 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Low-Resource Language Support in LLMs Using Language Proficiency Exams: the Case of Luxembourgish
Apr 03, 2025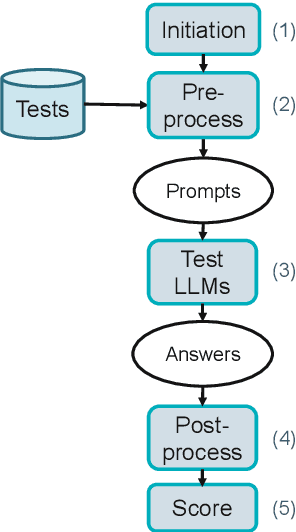
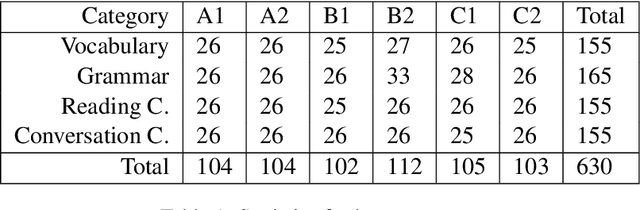
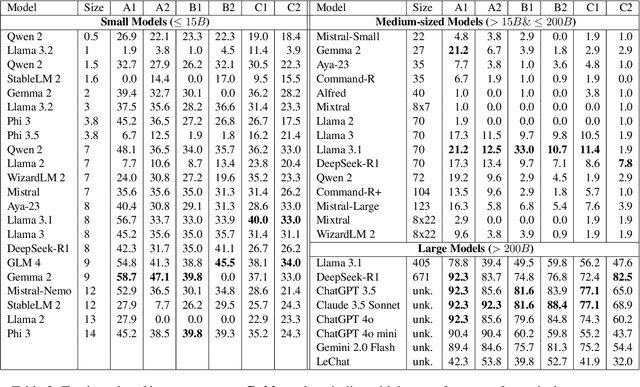
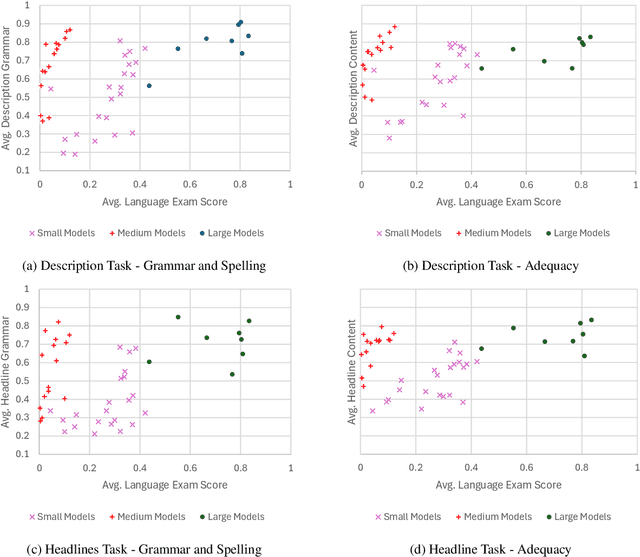
Large Language Models (LLMs) have become an increasingly important tool in research and society at large. While LLMs are regularly used all over the world by experts and lay-people alike, they are predominantly developed with English-speaking users in mind, performing well in English and other wide-spread languages while less-resourced languages such as Luxembourgish are seen as a lower priority. This lack of attention is also reflected in the sparsity of available evaluation tools and datasets. In this study, we investigate the viability of language proficiency exams as such evaluation tools for the Luxembourgish language. We find that large models such as ChatGPT, Claude and DeepSeek-R1 typically achieve high scores, while smaller models show weak performances. We also find that the performances in such language exams can be used to predict performances in other NLP tasks.
Is LLM the Silver Bullet to Low-Resource Languages Machine Translation?
Mar 31, 2025
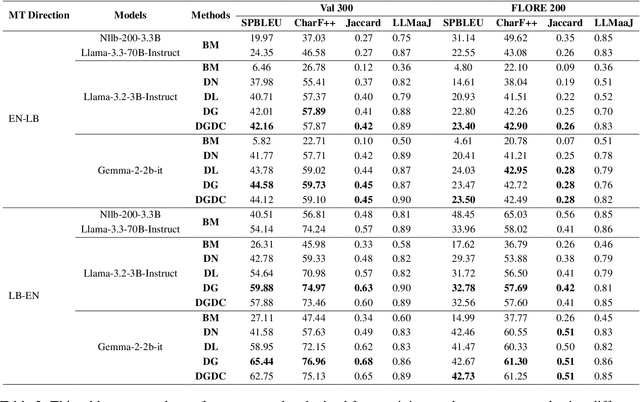
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.
Enhancing Small Language Models for Cross-Lingual Generalized Zero-Shot Classification with Soft Prompt Tuning
Mar 25, 2025In NLP, Zero-Shot Classification (ZSC) has become essential for enabling models to classify text into categories unseen during training, particularly in low-resource languages and domains where labeled data is scarce. While pretrained language models (PLMs) have shown promise in ZSC, they often rely on large training datasets or external knowledge, limiting their applicability in multilingual and low-resource scenarios. Recent approaches leveraging natural language prompts reduce the dependence on large training datasets but struggle to effectively incorporate available labeled data from related classification tasks, especially when these datasets originate from different languages or distributions. Moreover, existing prompt-based methods typically rely on manually crafted prompts in a specific language, limiting their adaptability and effectiveness in cross-lingual settings. To address these challenges, we introduce RoSPrompt, a lightweight and data-efficient approach for training soft prompts that enhance cross-lingual ZSC while ensuring robust generalization across data distribution shifts. RoSPrompt is designed for small multilingual PLMs, enabling them to leverage high-resource languages to improve performance in low-resource settings without requiring extensive fine-tuning or high computational costs. We evaluate our approach on multiple multilingual PLMs across datasets covering 106 languages, demonstrating strong cross-lingual transfer performance and robust generalization capabilities over unseen classes.
