 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evaluation of PDF Parsing and Chunking for Financial Question Answering with RAG
Apr 13, 2026PDF files are primarily intended for human reading rather than automated processing. In addition, the heterogeneous content of PDFs, such as text, tables, and images, poses significant challenges for parsing and information extraction. To address these difficulties, both practitioners and researchers are increasingly developing new methods, including the promising Retrieval-Augmented Generation (RAG) systems to automated PDF processing. However, there is no comprehensive study investigating how different components and design choices affect the performance of a RAG system for understanding PDFs. In this paper, we propose such a study (1) by focusing on Question Answering, a specific language understanding task, and (2) by leveraging two benchmarks from the financial domain, including TableQuest, our newly generated, publicly available benchmark. We systematically examine multiple PDF parsers and chunking strategies (with varied overlap), along with their potential synergies in preserving document structure and ensuring answer correctness. Overall, our results offer practical guidelines for building robust RAG pipelines for PDF understanding.
The Necessity of Setting Temperature in LLM-as-a-Judge
Mar 30, 2026LLM-as-a-Judge has emerged as an effective and low-cost paradigm for evaluating text quality and factual correctness. Prior studies have shown substantial agreement between LLM judges and human experts, even on tasks that are difficult to assess automatically. In practice, researchers commonly employ fixed temperature configurations during the evaluation process-with values of 0.1 and 1.0 being the most prevalent choices-a convention that is largely empirical rather than principled. However, recent researches suggest that LLM performance exhibits non-trivial sensitivity to temperature settings, that lower temperatures do not universally yield optimal outcomes, and that such effects are highly task-dependent. This raises a critical research question: does temperature influence judge performance in LLM centric evaluation? To address this, we systematically investigate the relationship between temperature and judge performance through a series of controlled experiments, and further adopt a causal inference framework within our empirical statistical analysis to rigorously examine the direct causal effect of temperature on judge behavior, offering actionable engineering insights for the design of LLM-centric evaluation pipelines.
Agent Skill Framework: Perspectives on the Potential of Small Language Models in Industrial Environments
Feb 18, 2026Agent Skill framework, now widely and officially supported by major players such as GitHub Copilot, LangChain, and OpenAI, performs especially well with proprietary models by improving context engineering, reducing hallucinations, and boosting task accuracy. Based on these observations, an investigation is conducted to determine whether the Agent Skill paradigm provides similar benefits to small language models (SLMs). This question matters in industrial scenarios where continuous reliance on public APIs is infeasible due to data-security and budget constraints requirements, and where SLMs often show limited generalization in highly customized scenarios. This work introduces a formal mathematical definition of the Agent Skill process, followed by a systematic evaluation of language models of varying sizes across multiple use cases. The evaluation encompasses two open-source tasks and a real-world insurance claims data set. The results show that tiny models struggle with reliable skill selection, while moderately sized SLMs (approximately 12B - 30B) parameters) benefit substantially from the Agent Skill approach. Moreover, code-specialized variants at around 80B parameters achieve performance comparable to closed-source baselines while improving GPU efficiency. Collectively, these findings provide a comprehensive and nuanced characterization of the capabilities and constraints of the framework, while providing actionable insights for the effective deployment of Agent Skills in SLM-centered environments.
Correctness isnt Efficiency: Runtime Memory Divergence in LLM-Generated Code
Jan 03, 2026Large language models (LLMs) can generate programs that pass unit tests, but passing tests does not guarantee reliable runtime behavior. We find that different correct solutions to the same task can show very different memory and performance patterns, which can lead to hidden operational risks. We present a framework to measure execution-time memory stability across multiple correct generations. At the solution level, we introduce Dynamic Mean Pairwise Distance (DMPD), which uses Dynamic Time Warping to compare the shapes of memory-usage traces after converting them into Monotonic Peak Profiles (MPPs) to reduce transient noise. Aggregating DMPD across tasks yields a model-level Model Instability Score (MIS). Experiments on BigOBench and CodeContests show substantial runtime divergence among correct solutions. Instability often increases with higher sampling temperature even when pass@1 improves. We also observe correlations between our stability measures and software engineering indicators such as cognitive and cyclomatic complexity, suggesting links between operational behavior and maintainability. Our results support stability-aware selection among passing candidates in CI/CD to reduce operational risk without sacrificing correctness. Artifacts are available.
