 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Reward Models for Guiding Code Review Comment Generation
Jun 04, 2025Code review is a crucial component of modern software development, involving the evaluation of code quality, providing feedback on potential issues, and refining the code to address identified problems. Despite these benefits, code review can be rather time consuming, and influenced by subjectivity and human factors. For these reasons, techniques to (partially) automate the code review process have been proposed in the literature. Among those, the ones exploiting deep learning (DL) are able to tackle the generative aspect of code review, by commenting on a given code as a human reviewer would do (i.e., comment generation task) or by automatically implementing code changes required to address a reviewer's comment (i.e., code refinement task). In this paper, we introduce CoRAL, a deep learning framework automating review comment generation by exploiting reinforcement learning with a reward mechanism considering both the semantics of the generated comments as well as their usefulness as input for other models automating the code refinement task. The core idea is that if the DL model generates comments that are semantically similar to the expected ones or can be successfully implemented by a second model specialized in code refinement, these comments are likely to be meaningful and useful, thus deserving a high reward in the reinforcement learning framework. We present both quantitative and qualitative comparisons between the comments generated by CoRAL and those produced by the latest baseline techniques, highlighting the effectiveness and superiority of our approach.
MONO2REST: Identifying and Exposing Microservices: a Reusable RESTification Approach
Mar 27, 2025



The microservices architectural style has become the de facto standard for large-scale cloud applications, offering numerous benefits in scalability, maintainability, and deployment flexibility. Many organizations are pursuing the migration of legacy monolithic systems to a microservices architecture. However, this process is challenging, risky, time-intensive, and prone-to-failure while several organizations lack necessary financial resources, time, or expertise to set up this migration process. So, rather than trying to migrate a legacy system where migration is risky or not feasible, we suggest exposing it as a microservice application without without having to migrate it. In this paper, we present a reusable, automated, two-phase approach that combines evolutionary algorithms with machine learning techniques. In the first phase, we identify microservices at the method level using a multi-objective genetic algorithm that considers both structural and semantic dependencies between methods. In the second phase, we generate REST APIs for each identified microservice using a classification algorithm to assign HTTP methods and endpoints. We evaluated our approach with a case study on the Spring PetClinic application, which has both monolithic and microservices implementations that serve as ground truth for comparison. Results demonstrate that our approach successfully aligns identified microservices with those in the reference microservices implementation, highlighting its effectiveness in service identification and API generation.
Combining Large Language Models with Static Analyzers for Code Review Generation
Feb 10, 2025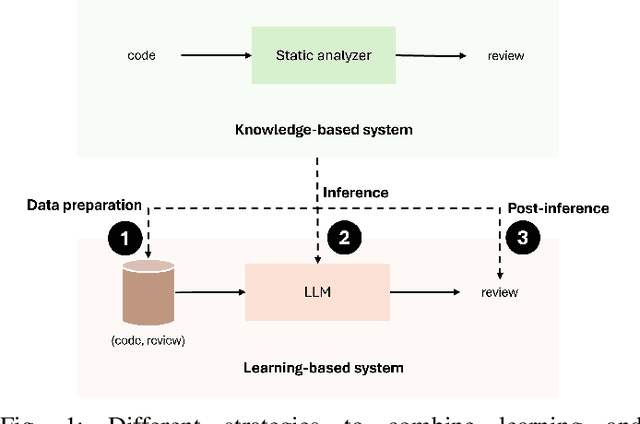
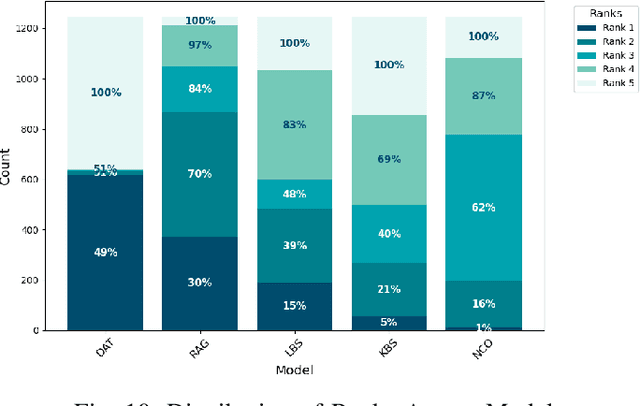

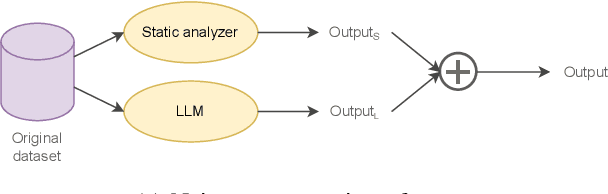
