 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Mixed Interest Extraction and Heterogeneous Interaction: A Scalable CTR Model for Industrial Recommender Systems
Feb 12, 2026Learning effective feature interactions is central to modern recommender systems, yet remains challenging in industrial settings due to sparse multi-field inputs and ultra-long user behavior sequences. While recent scaling efforts have improved model capacity, they often fail to construct both context-aware and context-independent user intent from the long-term and real-time behavior sequence. Meanwhile, recent work also suffers from inefficient and homogeneous interaction mechanisms, leading to suboptimal prediction performance. To address these limitations, we propose HeMix, a scalable ranking model that unifies adaptive sequence tokenization and heterogeneous interaction structure. Specifically, HeMix introduces a Query-Mixed Interest Extraction module that jointly models context-aware and context-independent user interests via dynamic and fixed queries over global and real-time behavior sequences. For interaction, we replace self-attention with the HeteroMixer block, enabling efficient, multi-granularity cross-feature interactions that adopt the multi-head token fusion, heterogeneous interaction and group-aligned reconstruction pipelines. HeMix demonstrates favorable scaling behavior, driven by the HeteroMixer block, where increasing model scale via parameter expansion leads to steady improvements in recommendation accuracy. Experiments on industrial-scale datasets show that HeMix scales effectively and consistently outperforms strong baselines. Most importantly, HeMix has been deployed on the AMAP platform, delivering significant online gains over DLRM: +3.61\% GMV, +2.78\% PV\_CTR, and +2.12\% UV\_CVR.
GeoGR: A Generative Retrieval Framework for Spatio-Temporal Aware POI Recommendation
Feb 11, 2026Next Point-of-Interest (POI) prediction is a fundamental task in location-based services, especially critical for large-scale navigation platforms like AMAP that serve billions of users across diverse lifestyle scenarios. While recent POI recommendation approaches based on SIDs have achieved promising, they struggle in complex, sparse real-world environments due to two key limitations: (1) inadequate modeling of high-quality SIDs that capture cross-category spatio-temporal collaborative relationships, and (2) poor alignment between large language models (LLMs) and the POI recommendation task. To this end, we propose GeoGR, a geographic generative recommendation framework tailored for navigation-based LBS like AMAP, which perceives users' contextual state changes and enables intent-aware POI recommendation. GeoGR features a two-stage design: (i) a geo-aware SID tokenization pipeline that explicitly learns spatio-temporal collaborative semantic representations via geographically constrained co-visited POI pairs, contrastive learning, and iterative refinement; and (ii) a multi-stage LLM training strategy that aligns non-native SID tokens through multiple template-based continued pre-training(CPT) and enables autoregressive POI generation via supervised fine-tuning(SFT). Extensive experiments on multiple real-world datasets demonstrate GeoGR's superiority over state-of-the-art baselines. Moreover, deployment on the AMAP platform, serving millions of users with multiple online metrics boosting, confirms its practical effectiveness and scalability in production.
Generative Reasoning Re-ranker
Feb 08, 2026Recent studies increasingly explore Large Language Models (LLMs) as a new paradigm for recommendation systems due to their scalability and world knowledge. However, existing work has three key limitations: (1) most efforts focus on retrieval and ranking, while the reranking phase, critical for refining final recommendations, is largely overlooked; (2) LLMs are typically used in zero-shot or supervised fine-tuning settings, leaving their reasoning abilities, especially those enhanced through reinforcement learning (RL) and high-quality reasoning data, underexploited; (3) items are commonly represented by non-semantic IDs, creating major scalability challenges in industrial systems with billions of identifiers. To address these gaps, we propose the Generative Reasoning Reranker (GR2), an end-to-end framework with a three-stage training pipeline tailored for reranking. First, a pretrained LLM is mid-trained on semantic IDs encoded from non-semantic IDs via a tokenizer achieving $\ge$99% uniqueness. Next, a stronger larger-scale LLM generates high-quality reasoning traces through carefully designed prompting and rejection sampling, which are used for supervised fine-tuning to impart foundational reasoning skills. Finally, we apply Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO), enabling scalable RL supervision with verifiable rewards designed specifically for reranking. Experiments on two real-world datasets demonstrate GR2's effectiveness: it surpasses the state-of-the-art OneRec-Think by 2.4% in Recall@5 and 1.3% in NDCG@5. Ablations confirm that advanced reasoning traces yield substantial gains across metrics. We further find that RL reward design is crucial in reranking: LLMs tend to exploit reward hacking by preserving item order, motivating conditional verifiable rewards to mitigate this behavior and optimize reranking performance.