Dynamic Stability of LLM-Generated Code
Nov 07, 2025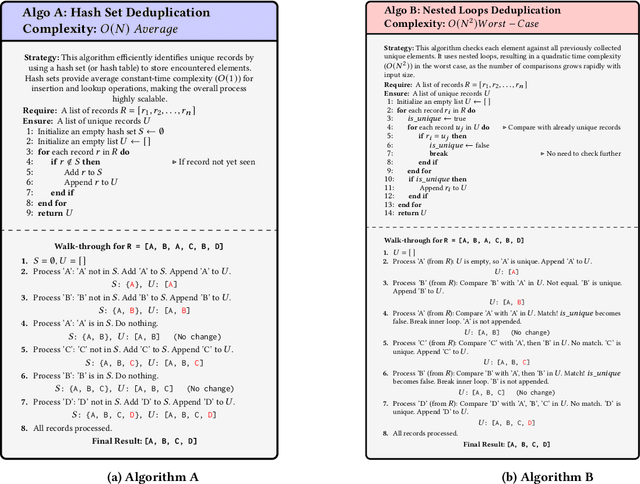
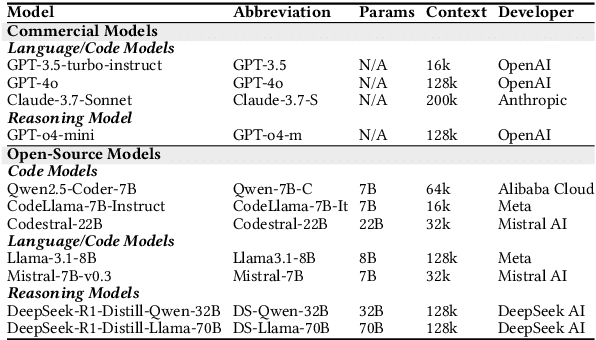
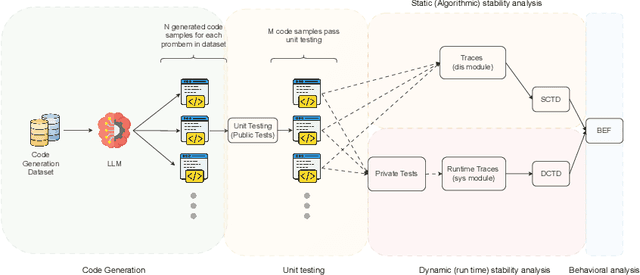
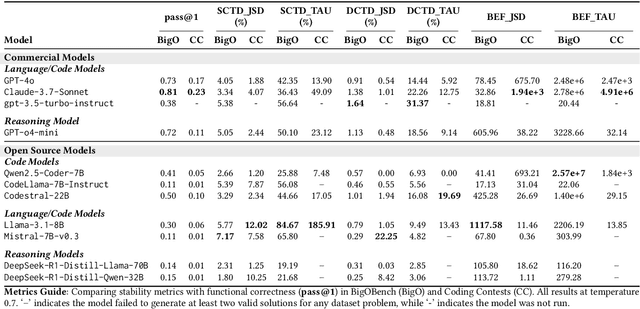
Current evaluations of LLMs for code generation emphasize functional correctness, overlooking the fact that functionally correct solutions can differ significantly in algorithmic complexity. For instance, an $(O(n^2))$ versus $(O(n \log n))$ sorting algorithm may yield similar output but incur vastly different performance costs in production. This discrepancy reveals a critical limitation in current evaluation methods: they fail to capture the behavioral and performance diversity among correct solutions. To address this, we introduce a principled framework for evaluating the dynamic stability of generated code. We propose two metrics derived from opcode distributions: Static Canonical Trace Divergence (SCTD), which captures algorithmic structure diversity across generated solutions, and Dynamic Canonical Trace Divergence (DCTD), which quantifies runtime behavioral variance. Their ratio, the Behavioral Expression Factor (BEF), serves as a diagnostic signal: it indicates critical runtime instability when BEF $\ll$ 1 and functional redundancy when BEF $\gg$ 1. Empirical results on BigOBench and CodeContests show that state-of-the-art LLMs exhibit significant algorithmic variance even among functionally correct outputs. Notably, increasing sampling temperature improves pass@1 rates but degrades stability, revealing an unrecognized trade-off: searching for correct solutions in diverse output spaces introduces a "penalty of instability" between correctness and behavioral consistency. Our findings call for stability-aware objectives in code generation and new benchmarks with asymptotic test cases for robust, real-world LLM evaluation.
