 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LLM-as-Judge Metric for Bridging the Gap with Human Evaluation in SE Tasks
May 27, 2025



Large Language Models (LLMs) and other automated techniques have been increasingly used to support software developers by generating software artifacts such as code snippets, patches, and comments. However, accurately assessing the correctness of these generated artifacts remains a significant challenge. On one hand, human evaluation provides high accuracy but is labor-intensive and lacks scalability. On the other hand, other existing automatic evaluation metrics are scalable and require minimal human effort, but they often fail to accurately reflect the actual correctness of generated software artifacts. In this paper, we present SWE-Judge, the first evaluation metric for LLM-as-Ensemble-Judge specifically designed to accurately assess the correctness of generated software artifacts. SWE-Judge first defines five distinct evaluation strategies, each implemented as an independent judge. A dynamic team selection mechanism then identifies the most appropriate subset of judges to produce a final correctness score through ensembling. We evaluate SWE-Judge across a diverse set of software engineering (SE) benchmarks, including CoNaLa, Card2Code, HumanEval-X, APPS, APR-Assess, and Summary-Assess. These benchmarks span three SE tasks: code generation, automated program repair, and code summarization. Experimental results demonstrate that SWE-Judge consistently achieves a higher correlation with human judgments, with improvements ranging from 5.9% to 183.8% over existing automatic metrics. Furthermore, SWE-Judge reaches agreement levels with human annotators that are comparable to inter-annotator agreement in code generation and program repair tasks. These findings underscore SWE-Judge's potential as a scalable and reliable alternative to human evaluation.
DetectBERT: Towards Full App-Level Representation Learning to Detect Android Malware
Aug 29, 2024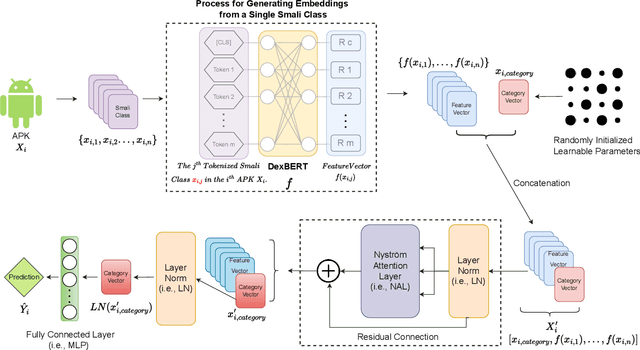
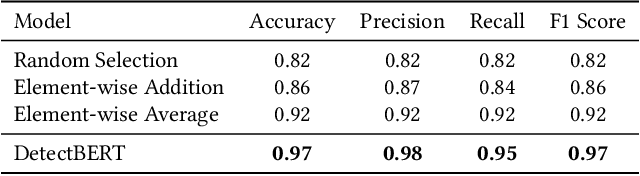
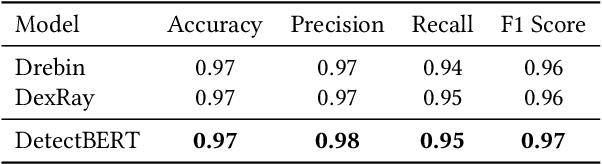
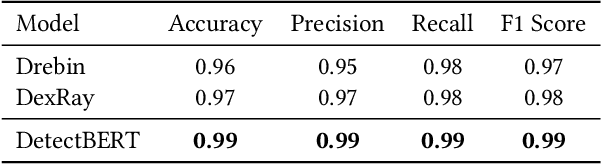
Recent advancements in ML and DL have significantly improved Android malware detection, yet many methodologies still rely on basic static analysis, bytecode, or function call graphs that often fail to capture complex malicious behaviors. DexBERT, a pre-trained BERT-like model tailored for Android representation learning, enriches class-level representations by analyzing Smali code extracted from APKs. However, its functionality is constrained by its inability to process multiple Smali classes simultaneously. This paper introduces DetectBERT, which integrates correlated Multiple Instance Learning (c-MIL) with DexBERT to handle the high dimensionality and variability of Android malware, enabling effective app-level detection. By treating class-level features as instances within MIL bags, DetectBERT aggregates these into a comprehensive app-level representation. Our evaluation demonstrates that DetectBERT not only surpasses existing state-of-the-art detection methods but also adapts to evolving malware threats. Moreover, the versatility of the DetectBERT framework holds promising potential for broader applications in app-level analysis and other software engineering tasks, offering new avenues for research and development.
