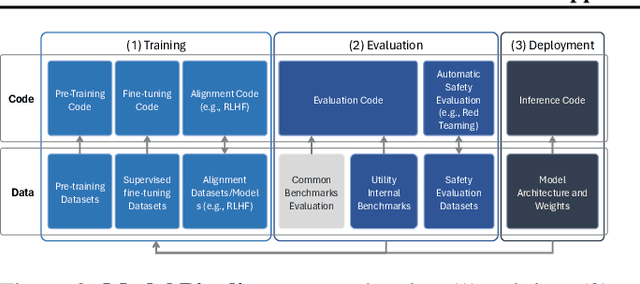
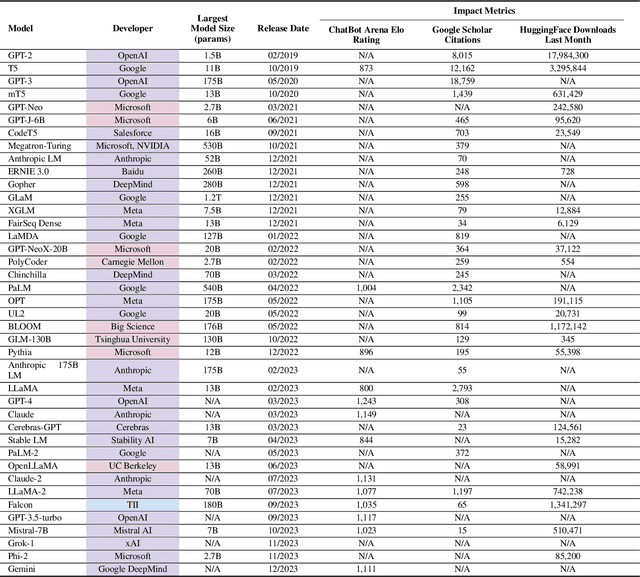
In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.