Measuring LLM Code Generation Stability via Structural Entropy
Aug 19, 2025Assessing the stability of code generation from large language models (LLMs) is essential for judging their reliability in real-world development. We extend prior "structural-entropy concepts" to the program domain by pairing entropy with abstract syntax tree (AST) analysis. For any fixed prompt, we collect the multiset of depth-bounded subtrees of AST in each generated program and treat their relative frequencies as a probability distribution. We then measure stability in two complementary ways: (i) Jensen-Shannon divergence, a symmetric, bounded indicator of structural overlap, and (ii) a Structural Cross-Entropy ratio that highlights missing high-probability patterns. Both metrics admit structural-only and token-aware variants, enabling separate views on control-flow shape and identifier-level variability. Unlike pass@k, BLEU, or CodeBLEU, our metrics are reference-free, language-agnostic, and execution-independent. We benchmark several leading LLMs on standard code generation tasks, demonstrating that AST-driven structural entropy reveals nuances in model consistency and robustness. The method runs in O(n,d) time with no external tests, providing a lightweight addition to the code-generation evaluation toolkit.
Is LLM the Silver Bullet to Low-Resource Languages Machine Translation?
Mar 31, 2025
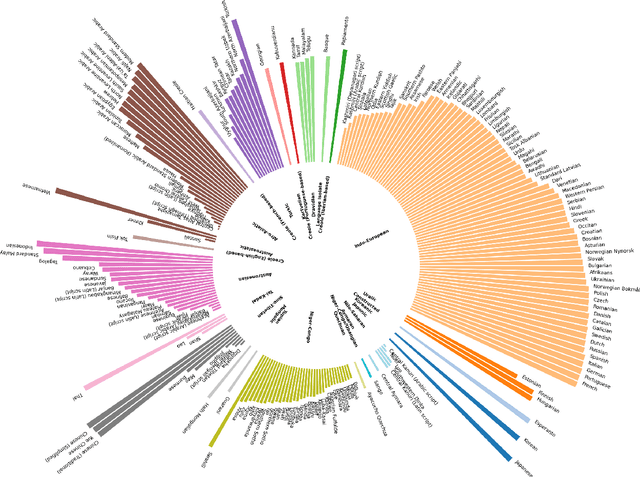
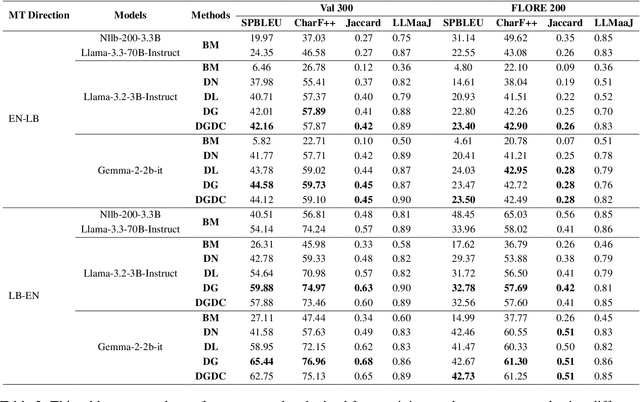
Low-Resource Languages (LRLs) present significant challenges in natural language processing due to their limited linguistic resources and underrepresentation in standard datasets. While recent advancements in Large Language Models (LLMs) and Neural Machine Translation (NMT) have substantially improved translation capabilities for high-resource languages, performance disparities persist for LRLs, particularly impacting privacy-sensitive and resource-constrained scenarios. This paper systematically evaluates the limitations of current LLMs across 200 languages using benchmarks such as FLORES-200. We also explore alternative data sources, including news articles and bilingual dictionaries, and demonstrate how knowledge distillation from large pre-trained models can significantly improve smaller LRL translations. Additionally, we investigate various fine-tuning strategies, revealing that incremental enhancements markedly reduce performance gaps on smaller LLMs.
