 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCallNavi: A Study and Challenge on Function Calling Routing and Invocation in Large Language Models
Jan 09, 2025
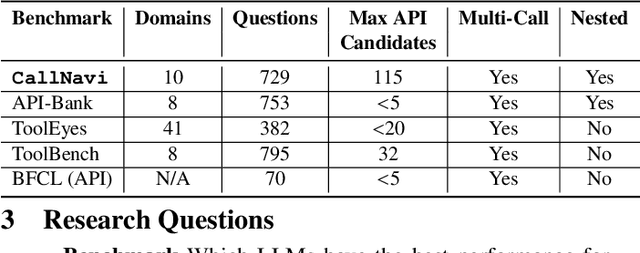


Interacting with a software system via a chatbot can be challenging, especially when the chatbot needs to generate API calls, in the right order and with the right parameters, to communicate with the system. API calling in chatbot systems poses significant challenges, particularly in complex, multi-step tasks requiring accurate API selection and execution. We contribute to this domain in three ways: first, by introducing a novel dataset designed to assess models on API function selection, parameter generation, and nested API calls; second, by benchmarking state-of-the-art language models across varying levels of complexity to evaluate their performance in API function generation and parameter accuracy; and third, by proposing an enhanced API routing method that combines general-purpose large language models for API selection with fine-tuned models for parameter generation and some prompt engineering approach. These approaches lead to substantial improvements in handling complex API tasks, offering practical advancements for real-world API-driven chatbot systems.
Letz Translate: Low-Resource Machine Translation for Luxembourgish
Mar 02, 2023



Natural language processing of Low-Resource Languages (LRL) is often challenged by the lack of data. Therefore, achieving accurate machine translation (MT) in a low-resource environment is a real problem that requires practical solutions. Research in multilingual models have shown that some LRLs can be handled with such models. However, their large size and computational needs make their use in constrained environments (e.g., mobile/IoT devices or limited/old servers) impractical. In this paper, we address this problem by leveraging the power of large multilingual MT models using knowledge distillation. Knowledge distillation can transfer knowledge from a large and complex teacher model to a simpler and smaller student model without losing much in performance. We also make use of high-resource languages that are related or share the same linguistic root as the target LRL. For our evaluation, we consider Luxembourgish as the LRL that shares some roots and properties with German. We build multiple resource-efficient models based on German, knowledge distillation from the multilingual No Language Left Behind (NLLB) model, and pseudo-translation. We find that our efficient models are more than 30\% faster and perform only 4\% lower compared to the large state-of-the-art NLLB model.