Just-in-Time Security Patch Detection -- LLM At the Rescue for Data Augmentation
Dec 02, 2023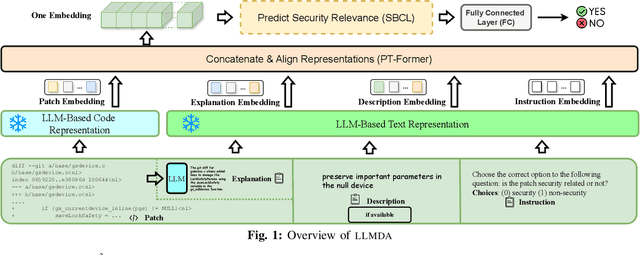
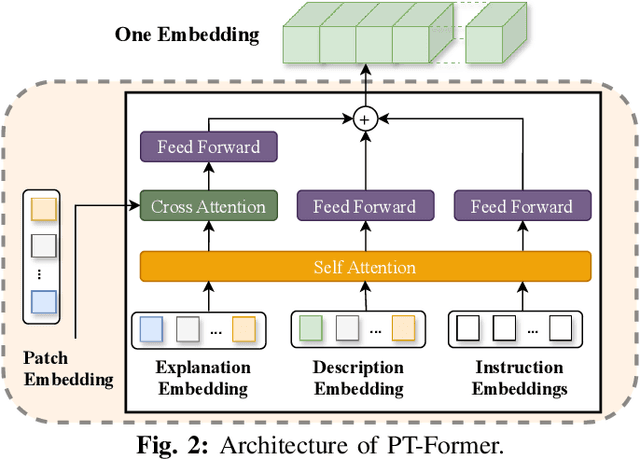
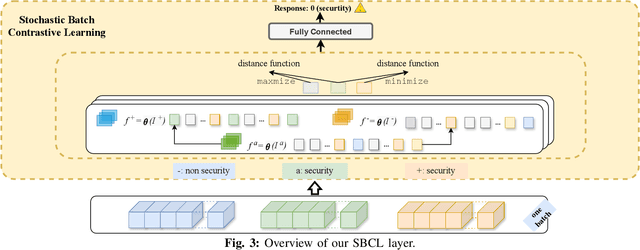
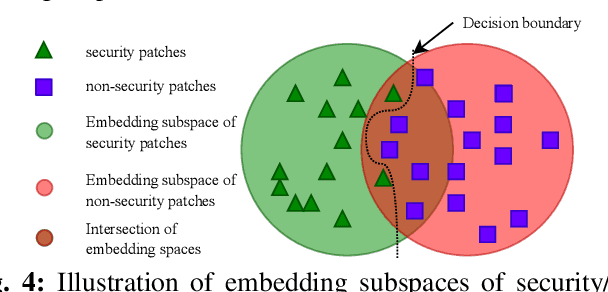
In the face of growing vulnerabilities found in open-source software, the need to identify {discreet} security patches has become paramount. The lack of consistency in how software providers handle maintenance often leads to the release of security patches without comprehensive advisories, leaving users vulnerable to unaddressed security risks. To address this pressing issue, we introduce a novel security patch detection system, LLMDA, which capitalizes on Large Language Models (LLMs) and code-text alignment methodologies for patch review, data enhancement, and feature combination. Within LLMDA, we initially utilize LLMs for examining patches and expanding data of PatchDB and SPI-DB, two security patch datasets from recent literature. We then use labeled instructions to direct our LLMDA, differentiating patches based on security relevance. Following this, we apply a PTFormer to merge patches with code, formulating hybrid attributes that encompass both the innate details and the interconnections between the patches and the code. This distinctive combination method allows our system to capture more insights from the combined context of patches and code, hence improving detection precision. Finally, we devise a probabilistic batch contrastive learning mechanism within batches to augment the capability of the our LLMDA in discerning security patches. The results reveal that LLMDA significantly surpasses the start of the art techniques in detecting security patches, underscoring its promise in fortifying software maintenance.
Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with Large Language Models
Aug 21, 2023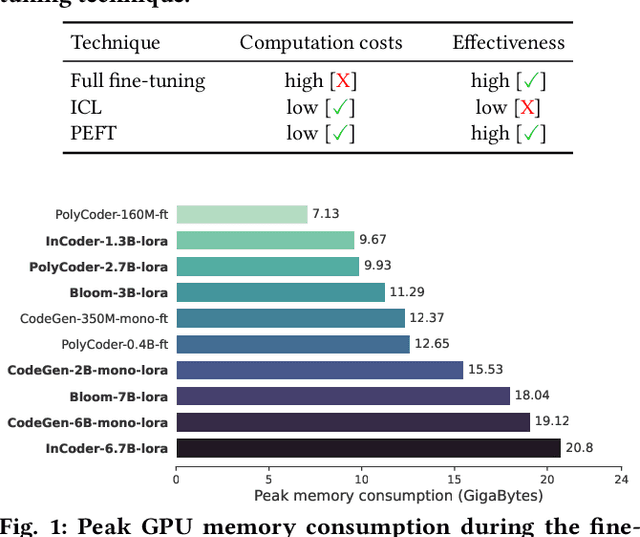


Large Language Models (LLMs) possess impressive capabilities to generate meaningful code snippets given natural language intents in zero-shot, i.e., without the need for specific fine-tuning. In the perspective of unleashing their full potential, prior work has demonstrated the benefits of fine-tuning the models to task-specific data. However, fine-tuning process demands heavy computational costs and is intractable when resources are scarce, especially for models with billions of parameters. In light of these challenges, previous studies explored In-Context Learning (ICL) as an effective strategy to generate contextually appropriate code without fine-tuning. However, it operates at inference time and does not involve learning task-specific parameters, potentially limiting the model's performance on downstream tasks. In this context, we foresee that Parameter-Efficient Fine-Tuning (PEFT) techniques carry a high potential for efficiently specializing LLMs to task-specific data. In this paper, we deliver a comprehensive study of LLMs with the impact of PEFT techniques under the automated code generation scenario. Our experimental results reveal the superiority and potential of such techniques over ICL on a wide range of LLMs in reducing the computational burden and improving performance. Therefore, the study opens opportunities for broader applications of PEFT in software engineering scenarios.
On the Usage of Continual Learning for Out-of-Distribution Generalization in Pre-trained Language Models of Code
May 06, 2023



Pre-trained language models (PLMs) have become a prevalent technique in deep learning for code, utilizing a two-stage pre-training and fine-tuning procedure to acquire general knowledge about code and specialize in a variety of downstream tasks. However, the dynamic nature of software codebases poses a challenge to the effectiveness and robustness of PLMs. In particular, world-realistic scenarios potentially lead to significant differences between the distribution of the pre-training and test data, i.e., distribution shift, resulting in a degradation of the PLM's performance on downstream tasks. In this paper, we stress the need for adapting PLMs of code to software data whose distribution changes over time, a crucial problem that has been overlooked in previous works. The motivation of this work is to consider the PLM in a non-stationary environment, where fine-tuning data evolves over time according to a software evolution scenario. Specifically, we design a scenario where the model needs to learn from a stream of programs containing new, unseen APIs over time. We study two widely used PLM architectures, i.e., a GPT2 decoder and a RoBERTa encoder, on two downstream tasks, API call and API usage prediction. We demonstrate that the most commonly used fine-tuning technique from prior work is not robust enough to handle the dynamic nature of APIs, leading to the loss of previously acquired knowledge i.e., catastrophic forgetting. To address these issues, we implement five continual learning approaches, including replay-based and regularization-based methods. Our findings demonstrate that utilizing these straightforward methods effectively mitigates catastrophic forgetting in PLMs across both downstream tasks while achieving comparable or superior performance.
A Pre-Trained BERT Model for Android Applications
Dec 12, 2022



The automation of an increasingly large number of software engineering tasks is becoming possible thanks to Machine Learning (ML). One foundational building block in the application of ML to software artifacts is the representation of these artifacts (e.g., source code or executable code) into a form that is suitable for learning. Many studies have leveraged representation learning, delegating to ML itself the job of automatically devising suitable representations. Yet, in the context of Android problems, existing models are either limited to coarse-grained whole-app level (e.g., apk2vec) or conducted for one specific downstream task (e.g., smali2vec). Our work is part of a new line of research that investigates effective, task-agnostic, and fine-grained universal representations of bytecode to mitigate both of these two limitations. Such representations aim to capture information relevant to various low-level downstream tasks (e.g., at the class-level). We are inspired by the field of Natural Language Processing, where the problem of universal representation was addressed by building Universal Language Models, such as BERT, whose goal is to capture abstract semantic information about sentences, in a way that is reusable for a variety of tasks. We propose DexBERT, a BERT-like Language Model dedicated to representing chunks of DEX bytecode, the main binary format used in Android applications. We empirically assess whether DexBERT is able to model the DEX language and evaluate the suitability of our model in two distinct class-level software engineering tasks: Malicious Code Localization and Defect Prediction. We also experiment with strategies to deal with the problem of catering to apps having vastly different sizes, and we demonstrate one example of using our technique to investigate what information is relevant to a given task.