 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVCM Track Circuits Pre-emptive Failure Diagnostics for Predictive Maintenance Using Deep Neural Networks
Aug 12, 2025Track circuits are critical for railway operations, acting as the main signalling sub-system to locate trains. Continuous Variable Current Modulation (CVCM) is one such technology. Like any field-deployed, safety-critical asset, it can fail, triggering cascading disruptions. Many failures originate as subtle anomalies that evolve over time, often not visually apparent in monitored signals. Conventional approaches, which rely on clear signal changes, struggle to detect them early. Early identification of failure types is essential to improve maintenance planning, minimising downtime and revenue loss. Leveraging deep neural networks, we propose a predictive maintenance framework that classifies anomalies well before they escalate into failures. Validated on 10 CVCM failure cases across different installations, the method is ISO-17359 compliant and outperforms conventional techniques, achieving 99.31% overall accuracy with detection within 1% of anomaly onset. Through conformal prediction, we provide uncertainty estimates, reaching 99% confidence with consistent coverage across classes. Given CVCMs global deployment, the approach is scalable and adaptable to other track circuits and railway systems, enhancing operational reliability.
Letz Translate: Low-Resource Machine Translation for Luxembourgish
Mar 02, 2023



Natural language processing of Low-Resource Languages (LRL) is often challenged by the lack of data. Therefore, achieving accurate machine translation (MT) in a low-resource environment is a real problem that requires practical solutions. Research in multilingual models have shown that some LRLs can be handled with such models. However, their large size and computational needs make their use in constrained environments (e.g., mobile/IoT devices or limited/old servers) impractical. In this paper, we address this problem by leveraging the power of large multilingual MT models using knowledge distillation. Knowledge distillation can transfer knowledge from a large and complex teacher model to a simpler and smaller student model without losing much in performance. We also make use of high-resource languages that are related or share the same linguistic root as the target LRL. For our evaluation, we consider Luxembourgish as the LRL that shares some roots and properties with German. We build multiple resource-efficient models based on German, knowledge distillation from the multilingual No Language Left Behind (NLLB) model, and pseudo-translation. We find that our efficient models are more than 30\% faster and perform only 4\% lower compared to the large state-of-the-art NLLB model.
Rethinking the Event Coding Pipeline with Prompt Entailment
Oct 11, 2022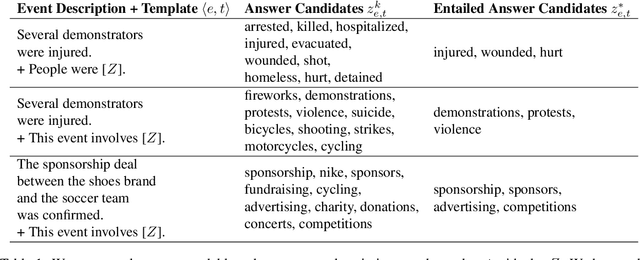
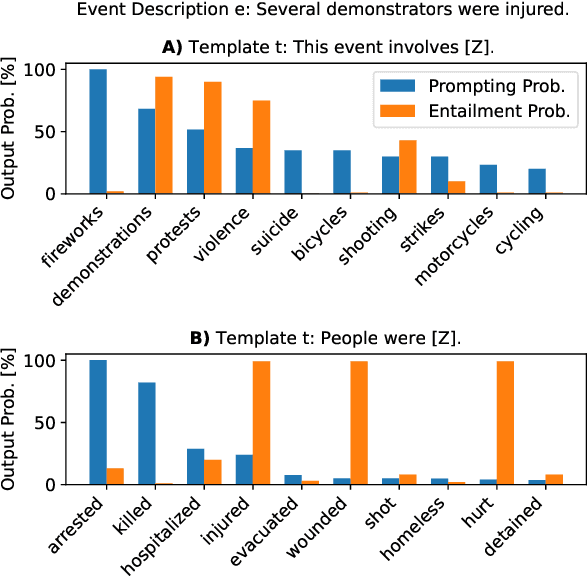
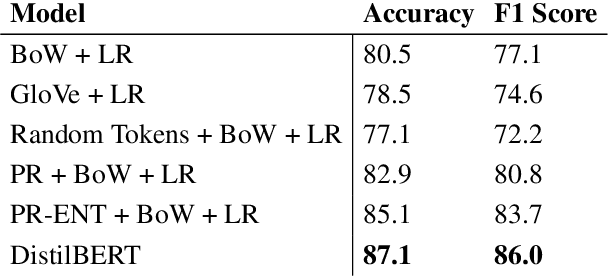

For monitoring crises, political events are extracted from the news. The large amount of unstructured full-text event descriptions makes a case-by-case analysis unmanageable, particularly for low-resource humanitarian aid organizations. This creates a demand to classify events into event types, a task referred to as event coding. Typically, domain experts craft an event type ontology, annotators label a large dataset and technical experts develop a supervised coding system. In this work, we propose PR-ENT, a new event coding approach that is more flexible and resource-efficient, while maintaining competitive accuracy: first, we extend an event description such as "Military injured two civilians'' by a template, e.g. "People were [Z]" and prompt a pre-trained (cloze) language model to fill the slot Z. Second, we select answer candidates Z* = {"injured'', "hurt"...} by treating the event description as premise and the filled templates as hypothesis in a textual entailment task. This allows domain experts to draft the codebook directly as labeled prompts and interpretable answer candidates. This human-in-the-loop process is guided by our interactive codebook design tool. We evaluate PR-ENT in several robustness checks: perturbing the event description and prompt template, restricting the vocabulary and removing contextual information.