System-integrated intrinsic static-dynamic pressure sensing enabled by charge excitation and 3D gradient engineering for autonomous robotic interaction
May 30, 2025High-resolution pressure sensing that distinguishes static and dynamic inputs is vital for intelligent robotics but remains challenging for self-powered sensors. We present a self-powered intrinsic static-dynamic pressure sensor (iSD Sensor) that integrates charge excitation with a 3D gradient-engineered structure, achieving enhanced voltage outputs-over 25X for static and 15X for dynamic modes. The sensor exhibits multi-region sensitivities (up to 34.7 V/kPa static, 48.4 V/kPa dynamic), a low detection limit of 6.13 Pa, and rapid response/recovery times (83/43 ms). This design enables nuanced tactile perception and supports dual-mode robotic control: proportional actuation via static signals and fast triggering via dynamic inputs. Integrated into a wireless closed-loop system, the iSD Sensor enables precise functions such as finger bending, object grasping, and sign language output.
Spiking Neural Network for Intra-cortical Brain Signal Decoding
Apr 12, 2025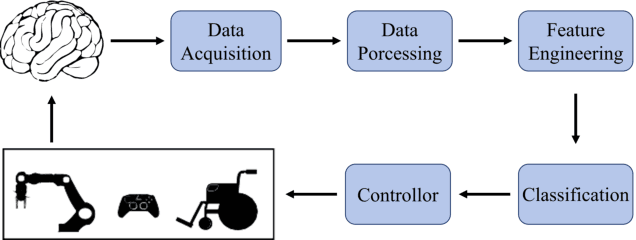
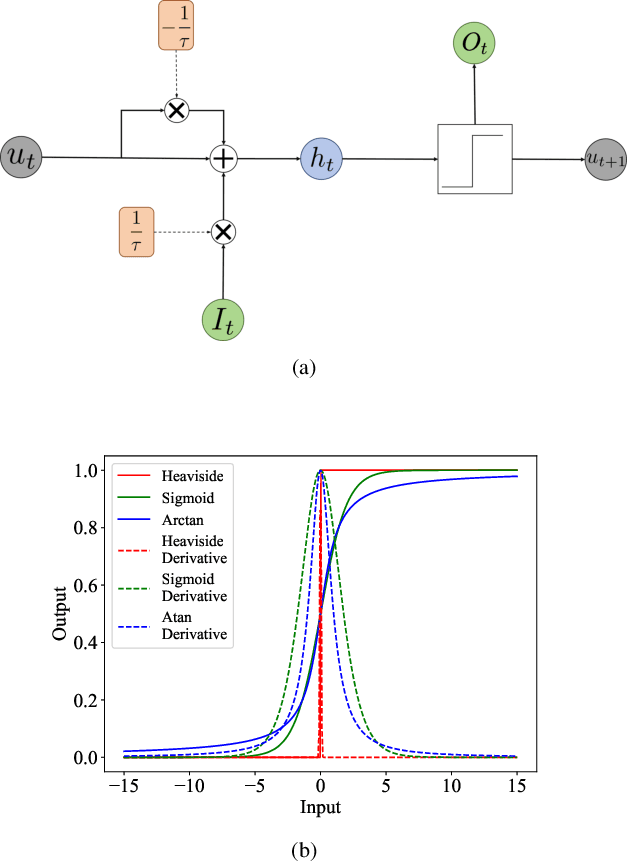
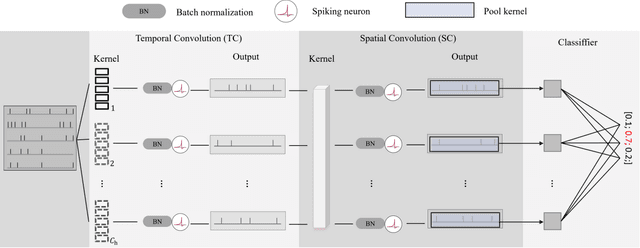
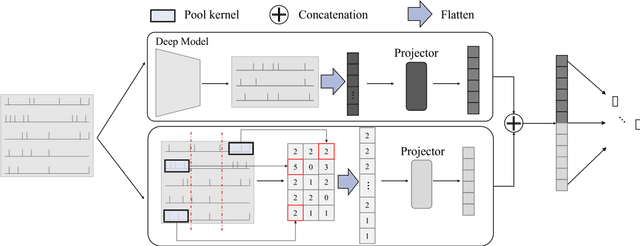
Decoding brain signals accurately and efficiently is crucial for intra-cortical brain-computer interfaces. Traditional decoding approaches based on neural activity vector features suffer from low accuracy, whereas deep learning based approaches have high computational cost. To improve both the decoding accuracy and efficiency, this paper proposes a spiking neural network (SNN) for effective and energy-efficient intra-cortical brain signal decoding. We also propose a feature fusion approach, which integrates the manually extracted neural activity vector features with those extracted by a deep neural network, to further improve the decoding accuracy. Experiments in decoding