Code review is a crucial but often complex, subjective, and time-consuming activity in software development. Over the past decades, significant efforts have been made to automate this process. Early approaches focused on knowledge-based systems (KBS) that apply rule-based mechanisms to detect code issues, providing precise feedback but struggling with complex, context-dependent cases. More recent work has shifted toward fine-tuning pre-trained language models for code review, enabling broader issue coverage but often at the expense of precision. In this paper, we propose a hybrid approach that combines the strengths of KBS and learning-based systems (LBS) to generate high-quality, comprehensive code reviews. Our method integrates knowledge at three distinct stages of the language model pipeline: during data preparation (Data-Augmented Training, DAT), at inference (Retrieval-Augmented Generation, RAG), and after inference (Naive Concatenation of Outputs, NCO). We empirically evaluate our combination strategies against standalone KBS and LBS fine-tuned on a real-world dataset. Our results show that these hybrid strategies enhance the relevance, completeness, and overall quality of review comments, effectively bridging the gap between rule-based tools and deep learning models.
On the Utility of Domain Modeling Assistance with Large Language Models
Oct 16, 2024



Model-driven engineering (MDE) simplifies software development through abstraction, yet challenges such as time constraints, incomplete domain understanding, and adherence to syntactic constraints hinder the design process. This paper presents a study to evaluate the usefulness of a novel approach utilizing large language models (LLMs) and few-shot prompt learning to assist in domain modeling. The aim of this approach is to overcome the need for extensive training of AI-based completion models on scarce domain-specific datasets and to offer versatile support for various modeling activities, providing valuable recommendations to software modelers. To support this approach, we developed MAGDA, a user-friendly tool, through which we conduct a user study and assess the real-world applicability of our approach in the context of domain modeling, offering valuable insights into its usability and effectiveness.
CodeUltraFeedback: An LLM-as-a-Judge Dataset for Aligning Large Language Models to Coding Preferences
Mar 14, 2024Evaluating the alignment of large language models (LLMs) with user-defined coding preferences is a challenging endeavour that requires assessing intricate textual LLMs' outputs. By relying on automated metrics and static analysis tools, existing benchmarks fail to assess nuances in user instructions and LLM outputs, highlighting the need for large-scale datasets and benchmarks for LLM preference alignment. In this paper, we introduce CodeUltraFeedback, a preference dataset of 10,000 complex instructions to tune and align LLMs to coding preferences through AI feedback. We generate responses to the instructions using a pool of 14 diverse LLMs, which we then annotate according to their alignment with five coding preferences using the LLM-as-a-Judge approach with GPT-3.5, producing both numerical and textual feedback. We also present CODAL-Bench, a benchmark for assessing LLM alignment with these coding preferences. Our results show that CodeLlama-7B-Instruct, aligned through reinforcement learning from AI feedback (RLAIF) with direct preference optimization (DPO) using CodeUltraFeedback's AI feedback data, outperforms 34B LLMs on CODAL-Bench, validating the utility of CodeUltraFeedback for preference tuning. Furthermore, we show our DPO-aligned CodeLlama model improves functional correctness on HumanEval+ compared to the unaligned base model. Therefore, our contributions bridge the gap in preference tuning of LLMs for code and set the stage for further advancements in model alignment and RLAIF for code intelligence. Our code and data are available at https://github.com/martin-wey/CodeUltraFeedback.
