 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Search with Hierarchical Meta-Cognitive Monitoring Inspired by Cognitive Neuroscience
Jan 30, 2026Deep search agents powered by large language models have demonstrated strong capabilities in multi-step retrieval, reasoning, and long-horizon task execution. However, their practical failures often stem from the lack of mechanisms to monitor and regulate reasoning and retrieval states as tasks evolve under uncertainty. Insights from cognitive neuroscience suggest that human metacognition is hierarchically organized, integrating fast anomaly detection with selectively triggered, experience-driven reflection. In this work, we propose Deep Search with Meta-Cognitive Monitoring (DS-MCM), a deep search framework augmented with an explicit hierarchical metacognitive monitoring mechanism. DS-MCM integrates a Fast Consistency Monitor, which performs lightweight checks on the alignment between external evidence and internal reasoning confidence, and a Slow Experience-Driven Monitor, which is selectively activated to guide corrective intervention based on experience memory from historical agent trajectories. By embedding monitoring directly into the reasoning-retrieval loop, DS-MCM determines both when intervention is warranted and how corrective actions should be informed by prior experience. Experiments across multiple deep search benchmarks and backbone models demonstrate that DS-MCM consistently improves performance and robustness.
When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
Jan 16, 2026Personalized large language models (LLMs) adapt model behavior to individual users to enhance user satisfaction, yet personalization can inadvertently distort factual reasoning. We show that when personalized LLMs face factual queries, there exists a phenomenon where the model generates answers aligned with a user's prior history rather than the objective truth, resulting in personalization-induced hallucinations that degrade factual reliability and may propagate incorrect beliefs, due to representational entanglement between personalization and factual representations. To address this issue, we propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time approach that mitigates personalization-induced factual distortions while preserving personalized behavior. We further introduce PFQABench, the first benchmark designed to jointly evaluate factual and personalized question answering under personalization. Experiments across multiple LLM backbones and personalization methods show that FPPS substantially improves factual accuracy while maintaining personalized performance.
Streaming Hallucination Detection in Long Chain-of-Thought Reasoning
Jan 05, 2026Long chain-of-thought (CoT) reasoning improves the performance of large language models, yet hallucinations in such settings often emerge subtly and propagate across reasoning steps. We suggest that hallucination in long CoT reasoning is better understood as an evolving latent state rather than a one-off erroneous event. Accordingly, we treat step-level hallucination judgments as local observations and introduce a cumulative prefix-level hallucination signal that tracks the global evolution of the reasoning state over the entire trajectory. Overall, our approach enables streaming hallucination detection in long CoT reasoning, providing real-time, interpretable evidence.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
StyliTruth : Unlocking Stylized yet Truthful LLM Generation via Disentangled Steering
Aug 06, 2025Generating stylized large language model (LLM) responses via representation editing is a promising way for fine-grained output control. However, there exists an inherent trade-off: imposing a distinctive style often degrades truthfulness. Existing representation editing methods, by naively injecting style signals, overlook this collateral impact and frequently contaminate the model's core truthfulness representations, resulting in reduced answer correctness. We term this phenomenon stylization-induced truthfulness collapse. We attribute this issue to latent coupling between style and truth directions in certain key attention heads, and propose StyliTruth, a mechanism that preserves stylization while keeping truthfulness intact. StyliTruth separates the style-relevant and truth-relevant subspaces in the model's representation space via an orthogonal deflation process. This decomposition enables independent control of style and truth in their own subspaces, minimizing interference. By designing adaptive, token-level steering vectors within each subspace, we dynamically and precisely control the generation process to maintain both stylistic fidelity and truthfulness. We validate our method on multiple styles and languages. Extensive experiments and analyses show that StyliTruth significantly reduces stylization-induced truthfulness collapse and outperforms existing inference-time intervention methods in balancing style adherence with truthfulness.
Detection and Mitigation of Hallucination in Large Reasoning Models: A Mechanistic Perspective
May 19, 2025Large Reasoning Models (LRMs) have shown impressive capabilities in multi-step reasoning tasks. However, alongside these successes, a more deceptive form of model error has emerged--Reasoning Hallucination--where logically coherent but factually incorrect reasoning traces lead to persuasive yet faulty conclusions. Unlike traditional hallucinations, these errors are embedded within structured reasoning, making them more difficult to detect and potentially more harmful. In this work, we investigate reasoning hallucinations from a mechanistic perspective. We propose the Reasoning Score, which quantifies the depth of reasoning by measuring the divergence between logits obtained from projecting late layers of LRMs to the vocabulary space, effectively distinguishing shallow pattern-matching from genuine deep reasoning. Using this score, we conduct an in-depth analysis on the ReTruthQA dataset and identify two key reasoning hallucination patterns: early-stage fluctuation in reasoning depth and incorrect backtracking to flawed prior steps. These insights motivate our Reasoning Hallucination Detection (RHD) framework, which achieves state-of-the-art performance across multiple domains. To mitigate reasoning hallucinations, we further introduce GRPO-R, an enhanced reinforcement learning algorithm that incorporates step-level deep reasoning rewards via potential-based shaping. Our theoretical analysis establishes stronger generalization guarantees, and experiments demonstrate improved reasoning quality and reduced hallucination rates.
