 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Low-Resource NLP Needs More Than Cross-Lingual Transfer: Lessons Learned from Luxembourgish
May 11, 2026Cross-lingual transfer has become a central paradigm for extending natural language processing (NLP) technologies to low-resource languages. By leveraging supervision from high-resource languages, multilingual language models can achieve strong task performance with little or no labeled target-language data. However, it remains unclear to what extent cross-lingual transfer can substitute for language-specific efforts. In this paper, we synthesize prior research findings and data collection results on Luxembourgish, which, despite its typological proximity to high-resource languages and its presence in a multilingual context, remains insufficiently represented in modern NLP technologies. Across findings, we observe a fundamental interdependence between cross-lingual transfer and language-specific efforts. Cross-lingual transfer can substantially improve target-language performance, but its success depends critically on the availability of sufficiently high-quality, task-aligned target-language data. At the same time, such resources, particularly in low-resource settings, are typically too limited in scale to drive strong performance on their own. Instead, such resources reach their full potential only when leveraged within a cross-lingual framework. We therefore argue that cross-lingual transfer and language-specific efforts should not be viewed as competing alternatives. Instead, they function as complementary components of a sustainable low-resource NLP pipeline. Based on these insights, we provide practical guidelines for integrating and balancing cross-lingual transfer with language-specific development in sustainable low-resource NLP pipelines.
Empirical Evaluation of PDF Parsing and Chunking for Financial Question Answering with RAG
Apr 13, 2026PDF files are primarily intended for human reading rather than automated processing. In addition, the heterogeneous content of PDFs, such as text, tables, and images, poses significant challenges for parsing and information extraction. To address these difficulties, both practitioners and researchers are increasingly developing new methods, including the promising Retrieval-Augmented Generation (RAG) systems to automated PDF processing. However, there is no comprehensive study investigating how different components and design choices affect the performance of a RAG system for understanding PDFs. In this paper, we propose such a study (1) by focusing on Question Answering, a specific language understanding task, and (2) by leveraging two benchmarks from the financial domain, including TableQuest, our newly generated, publicly available benchmark. We systematically examine multiple PDF parsers and chunking strategies (with varied overlap), along with their potential synergies in preserving document structure and ensuring answer correctness. Overall, our results offer practical guidelines for building robust RAG pipelines for PDF understanding.
Adversarial Camouflage
Mar 23, 2026While the rapid development of facial recognition algorithms has enabled numerous beneficial applications, their widespread deployment has raised significant concerns about the risks of mass surveillance and threats to individual privacy. In this paper, we introduce \textit{Adversarial Camouflage} as a novel solution for protecting users' privacy. This approach is designed to be efficient and simple to reproduce for users in the physical world. The algorithm starts by defining a low-dimensional pattern space parameterized by color, shape, and angle. Optimized patterns, once found, are projected onto semantically valid facial regions for evaluation. Our method maximizes recognition error across multiple architectures, ensuring high cross-model transferability even against black-box systems. It significantly degrades the performance of all tested state-of-the-art face recognition models during simulations and demonstrates promising results in real-world human experiments, while revealing differences in model robustness and evidence of attack transferability across architectures.
Correctness isnt Efficiency: Runtime Memory Divergence in LLM-Generated Code
Jan 03, 2026Large language models (LLMs) can generate programs that pass unit tests, but passing tests does not guarantee reliable runtime behavior. We find that different correct solutions to the same task can show very different memory and performance patterns, which can lead to hidden operational risks. We present a framework to measure execution-time memory stability across multiple correct generations. At the solution level, we introduce Dynamic Mean Pairwise Distance (DMPD), which uses Dynamic Time Warping to compare the shapes of memory-usage traces after converting them into Monotonic Peak Profiles (MPPs) to reduce transient noise. Aggregating DMPD across tasks yields a model-level Model Instability Score (MIS). Experiments on BigOBench and CodeContests show substantial runtime divergence among correct solutions. Instability often increases with higher sampling temperature even when pass@1 improves. We also observe correlations between our stability measures and software engineering indicators such as cognitive and cyclomatic complexity, suggesting links between operational behavior and maintainability. Our results support stability-aware selection among passing candidates in CI/CD to reduce operational risk without sacrificing correctness. Artifacts are available.