motor-related intra-cortical brain signals of two rhesus macaques demonstrated that our SNN model achieved higher accuracy than traditional artificial neural networks; more importantly, it was tens or hundreds of times more efficient. The SNN model is very suitable for high precision and low power applications like intra-cortical brain-computer interfaces.
D3-Guard: Acoustic-based Drowsy Driving Detection Using Smartphones
Mar 30, 2025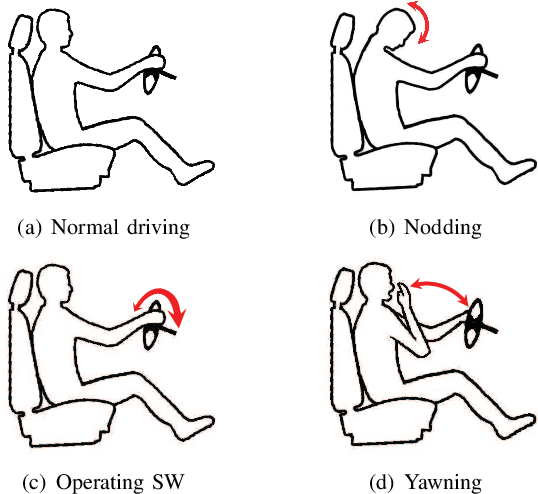
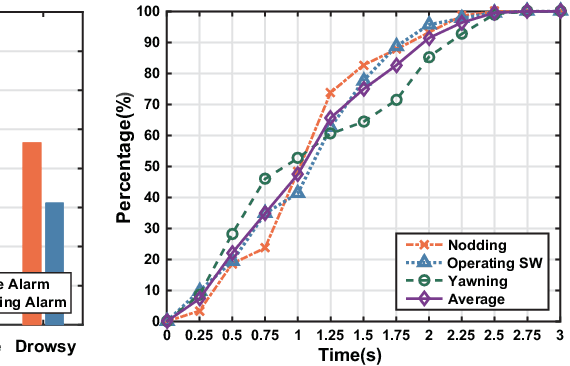

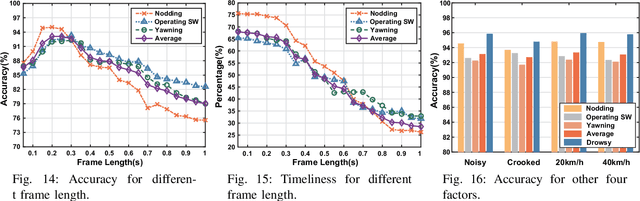
Since the number of cars has grown rapidly in recent years, driving safety draws more and more public attention. Drowsy driving is one of the biggest threatens to driving safety. Therefore, a simple but robust system that can detect drowsy driving with commercial off-the-shelf devices (such as smartphones) is very necessary. With this motivation, we explore the feasibility of purely using acoustic sensors embedded in smartphones to detect drowsy driving. We first study characteristics of drowsy driving, and find some unique patterns of Doppler shift caused by three typical drowsy behaviors, i.e. nodding, yawning and operating steering wheel. We then validate our important findings through empirical analysis of the driving data collected from real driving environments. We further propose a real-time Drowsy Driving Detection system (D3-Guard) based on audio devices embedded in smartphones. In order to improve the performance of our system, we adopt an effective feature extraction method based on undersampling technique and FFT, and carefully design a high-accuracy detector based on LSTM networks for the early detection of drowsy driving. Through extensive experiments with 5 volunteer drivers in real driving environments, our system can distinguish drowsy driving actions with an average total accuracy of 93.31% in real-time. Over 80% drowsy driving actions can be detected within first 70% of action duration.
