 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIEVE: Towards Verifiable Certification for Code-datasets
Oct 02, 2025


Code agents and empirical software engineering rely on public code datasets, yet these datasets lack verifiable quality guarantees. Static 'dataset cards' inform, but they are neither auditable nor do they offer statistical guarantees, making it difficult to attest to dataset quality. Teams build isolated, ad-hoc cleaning pipelines. This fragments effort and raises cost. We present SIEVE, a community-driven framework. It turns per-property checks into Confidence Cards-machine-readable, verifiable certificates with anytime-valid statistical bounds. We outline a research plan to bring SIEVE to maturity, replacing narrative cards with anytime-verifiable certification. This shift is expected to lower quality-assurance costs and increase trust in code-datasets.
The Code Barrier: What LLMs Actually Understand?
Apr 14, 2025Understanding code represents a core ability needed for automating software development tasks. While foundation models like LLMs show impressive results across many software engineering challenges, the extent of their true semantic understanding beyond simple token recognition remains unclear. This research uses code obfuscation as a structured testing framework to evaluate LLMs' semantic understanding capabilities. We methodically apply controlled obfuscation changes to source code and measure comprehension through two complementary tasks: generating accurate descriptions of obfuscated code and performing deobfuscation, a skill with important implications for reverse engineering applications. Our testing approach includes 13 cutting-edge models, covering both code-specialized (e.g., StarCoder2) and general-purpose (e.g., GPT-4o) architectures, evaluated on a benchmark created from CodeNet and consisting of filtered 250 Java programming problems and their solutions. Findings show a statistically significant performance decline as obfuscation complexity increases, with unexpected resilience shown by general-purpose models compared to their code-focused counterparts. While some models successfully identify obfuscation techniques, their ability to reconstruct the underlying program logic remains constrained, suggesting limitations in their semantic representation mechanisms. This research introduces a new evaluation approach for assessing code comprehension in language models and establishes empirical baselines for advancing research in security-critical code analysis applications such as reverse engineering and adversarial code analysis.
ChatGPT vs LLaMA: Impact, Reliability, and Challenges in Stack Overflow Discussions
Feb 13, 2024Since its release in November 2022, ChatGPT has shaken up Stack Overflow, the premier platform for developers' queries on programming and software development. Demonstrating an ability to generate instant, human-like responses to technical questions, ChatGPT has ignited debates within the developer community about the evolving role of human-driven platforms in the age of generative AI. Two months after ChatGPT's release, Meta released its answer with its own Large Language Model (LLM) called LLaMA: the race was on. We conducted an empirical study analyzing questions from Stack Overflow and using these LLMs to address them. This way, we aim to (ii) measure user engagement evolution with Stack Overflow over time; (ii) quantify the reliability of LLMs' answers and their potential to replace Stack Overflow in the long term; (iii) identify and understand why LLMs fails; and (iv) compare LLMs together. Our empirical results are unequivocal: ChatGPT and LLaMA challenge human expertise, yet do not outperform it for some domains, while a significant decline in user posting activity has been observed. Furthermore, we also discuss the impact of our findings regarding the usage and development of new LLMs.
DexRay: A Simple, yet Effective Deep Learning Approach to Android Malware Detection based on Image Representation of Bytecode
Sep 05, 2021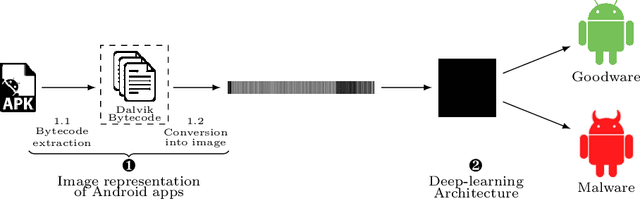


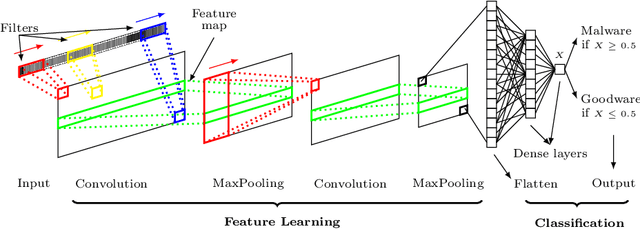
Computer vision has witnessed several advances in recent years, with unprecedented performance provided by deep representation learning research. Image formats thus appear attractive to other fields such as malware detection, where deep learning on images alleviates the need for comprehensively hand-crafted features generalising to different malware variants. We postulate that this research direction could become the next frontier in Android malware detection, and therefore requires a clear roadmap to ensure that new approaches indeed bring novel contributions. We contribute with a first building block by developing and assessing a baseline pipeline for image-based malware detection with straightforward steps. We propose DexRay, which converts the bytecode of the app DEX files into grey-scale "vector" images and feeds them to a 1-dimensional Convolutional Neural Network model. We view DexRay as foundational due to the exceedingly basic nature of the design choices, allowing to infer what could be a minimal performance that can be obtained with image-based learning in malware detection. The performance of DexRay evaluated on over 158k apps demonstrates that, while simple, our approach is effective with a high detection rate(F1-score= 0.96). Finally, we investigate the impact of time decay and image-resizing on the performance of DexRay and assess its resilience to obfuscation. This work-in-progress paper contributes to the domain of Deep Learning based Malware detection by providing a sound, simple, yet effective approach (with available artefacts) that can be the basis to scope the many profound questions that will need to be investigated to fully develop this domain.