Dynamic Stability of LLM-Generated Code
Nov 07, 2025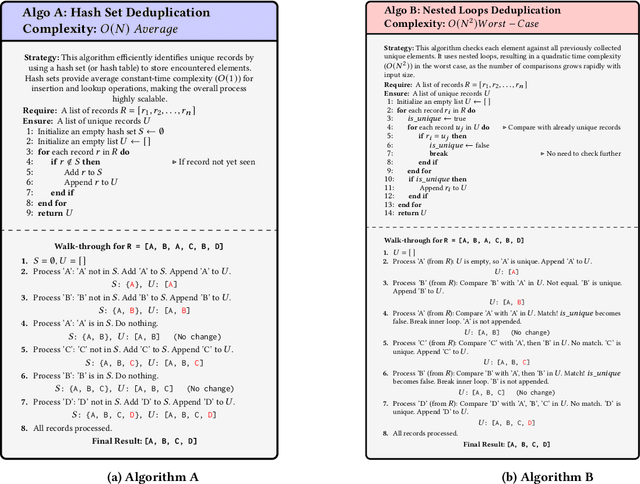
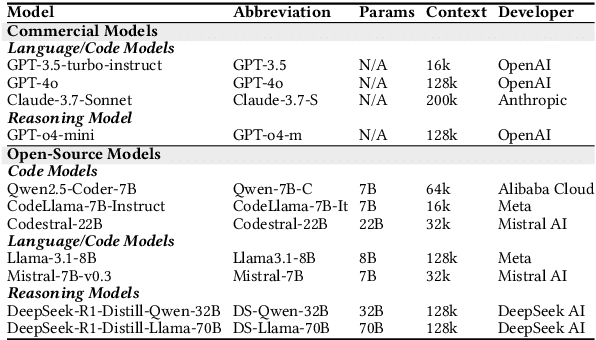
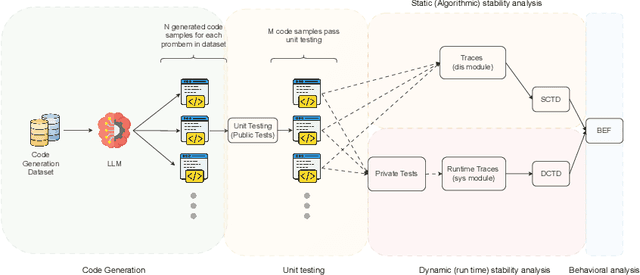
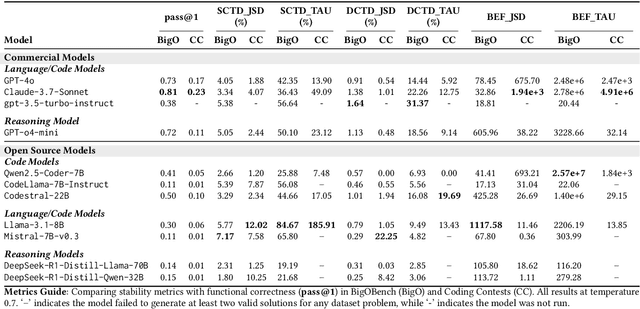
Current evaluations of LLMs for code generation emphasize functional correctness, overlooking the fact that functionally correct solutions can differ significantly in algorithmic complexity. For instance, an $(O(n^2))$ versus $(O(n \log n))$ sorting algorithm may yield similar output but incur vastly different performance costs in production. This discrepancy reveals a critical limitation in current evaluation methods: they fail to capture the behavioral and performance diversity among correct solutions. To address this, we introduce a principled framework for evaluating the dynamic stability of generated code. We propose two metrics derived from opcode distributions: Static Canonical Trace Divergence (SCTD), which captures algorithmic structure diversity across generated solutions, and Dynamic Canonical Trace Divergence (DCTD), which quantifies runtime behavioral variance. Their ratio, the Behavioral Expression Factor (BEF), serves as a diagnostic signal: it indicates critical runtime instability when BEF $\ll$ 1 and functional redundancy when BEF $\gg$ 1. Empirical results on BigOBench and CodeContests show that state-of-the-art LLMs exhibit significant algorithmic variance even among functionally correct outputs. Notably, increasing sampling temperature improves pass@1 rates but degrades stability, revealing an unrecognized trade-off: searching for correct solutions in diverse output spaces introduces a "penalty of instability" between correctness and behavioral consistency. Our findings call for stability-aware objectives in code generation and new benchmarks with asymptotic test cases for robust, real-world LLM evaluation.
