 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Language Gap: Automated and Augmented Evaluation of Bias in LLMs for High- and Low-Resource Languages
Apr 19, 2025Large Language Models (LLMs) have exhibited impressive natural language processing capabilities but often perpetuate social biases inherent in their training data. To address this, we introduce MultiLingual Augmented Bias Testing (MLA-BiTe), a framework that improves prior bias evaluation methods by enabling systematic multilingual bias testing. MLA-BiTe leverages automated translation and paraphrasing techniques to support comprehensive assessments across diverse linguistic settings. In this study, we evaluate the effectiveness of MLA-BiTe by testing four state-of-the-art LLMs in six languages -- including two low-resource languages -- focusing on seven sensitive categories of discrimination.
LangBiTe: A Platform for Testing Bias in Large Language Models
Apr 29, 2024



The integration of Large Language Models (LLMs) into various software applications raises concerns about their potential biases. Typically, those models are trained on a vast amount of data scrapped from forums, websites, social media and other internet sources, which may instill harmful and discriminating behavior into the model. To address this issue, we present LangBiTe, a testing platform to systematically assess the presence of biases within an LLM. LangBiTe enables development teams to tailor their test scenarios, and automatically generate and execute the test cases according to a set of user-defined ethical requirements. Each test consists of a prompt fed into the LLM and a corresponding test oracle that scrutinizes the LLM's response for the identification of biases. LangBite provides users with the bias evaluation of LLMs, and end-to-end traceability between the initial ethical requirements and the insights obtained.
A Framework to Model ML Engineering Processes
Apr 29, 2024


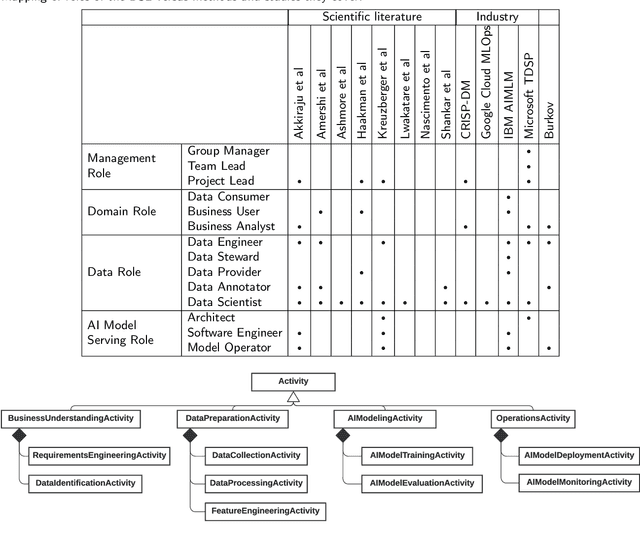
The development of Machine Learning (ML) based systems is complex and requires multidisciplinary teams with diverse skill sets. This may lead to communication issues or misapplication of best practices. Process models can alleviate these challenges by standardizing task orchestration, providing a common language to facilitate communication, and nurturing a collaborative environment. Unfortunately, current process modeling languages are not suitable for describing the development of such systems. In this paper, we introduce a framework for modeling ML-based software development processes, built around a domain-specific language and derived from an analysis of scientific and gray literature. A supporting toolkit is also available.
Towards the Automatic Generation of Conversational Interfaces to Facilitate the Exploration of Tabular Data
May 24, 2023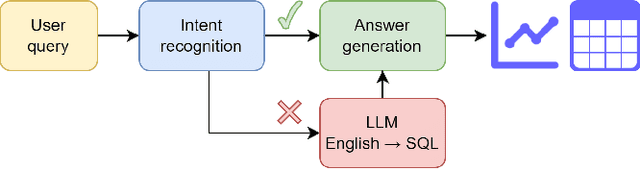
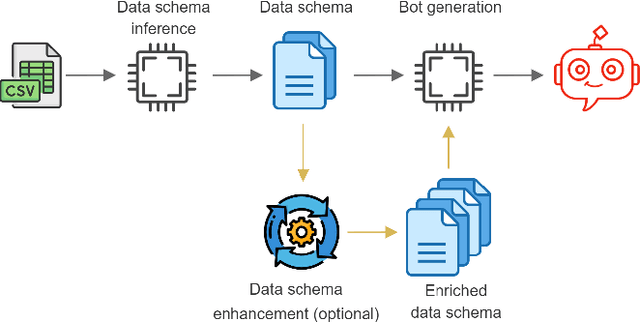
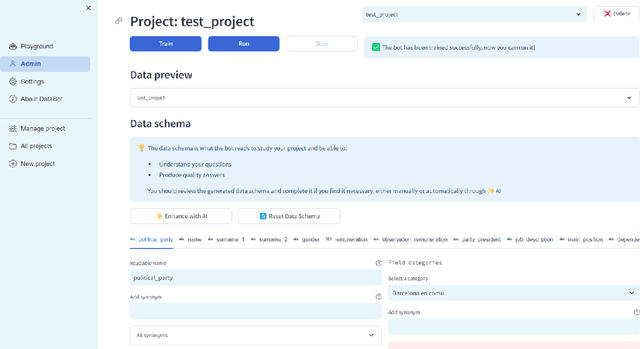
Tabular data is the most common format to publish and exchange structured data online. A clear example is the growing number of open data portals published by all types of public administrations. However, exploitation of these data sources is currently limited to technical people able to programmatically manipulate and digest such data. As an alternative, we propose the use of chatbots to offer a conversational interface to facilitate the exploration of tabular data sources. With our approach, any regular citizen can benefit and leverage them. Moreover, our chatbots are not manually created: instead, they are automatically generated from the data source itself thanks to the instantiation of a configurable collection of conversation patterns.