HearSmoking: Smoking Detection in Driving Environment via Acoustic Sensing on Smartphones
Mar 30, 2025



Driving safety has drawn much public attention in recent years due to the fast-growing number of cars. Smoking is one of the threats to driving safety but is often ignored by drivers. Existing works on smoking detection either work in contact manner or need additional devices. This motivates us to explore the practicability of using smartphones to detect smoking events in driving environment. In this paper, we propose a cigarette smoking detection system, named HearSmoking, which only uses acoustic sensors on smartphones to improve driving safety. After investigating typical smoking habits of drivers, including hand movement and chest fluctuation, we design an acoustic signal to be emitted by the speaker and received by the microphone. We calculate Relative Correlation Coefficient of received signals to obtain movement patterns of hands and chest. The processed data is sent into a trained Convolutional Neural Network for classification of hand movement. We also design a method to detect respiration at the same time. To improve system performance, we further analyse the periodicity of the composite smoking motion. Through extensive experiments in real driving environments, HearSmoking detects smoking events with an average total accuracy of 93.44 percent in real-time.
Data Pricing for Graph Neural Networks without Pre-purchased Inspection
Feb 12, 2025



Machine learning (ML) models have become essential tools in various scenarios. Their effectiveness, however, hinges on a substantial volume of data for satisfactory performance. Model marketplaces have thus emerged as crucial platforms bridging model consumers seeking ML solutions and data owners possessing valuable data. These marketplaces leverage model trading mechanisms to properly incentive data owners to contribute their data, and return a well performing ML model to the model consumers. However, existing model trading mechanisms often assume the data owners are willing to share their data before being paid, which is not reasonable in real world. Given that, we propose a novel mechanism, named Structural Importance based Model Trading (SIMT) mechanism, that assesses the data importance and compensates data owners accordingly without disclosing the data. Specifically, SIMT procures feature and label data from data owners according to their structural importance, and then trains a graph neural network for model consumers. Theoretically, SIMT ensures incentive compatible, individual rational and budget feasible. The experiments on five popular datasets validate that SIMT consistently outperforms vanilla baselines by up to $40\%$ in both MacroF1 and MicroF1.
ReARTeR: Retrieval-Augmented Reasoning with Trustworthy Process Rewarding
Jan 14, 2025Retrieval-Augmented Generation (RAG) systems for Large Language Models (LLMs) hold promise in knowledge-intensive tasks but face limitations in complex multi-step reasoning. While recent methods have integrated RAG with chain-of-thought reasoning or test-time search using Process Reward Models (PRMs), these approaches encounter challenges such as a lack of explanations, bias in PRM training data, early-step bias in PRM scores, and insufficient post-training optimization of reasoning potential. To address these issues, we propose Retrieval-Augmented Reasoning through Trustworthy Process Rewarding (ReARTeR), a framework that enhances RAG systems' reasoning capabilities through post-training and test-time scaling. At test time, ReARTeR introduces Trustworthy Process Rewarding via a Process Reward Model for accurate scalar scoring and a Process Explanation Model (PEM) for generating natural language explanations, enabling step refinement. During post-training, it utilizes Monte Carlo Tree Search guided by Trustworthy Process Rewarding to collect high-quality step-level preference data, optimized through Iterative Preference Optimization. ReARTeR addresses three core challenges: (1) misalignment between PRM and PEM, tackled through off-policy preference learning; (2) bias in PRM training data, mitigated by balanced annotation methods and stronger annotations for challenging examples; and (3) early-step bias in PRM, resolved through a temporal-difference-based look-ahead search strategy. Experimental results on multi-step reasoning benchmarks demonstrate significant improvements, underscoring ReARTeR's potential to advance the reasoning capabilities of RAG systems.