CallNavi: A Study and Challenge on Function Calling Routing and Invocation in Large Language Models
Jan 09, 2025
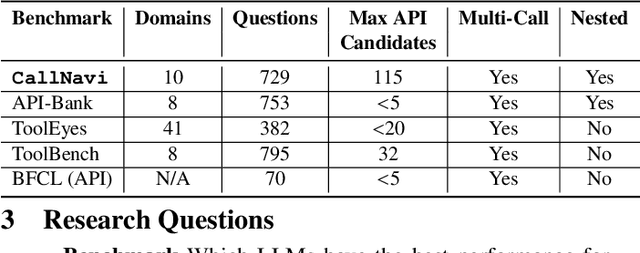


Interacting with a software system via a chatbot can be challenging, especially when the chatbot needs to generate API calls, in the right order and with the right parameters, to communicate with the system. API calling in chatbot systems poses significant challenges, particularly in complex, multi-step tasks requiring accurate API selection and execution. We contribute to this domain in three ways: first, by introducing a novel dataset designed to assess models on API function selection, parameter generation, and nested API calls; second, by benchmarking state-of-the-art language models across varying levels of complexity to evaluate their performance in API function generation and parameter accuracy; and third, by proposing an enhanced API routing method that combines general-purpose large language models for API selection with fine-tuned models for parameter generation and some prompt engineering approach. These approaches lead to substantial improvements in handling complex API tasks, offering practical advancements for real-world API-driven chatbot systems.
Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance
Apr 12, 2024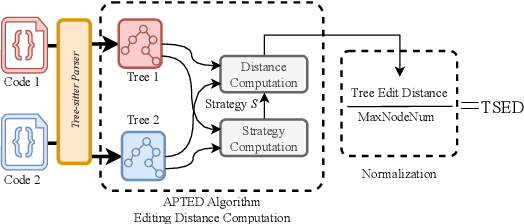
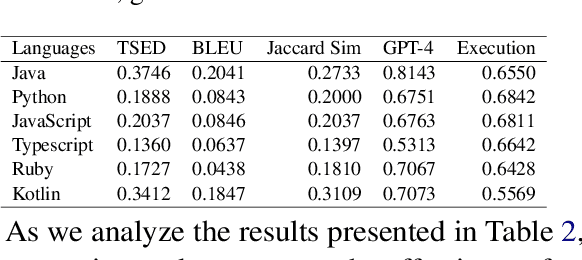
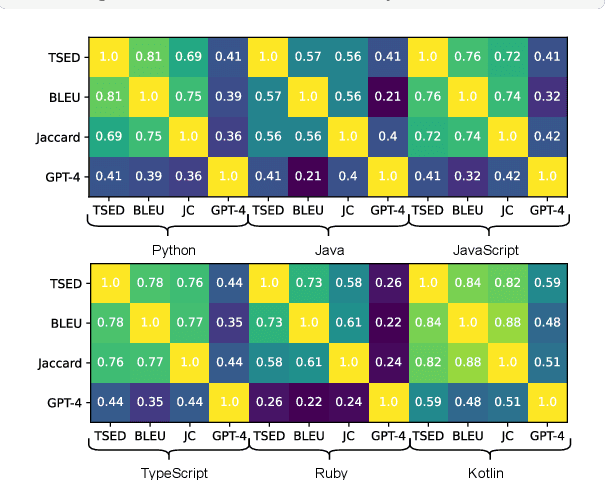
This paper revisits recent code similarity evaluation metrics, particularly focusing on the application of Abstract Syntax Tree (AST) editing distance in diverse programming languages. In particular, we explore the usefulness of these metrics and compare them to traditional sequence similarity metrics. Our experiments showcase the effectiveness of AST editing distance in capturing intricate code structures, revealing a high correlation with established metrics. Furthermore, we explore the strengths and weaknesses of AST editing distance and prompt-based GPT similarity scores in comparison to BLEU score, execution match, and Jaccard Similarity. We propose, optimize, and publish an adaptable metric that demonstrates effectiveness across all tested languages, representing an enhanced version of Tree Similarity of Edit Distance (TSED).
Soft Prompt Tuning for Cross-Lingual Transfer: When Less is More
Feb 06, 2024



Soft Prompt Tuning (SPT) is a parameter-efficient method for adapting pre-trained language models (PLMs) to specific tasks by inserting learnable embeddings, or soft prompts, at the input layer of the PLM, without modifying its parameters. This paper investigates the potential of SPT for cross-lingual transfer. Unlike previous studies on SPT for cross-lingual transfer that often fine-tune both the soft prompt and the model parameters, we adhere to the original intent of SPT by keeping the model parameters frozen and only training the soft prompt. This does not only reduce the computational cost and storage overhead of full-model fine-tuning, but we also demonstrate that this very parameter efficiency intrinsic to SPT can enhance cross-lingual transfer performance to linguistically distant languages. Moreover, we explore how different factors related to the prompt, such as the length or its reparameterization, affect cross-lingual transfer performance.