LuxInstruct: A Cross-Lingual Instruction Tuning Dataset For Luxembourgish
Oct 08, 2025Instruction tuning has become a key technique for enhancing the performance of large language models, enabling them to better follow human prompts. However, low-resource languages such as Luxembourgish face severe limitations due to the lack of high-quality instruction datasets. Traditional reliance on machine translation often introduces semantic misalignment and cultural inaccuracies. In this work, we address these challenges by creating a cross-lingual instruction tuning dataset for Luxembourgish, without resorting to machine-generated translations into it. Instead, by leveraging aligned data from English, French, and German, we build a high-quality dataset that preserves linguistic and cultural nuances. We provide evidence that cross-lingual instruction tuning not only improves representational alignment across languages but also the model's generative capabilities in Luxembourgish. This highlights how cross-lingual data curation can avoid the common pitfalls of machine-translated data and directly benefit low-resource language development.
SIEVE: Towards Verifiable Certification for Code-datasets
Oct 02, 2025


Code agents and empirical software engineering rely on public code datasets, yet these datasets lack verifiable quality guarantees. Static 'dataset cards' inform, but they are neither auditable nor do they offer statistical guarantees, making it difficult to attest to dataset quality. Teams build isolated, ad-hoc cleaning pipelines. This fragments effort and raises cost. We present SIEVE, a community-driven framework. It turns per-property checks into Confidence Cards-machine-readable, verifiable certificates with anytime-valid statistical bounds. We outline a research plan to bring SIEVE to maturity, replacing narrative cards with anytime-verifiable certification. This shift is expected to lower quality-assurance costs and increase trust in code-datasets.
Measuring LLM Code Generation Stability via Structural Entropy
Aug 19, 2025Assessing the stability of code generation from large language models (LLMs) is essential for judging their reliability in real-world development. We extend prior "structural-entropy concepts" to the program domain by pairing entropy with abstract syntax tree (AST) analysis. For any fixed prompt, we collect the multiset of depth-bounded subtrees of AST in each generated program and treat their relative frequencies as a probability distribution. We then measure stability in two complementary ways: (i) Jensen-Shannon divergence, a symmetric, bounded indicator of structural overlap, and (ii) a Structural Cross-Entropy ratio that highlights missing high-probability patterns. Both metrics admit structural-only and token-aware variants, enabling separate views on control-flow shape and identifier-level variability. Unlike pass@k, BLEU, or CodeBLEU, our metrics are reference-free, language-agnostic, and execution-independent. We benchmark several leading LLMs on standard code generation tasks, demonstrating that AST-driven structural entropy reveals nuances in model consistency and robustness. The method runs in O(n,d) time with no external tests, providing a lightweight addition to the code-generation evaluation toolkit.
Memorization or Interpolation ? Detecting LLM Memorization through Input Perturbation Analysis
May 05, 2025While Large Language Models (LLMs) achieve remarkable performance through training on massive datasets, they can exhibit concerning behaviors such as verbatim reproduction of training data rather than true generalization. This memorization phenomenon raises significant concerns about data privacy, intellectual property rights, and the reliability of model evaluations. This paper introduces PEARL, a novel approach for detecting memorization in LLMs. PEARL assesses how sensitive an LLM's performance is to input perturbations, enabling memorization detection without requiring access to the model's internals. We investigate how input perturbations affect the consistency of outputs, enabling us to distinguish between true generalization and memorization. Our findings, following extensive experiments on the Pythia open model, provide a robust framework for identifying when the model simply regurgitates learned information. Applied on the GPT 4o models, the PEARL framework not only identified cases of memorization of classic texts from the Bible or common code from HumanEval but also demonstrated that it can provide supporting evidence that some data, such as from the New York Times news articles, were likely part of the training data of a given model.
The Code Barrier: What LLMs Actually Understand?
Apr 14, 2025Understanding code represents a core ability needed for automating software development tasks. While foundation models like LLMs show impressive results across many software engineering challenges, the extent of their true semantic understanding beyond simple token recognition remains unclear. This research uses code obfuscation as a structured testing framework to evaluate LLMs' semantic understanding capabilities. We methodically apply controlled obfuscation changes to source code and measure comprehension through two complementary tasks: generating accurate descriptions of obfuscated code and performing deobfuscation, a skill with important implications for reverse engineering applications. Our testing approach includes 13 cutting-edge models, covering both code-specialized (e.g., StarCoder2) and general-purpose (e.g., GPT-4o) architectures, evaluated on a benchmark created from CodeNet and consisting of filtered 250 Java programming problems and their solutions. Findings show a statistically significant performance decline as obfuscation complexity increases, with unexpected resilience shown by general-purpose models compared to their code-focused counterparts. While some models successfully identify obfuscation techniques, their ability to reconstruct the underlying program logic remains constrained, suggesting limitations in their semantic representation mechanisms. This research introduces a new evaluation approach for assessing code comprehension in language models and establishes empirical baselines for advancing research in security-critical code analysis applications such as reverse engineering and adversarial code analysis.