 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of LLMs to generate a dataset of Neural Networks
Feb 04, 2026Neural networks are increasingly used to support decision-making. To verify their reliability and adaptability, researchers and practitioners have proposed a variety of tools and methods for tasks such as NN code verification, refactoring, and migration. These tools play a crucial role in guaranteeing both the correctness and maintainability of neural network architectures, helping to prevent implementation errors, simplify model updates, and ensure that complex networks can be reliably extended and reused. Yet, assessing their effectiveness remains challenging due to the lack of publicly diverse datasets of neural networks that would allow systematic evaluation. To address this gap, we leverage large language models (LLMs) to automatically generate a dataset of neural networks that can serve as a benchmark for validation. The dataset is designed to cover diverse architectural components and to handle multiple input data types and tasks. In total, 608 samples are generated, each conforming to a set of precise design choices. To further ensure their consistency, we validate the correctness of the generated networks using static analysis and symbolic tracing. We make the dataset publicly available to support the community in advancing research on neural network reliability and adaptability.
DetectBERT: Towards Full App-Level Representation Learning to Detect Android Malware
Aug 29, 2024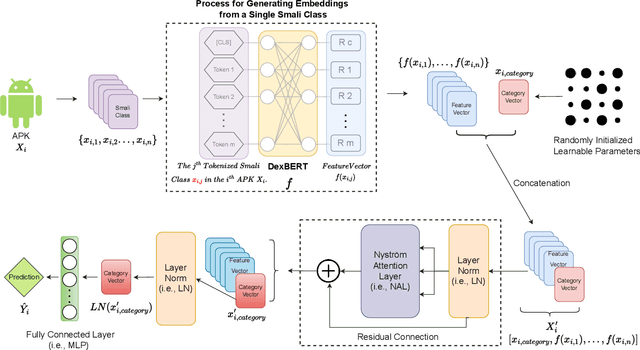
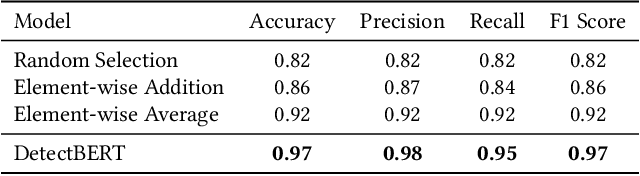
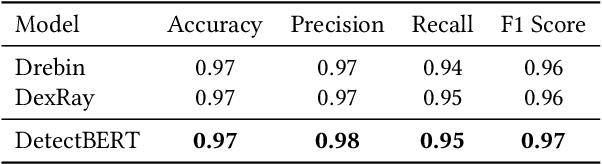
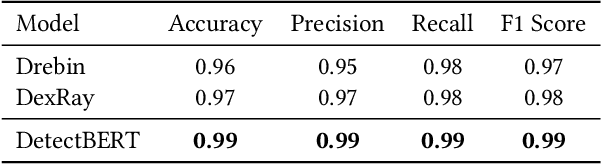
Recent advancements in ML and DL have significantly improved Android malware detection, yet many methodologies still rely on basic static analysis, bytecode, or function call graphs that often fail to capture complex malicious behaviors. DexBERT, a pre-trained BERT-like model tailored for Android representation learning, enriches class-level representations by analyzing Smali code extracted from APKs. However, its functionality is constrained by its inability to process multiple Smali classes simultaneously. This paper introduces DetectBERT, which integrates correlated Multiple Instance Learning (c-MIL) with DexBERT to handle the high dimensionality and variability of Android malware, enabling effective app-level detection. By treating class-level features as instances within MIL bags, DetectBERT aggregates these into a comprehensive app-level representation. Our evaluation demonstrates that DetectBERT not only surpasses existing state-of-the-art detection methods but also adapts to evolving malware threats. Moreover, the versatility of the DetectBERT framework holds promising potential for broader applications in app-level analysis and other software engineering tasks, offering new avenues for research and development.