SyLeR: A Framework for Explicit Syllogistic Legal Reasoning in Large Language Models
Apr 05, 2025Syllogistic reasoning is a fundamental aspect of legal decision-making, enabling logical conclusions by connecting general legal principles with specific case facts. Although existing large language models (LLMs) can generate responses to legal questions, they fail to perform explicit syllogistic reasoning, often producing implicit and unstructured answers that lack explainability and trustworthiness. To address this limitation, we propose SyLeR, a novel framework that empowers LLMs to engage in explicit syllogistic legal reasoning. SyLeR integrates a tree-structured hierarchical retrieval mechanism to effectively combine relevant legal statutes and precedent cases, forming comprehensive major premises. This is followed by a two-stage fine-tuning process: supervised fine-tuning warm-up establishes a foundational understanding of syllogistic reasoning, while reinforcement learning with a structure-aware reward mechanism refines the ability of the model to generate diverse logically sound and well-structured reasoning paths. We conducted extensive experiments across various dimensions, including in-domain and cross-domain user groups (legal laypersons and practitioners), multiple languages (Chinese and French), and different LLM backbones (legal-specific and open-domain LLMs). The results show that SyLeR significantly improves response accuracy and consistently delivers explicit, explainable, and trustworthy legal reasoning.
QE-RAG: A Robust Retrieval-Augmented Generation Benchmark for Query Entry Errors
Apr 05, 2025
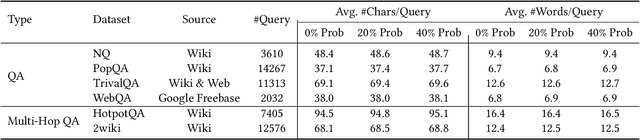
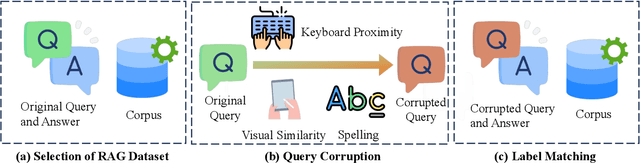
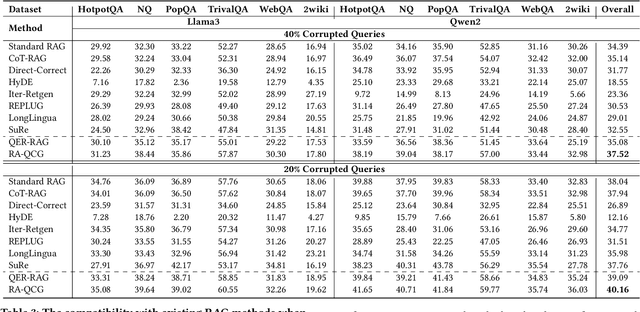
Retriever-augmented generation (RAG) has become a widely adopted approach for enhancing the factual accuracy of large language models (LLMs). While current benchmarks evaluate the performance of RAG methods from various perspectives, they share a common assumption that user queries used for retrieval are error-free. However, in real-world interactions between users and LLMs, query entry errors such as keyboard proximity errors, visual similarity errors, and spelling errors are frequent. The impact of these errors on current RAG methods against such errors remains largely unexplored. To bridge this gap, we propose QE-RAG, the first robust RAG benchmark designed specifically to evaluate performance against query entry errors. We augment six widely used datasets by injecting three common types of query entry errors into randomly selected user queries at rates of 20\% and 40\%, simulating typical user behavior in real-world scenarios. We analyze the impact of these errors on LLM outputs and find that corrupted queries degrade model performance, which can be mitigated through query correction and training a robust retriever for retrieving relevant documents. Based on these insights, we propose a contrastive learning-based robust retriever training method and a retrieval-augmented query correction method. Extensive in-domain and cross-domain experiments reveal that: (1) state-of-the-art RAG methods including sequential, branching, and iterative methods, exhibit poor robustness to query entry errors; (2) our method significantly enhances the robustness of RAG when handling query entry errors and it's compatible with existing RAG methods, further improving their robustness.