Target-Prompt Online Graph Collaborative Learning for Temporal QoS Prediction
Aug 20, 2024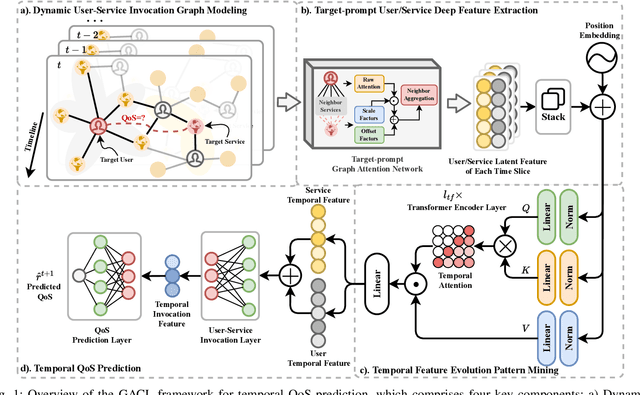
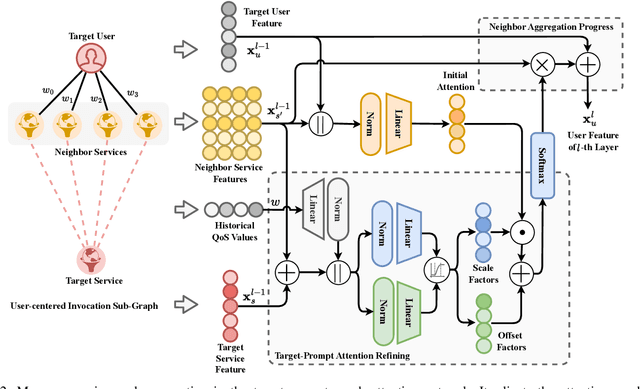

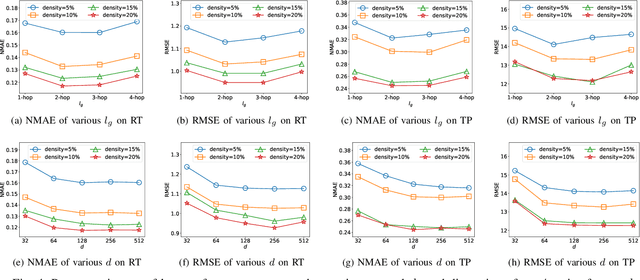
In service-oriented architecture, accurately predicting the Quality of Service (QoS) is vital for maintaining reliability and enhancing user satisfaction. However, current methods often neglect high-order latent collaborative relationships and fail to dynamically adjust feature learning for specific user-service invocations, which are critical for precise feature extraction. Moreover, relying on RNNs to capture QoS evolution limits the ability to detect long-term trends due to challenges in managing long-range dependencies. To address these issues, we propose the Target-Prompt Online Graph Collaborative Learning (TOGCL) framework for temporal QoS prediction. It leverages a dynamic user-service invocation graph to comprehensively model historical interactions. Building on this graph, it develops a target-prompt graph attention network to extract online deep latent features of users and services at each time slice, considering implicit target-neighboring collaborative relationships and historical QoS values. Additionally, a multi-layer Transformer encoder is employed to uncover temporal feature evolution patterns, enhancing temporal QoS prediction. Extensive experiments on the WS-DREAM dataset demonstrate that TOGCL significantly outperforms state-of-the-art methods across multiple metrics, achieving improvements of up to 38.80\%. These results underscore the effectiveness of TOGCL for temporal QoS prediction.