LaFiCMIL: Rethinking Large File Classification from the Perspective of Correlated Multiple Instance Learning
Aug 15, 2023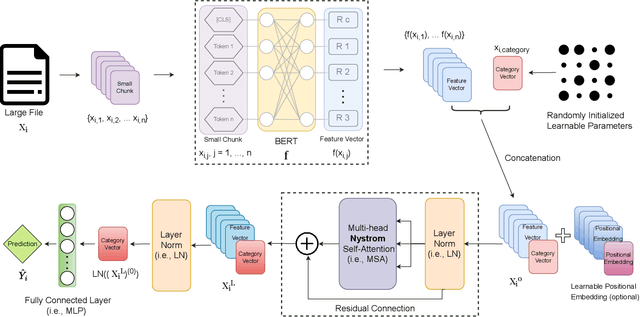
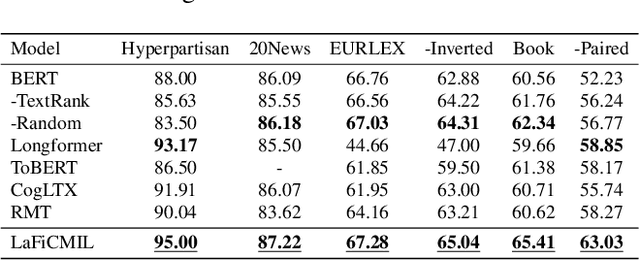
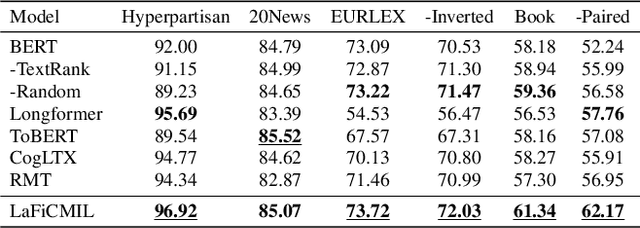
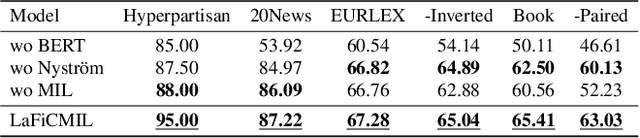
Transformer-based models, such as BERT, have revolutionized various language tasks, but still struggle with large file classification due to their input limit (e.g., 512 tokens). Despite several attempts to alleviate this limitation, no method consistently excels across all benchmark datasets, primarily because they can only extract partial essential information from the input file. Additionally, they fail to adapt to the varied properties of different types of large files. In this work, we tackle this problem from the perspective of correlated multiple instance learning. The proposed approach, LaFiCMIL, serves as a versatile framework applicable to various large file classification tasks covering binary, multi-class, and multi-label classification tasks, spanning various domains including Natural Language Processing, Programming Language Processing, and Android Analysis. To evaluate its effectiveness, we employ eight benchmark datasets pertaining to Long Document Classification, Code Defect Detection, and Android Malware Detection. Leveraging BERT-family models as feature extractors, our experimental results demonstrate that LaFiCMIL achieves new state-of-the-art performance across all benchmark datasets. This is largely attributable to its capability of scaling BERT up to nearly 20K tokens, running on a single Tesla V-100 GPU with 32G of memory.