CreAgent: Towards Long-Term Evaluation of Recommender System under Platform-Creator Information Asymmetry
Feb 11, 2025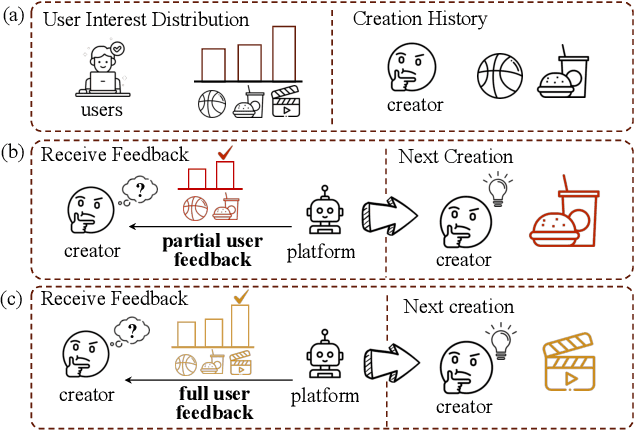
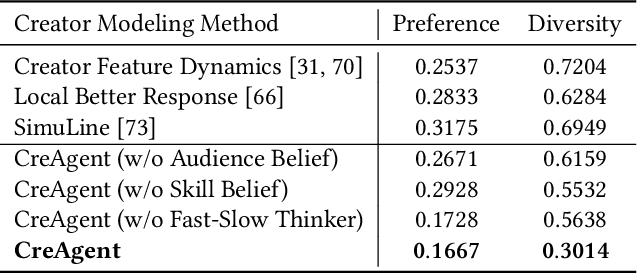
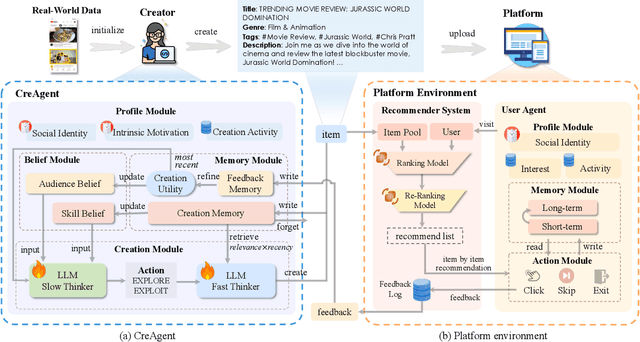
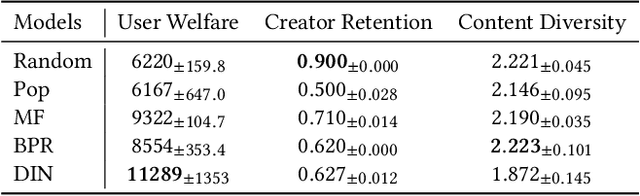
Ensuring the long-term sustainability of recommender systems (RS) emerges as a crucial issue. Traditional offline evaluation methods for RS typically focus on immediate user feedback, such as clicks, but they often neglect the long-term impact of content creators. On real-world content platforms, creators can strategically produce and upload new items based on user feedback and preference trends. While previous studies have attempted to model creator behavior, they often overlook the role of information asymmetry. This asymmetry arises because creators primarily have access to feedback on the items they produce, while platforms possess data on the entire spectrum of user feedback. Current RS simulators, however, fail to account for this asymmetry, leading to inaccurate long-term evaluations. To address this gap, we propose CreAgent, a Large Language Model (LLM)-empowered creator simulation agent. By incorporating game theory's belief mechanism and the fast-and-slow thinking framework, CreAgent effectively simulates creator behavior under conditions of information asymmetry. Additionally, we enhance CreAgent's simulation ability by fine-tuning it using Proximal Policy Optimization (PPO). Our credibility validation experiments show that CreAgent aligns well with the behaviors between real-world platform and creator, thus improving the reliability of long-term RS evaluations. Moreover, through the simulation of RS involving CreAgents, we can explore how fairness- and diversity-aware RS algorithms contribute to better long-term performance for various stakeholders. CreAgent and the simulation platform are publicly available at https://github.com/shawnye2000/CreAgent.
ReARTeR: Retrieval-Augmented Reasoning with Trustworthy Process Rewarding
Jan 14, 2025Retrieval-Augmented Generation (RAG) systems for Large Language Models (LLMs) hold promise in knowledge-intensive tasks but face limitations in complex multi-step reasoning. While recent methods have integrated RAG with chain-of-thought reasoning or test-time search using Process Reward Models (PRMs), these approaches encounter challenges such as a lack of explanations, bias in PRM training data, early-step bias in PRM scores, and insufficient post-training optimization of reasoning potential. To address these issues, we propose Retrieval-Augmented Reasoning through Trustworthy Process Rewarding (ReARTeR), a framework that enhances RAG systems' reasoning capabilities through post-training and test-time scaling. At test time, ReARTeR introduces Trustworthy Process Rewarding via a Process Reward Model for accurate scalar scoring and a Process Explanation Model (PEM) for generating natural language explanations, enabling step refinement. During post-training, it utilizes Monte Carlo Tree Search guided by Trustworthy Process Rewarding to collect high-quality step-level preference data, optimized through Iterative Preference Optimization. ReARTeR addresses three core challenges: (1) misalignment between PRM and PEM, tackled through off-policy preference learning; (2) bias in PRM training data, mitigated by balanced annotation methods and stronger annotations for challenging examples; and (3) early-step bias in PRM, resolved through a temporal-difference-based look-ahead search strategy. Experimental results on multi-step reasoning benchmarks demonstrate significant improvements, underscoring ReARTeR's potential to advance the reasoning capabilities of RAG systems.