CallNavi: A Study and Challenge on Function Calling Routing and Invocation in Large Language Models
Jan 09, 2025
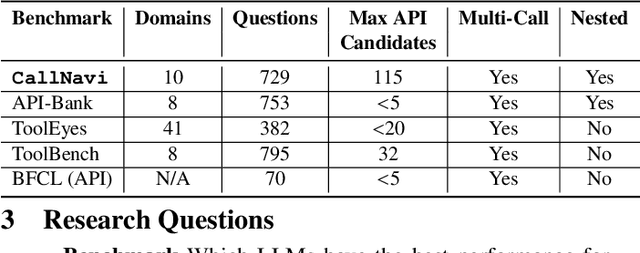


Interacting with a software system via a chatbot can be challenging, especially when the chatbot needs to generate API calls, in the right order and with the right parameters, to communicate with the system. API calling in chatbot systems poses significant challenges, particularly in complex, multi-step tasks requiring accurate API selection and execution. We contribute to this domain in three ways: first, by introducing a novel dataset designed to assess models on API function selection, parameter generation, and nested API calls; second, by benchmarking state-of-the-art language models across varying levels of complexity to evaluate their performance in API function generation and parameter accuracy; and third, by proposing an enhanced API routing method that combines general-purpose large language models for API selection with fine-tuned models for parameter generation and some prompt engineering approach. These approaches lead to substantial improvements in handling complex API tasks, offering practical advancements for real-world API-driven chatbot systems.
Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance
Apr 12, 2024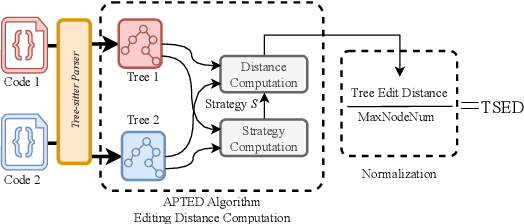
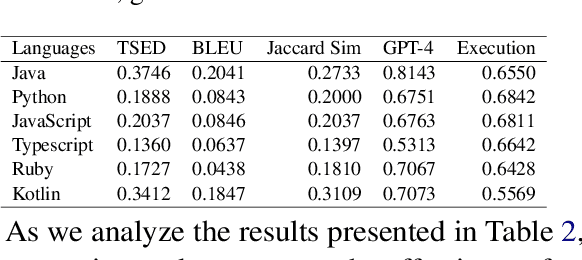
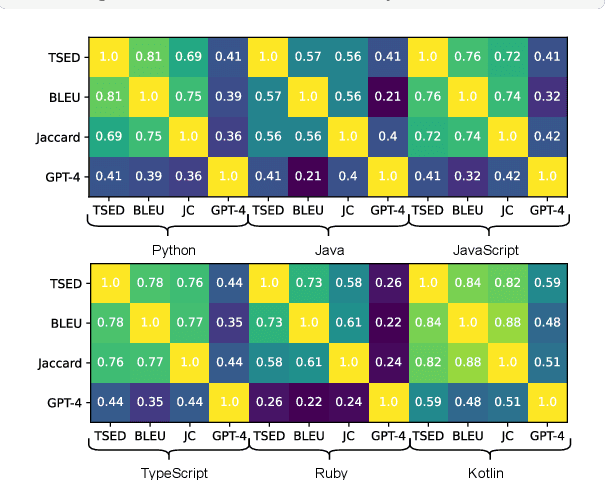
This paper revisits recent code similarity evaluation metrics, particularly focusing on the application of Abstract Syntax Tree (AST) editing distance in diverse programming languages. In particular, we explore the usefulness of these metrics and compare them to traditional sequence similarity metrics. Our experiments showcase the effectiveness of AST editing distance in capturing intricate code structures, revealing a high correlation with established metrics. Furthermore, we explore the strengths and weaknesses of AST editing distance and prompt-based GPT similarity scores in comparison to BLEU score, execution match, and Jaccard Similarity. We propose, optimize, and publish an adaptable metric that demonstrates effectiveness across all tested languages, representing an enhanced version of Tree Similarity of Edit Distance (TSED).
Letz Translate: Low-Resource Machine Translation for Luxembourgish
Mar 02, 2023



Natural language processing of Low-Resource Languages (LRL) is often challenged by the lack of data. Therefore, achieving accurate machine translation (MT) in a low-resource environment is a real problem that requires practical solutions. Research in multilingual models have shown that some LRLs can be handled with such models. However, their large size and computational needs make their use in constrained environments (e.g., mobile/IoT devices or limited/old servers) impractical. In this paper, we address this problem by leveraging the power of large multilingual MT models using knowledge distillation. Knowledge distillation can transfer knowledge from a large and complex teacher model to a simpler and smaller student model without losing much in performance. We also make use of high-resource languages that are related or share the same linguistic root as the target LRL. For our evaluation, we consider Luxembourgish as the LRL that shares some roots and properties with German. We build multiple resource-efficient models based on German, knowledge distillation from the multilingual No Language Left Behind (NLLB) model, and pseudo-translation. We find that our efficient models are more than 30\% faster and perform only 4\% lower compared to the large state-of-the-art NLLB model.