A two-steps approach to improve the performance of Android malware detectors
May 17, 2022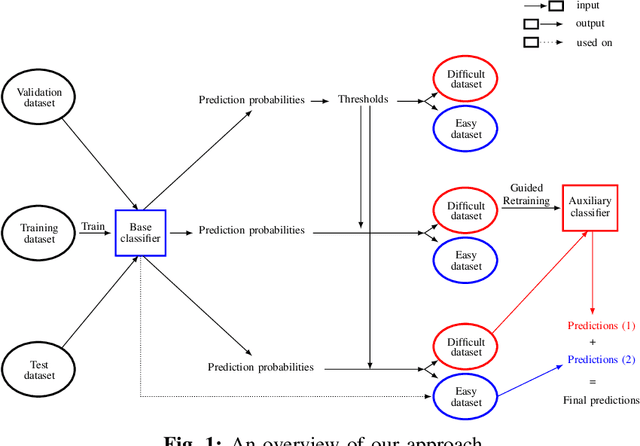



The popularity of Android OS has made it an appealing target to malware developers. To evade detection, including by ML-based techniques, attackers invest in creating malware that closely resemble legitimate apps. In this paper, we propose GUIDED RETRAINING, a supervised representation learning-based method that boosts the performance of a malware detector. First, the dataset is split into "easy" and "difficult" samples, where difficulty is associated to the prediction probabilities yielded by a malware detector: for difficult samples, the probabilities are such that the classifier is not confident on the predictions, which have high error rates. Then, we apply our GUIDED RETRAINING method on the difficult samples to improve their classification. For the subset of "easy" samples, the base malware detector is used to make the final predictions since the error rate on that subset is low by construction. For the subset of "difficult" samples, we rely on GUIDED RETRAINING, which leverages the correct predictions and the errors made by the base malware detector to guide the retraining process. GUIDED RETRAINING focuses on the difficult samples: it learns new embeddings of these samples using Supervised Contrastive Learning and trains an auxiliary classifier for the final predictions. We validate our method on four state-of-the-art Android malware detection approaches using over 265k malware and benign apps, and we demonstrate that GUIDED RETRAINING can reduce up to 40.41% prediction errors made by the malware detectors. Our method is generic and designed to enhance the classification performance on a binary classification task. Consequently, it can be applied to other classification problems beyond Android malware detection.
DexRay: A Simple, yet Effective Deep Learning Approach to Android Malware Detection based on Image Representation of Bytecode
Sep 05, 2021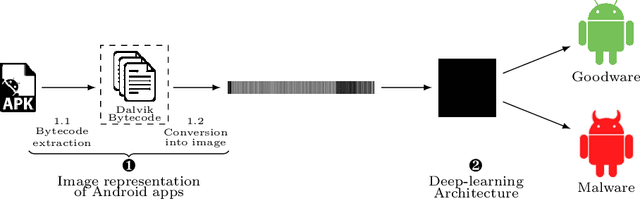


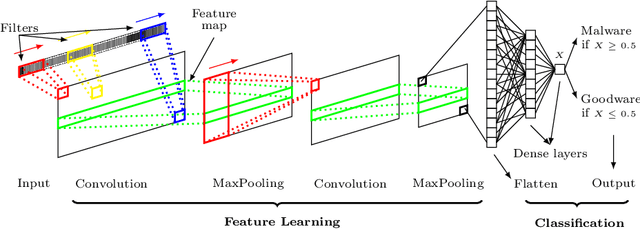
Computer vision has witnessed several advances in recent years, with unprecedented performance provided by deep representation learning research. Image formats thus appear attractive to other fields such as malware detection, where deep learning on images alleviates the need for comprehensively hand-crafted features generalising to different malware variants. We postulate that this research direction could become the next frontier in Android malware detection, and therefore requires a clear roadmap to ensure that new approaches indeed bring novel contributions. We contribute with a first building block by developing and assessing a baseline pipeline for image-based malware detection with straightforward steps. We propose DexRay, which converts the bytecode of the app DEX files into grey-scale "vector" images and feeds them to a 1-dimensional Convolutional Neural Network model. We view DexRay as foundational due to the exceedingly basic nature of the design choices, allowing to infer what could be a minimal performance that can be obtained with image-based learning in malware detection. The performance of DexRay evaluated on over 158k apps demonstrates that, while simple, our approach is effective with a high detection rate(F1-score= 0.96). Finally, we investigate the impact of time decay and image-resizing on the performance of DexRay and assess its resilience to obfuscation. This work-in-progress paper contributes to the domain of Deep Learning based Malware detection by providing a sound, simple, yet effective approach (with available artefacts) that can be the basis to scope the many profound questions that will need to be investigated to fully develop this domain.