CodeLL: A Lifelong Learning Dataset to Support the Co-Evolution of Data and Language Models of Code
Dec 20, 2023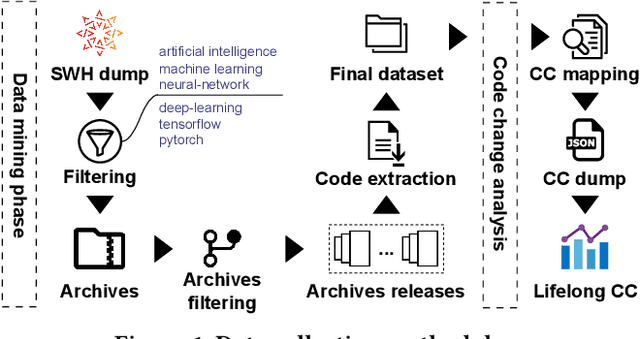
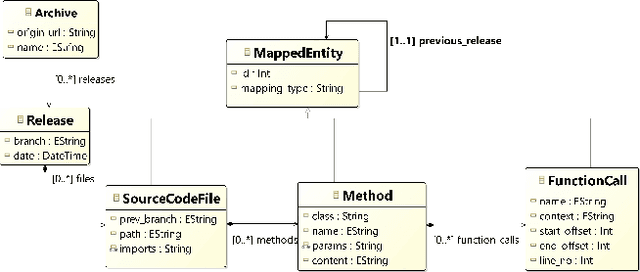
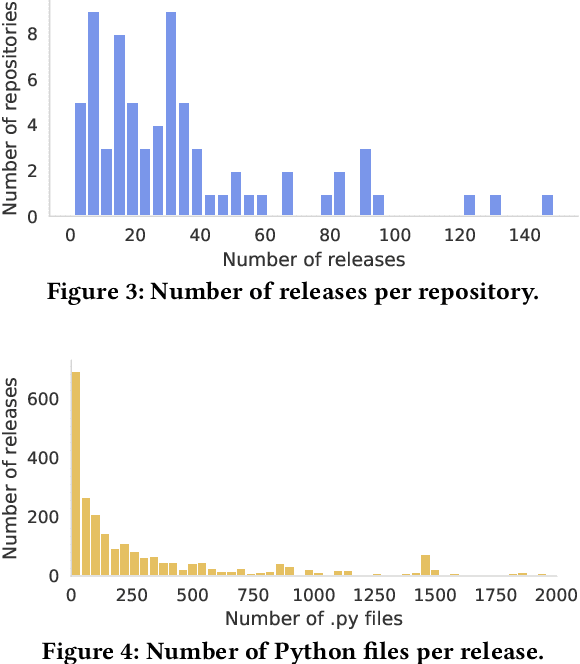
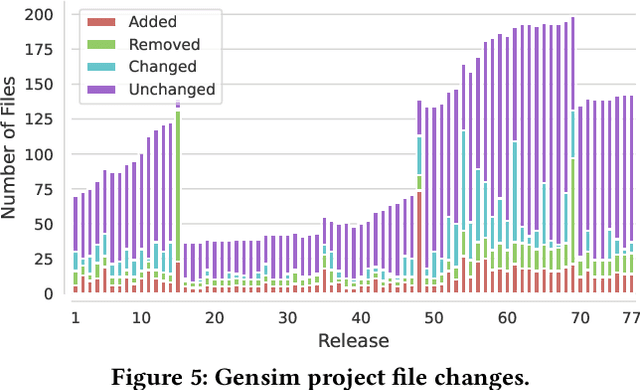
Motivated by recent work on lifelong learning applications for language models (LMs) of code, we introduce CodeLL, a lifelong learning dataset focused on code changes. Our contribution addresses a notable research gap marked by the absence of a long-term temporal dimension in existing code change datasets, limiting their suitability in lifelong learning scenarios. In contrast, our dataset aims to comprehensively capture code changes across the entire release history of open-source software repositories. In this work, we introduce an initial version of CodeLL, comprising 71 machine-learning-based projects mined from Software Heritage. This dataset enables the extraction and in-depth analysis of code changes spanning 2,483 releases at both the method and API levels. CodeLL enables researchers studying the behaviour of LMs in lifelong fine-tuning settings for learning code changes. Additionally, the dataset can help studying data distribution shifts within software repositories and the evolution of API usages over time.
Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with Large Language Models
Aug 21, 2023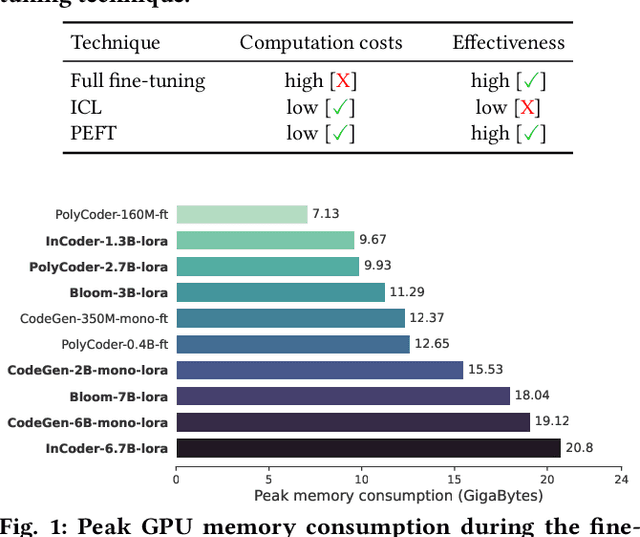


Large Language Models (LLMs) possess impressive capabilities to generate meaningful code snippets given natural language intents in zero-shot, i.e., without the need for specific fine-tuning. In the perspective of unleashing their full potential, prior work has demonstrated the benefits of fine-tuning the models to task-specific data. However, fine-tuning process demands heavy computational costs and is intractable when resources are scarce, especially for models with billions of parameters. In light of these challenges, previous studies explored In-Context Learning (ICL) as an effective strategy to generate contextually appropriate code without fine-tuning. However, it operates at inference time and does not involve learning task-specific parameters, potentially limiting the model's performance on downstream tasks. In this context, we foresee that Parameter-Efficient Fine-Tuning (PEFT) techniques carry a high potential for efficiently specializing LLMs to task-specific data. In this paper, we deliver a comprehensive study of LLMs with the impact of PEFT techniques under the automated code generation scenario. Our experimental results reveal the superiority and potential of such techniques over ICL on a wide range of LLMs in reducing the computational burden and improving performance. Therefore, the study opens opportunities for broader applications of PEFT in software engineering scenarios.
On the Usage of Continual Learning for Out-of-Distribution Generalization in Pre-trained Language Models of Code
May 06, 2023Pre-trained language models (PLMs) have become a prevalent technique in deep learning for code, utilizing a two-stage pre-training and fine-tuning procedure to acquire general knowledge about code and specialize in a variety of downstream tasks. However, the dynamic nature of software codebases poses a challenge to the effectiveness and robustness of PLMs. In particular, world-realistic scenarios potentially lead to significant differences between the distribution of the pre-training and test data, i.e., distribution shift, resulting in a degradation of the PLM's performance on downstream tasks. In this paper, we stress the need for adapting PLMs of code to software data whose distribution changes over time, a crucial problem that has been overlooked in previous works. The motivation of this work is to consider the PLM in a non-stationary environment, where fine-tuning data evolves over time according to a software evolution scenario. Specifically, we design a scenario where the model needs to learn from a stream of programs containing new, unseen APIs over time. We study two widely used PLM architectures, i.e., a GPT2 decoder and a RoBERTa encoder, on two downstream tasks, API call and API usage prediction. We demonstrate that the most commonly used fine-tuning technique from prior work is not robust enough to handle the dynamic nature of APIs, leading to the loss of previously acquired knowledge i.e., catastrophic forgetting. To address these issues, we implement five continual learning approaches, including replay-based and regularization-based methods. Our findings demonstrate that utilizing these straightforward methods effectively mitigates catastrophic forgetting in PLMs across both downstream tasks while achieving comparable or superior performance.
Towards using Few-Shot Prompt Learning for Automating Model Completion
Dec 07, 2022We propose a simple yet a novel approach to improve completion in domain modeling activities. Our approach exploits the power of large language models by using few-shot prompt learning without the need to train or fine-tune those models with large datasets that are scarce in this field. We implemented our approach and tested it on the completion of static and dynamic domain diagrams. Our initial evaluation shows that such an approach is effective and can be integrated in different ways during the modeling activities.
Towards Automatically Extracting UML Class Diagrams from Natural Language Specifications
Oct 27, 2022



In model-driven engineering (MDE), UML class diagrams serve as a way to plan and communicate between developers. However, it is complex and resource-consuming. We propose an automated approach for the extraction of UML class diagrams from natural language software specifications. To develop our approach, we create a dataset of UML class diagrams and their English specifications with the help of volunteers. Our approach is a pipeline of steps consisting of the segmentation of the input into sentences, the classification of the sentences, the generation of UML class diagram fragments from sentences, and the composition of these fragments into one UML class diagram. We develop a quantitative testing framework specific to UML class diagram extraction. Our approach yields low precision and recall but serves as a benchmark for future research.