 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Large Language Models with Static Analyzers for Code Review Generation
Feb 10, 2025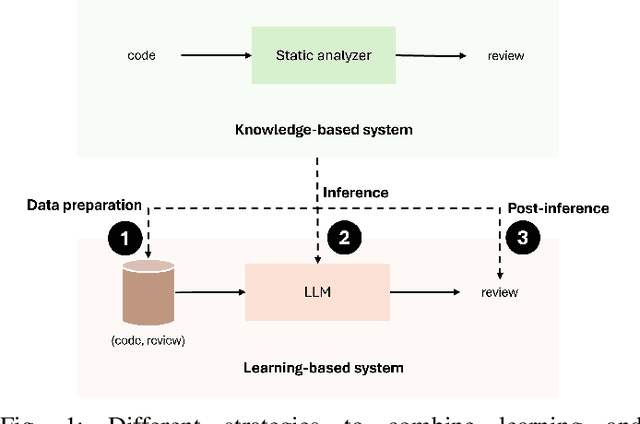
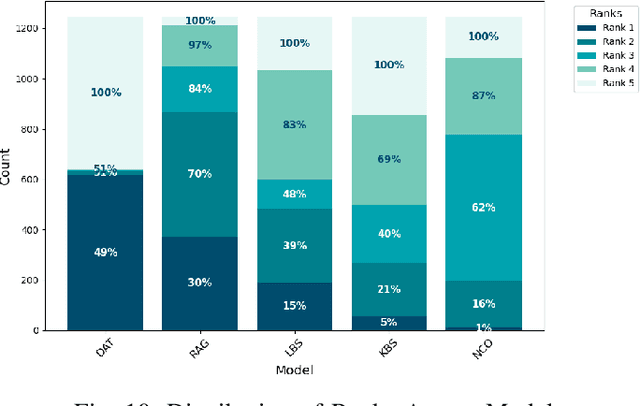

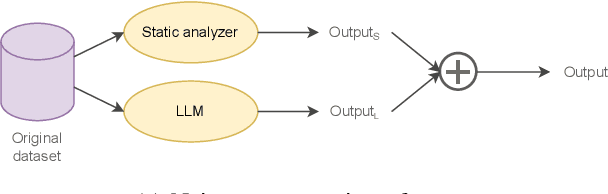
Code review is a crucial but often complex, subjective, and time-consuming activity in software development. Over the past decades, significant efforts have been made to automate this process. Early approaches focused on knowledge-based systems (KBS) that apply rule-based mechanisms to detect code issues, providing precise feedback but struggling with complex, context-dependent cases. More recent work has shifted toward fine-tuning pre-trained language models for code review, enabling broader issue coverage but often at the expense of precision. In this paper, we propose a hybrid approach that combines the strengths of KBS and learning-based systems (LBS) to generate high-quality, comprehensive code reviews. Our method integrates knowledge at three distinct stages of the language model pipeline: during data preparation (Data-Augmented Training, DAT), at inference (Retrieval-Augmented Generation, RAG), and after inference (Naive Concatenation of Outputs, NCO). We empirically evaluate our combination strategies against standalone KBS and LBS fine-tuned on a real-world dataset. Our results show that these hybrid strategies enhance the relevance, completeness, and overall quality of review comments, effectively bridging the gap between rule-based tools and deep learning models.