 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret-aware Re-ranking for Guaranteeing Two-sided Fairness and Accuracy in Recommender Systems
Apr 20, 2025



In multi-stakeholder recommender systems (RS), users and providers operate as two crucial and interdependent roles, whose interests must be well-balanced. Prior research, including our work BankFair, has demonstrated the importance of guaranteeing both provider fairness and user accuracy to meet their interests. However, when they balance the two objectives, another critical factor emerges in RS: individual fairness, which manifests as a significant disparity in individual recommendation accuracy, with some users receiving high accuracy while others are left with notably low accuracy. This oversight severely harms the interests of users and exacerbates social polarization. How to guarantee individual fairness while ensuring user accuracy and provider fairness remains an unsolved problem. To bridge this gap, in this paper, we propose our method BankFair+. Specifically, BankFair+ extends BankFair with two steps: (1) introducing a non-linear function from regret theory to ensure individual fairness while enhancing user accuracy; (2) formulating the re-ranking process as a regret-aware fuzzy programming problem to meet the interests of both individual user and provider, therefore balancing the trade-off between individual fairness and provider fairness. Experiments on two real-world recommendation datasets demonstrate that BankFair+ outperforms all baselines regarding individual fairness, user accuracy, and provider fairness.
FairDiverse: A Comprehensive Toolkit for Fair and Diverse Information Retrieval Algorithms
Feb 17, 2025In modern information retrieval (IR). achieving more than just accuracy is essential to sustaining a healthy ecosystem, especially when addressing fairness and diversity considerations. To meet these needs, various datasets, algorithms, and evaluation frameworks have been introduced. However, these algorithms are often tested across diverse metrics, datasets, and experimental setups, leading to inconsistencies and difficulties in direct comparisons. This highlights the need for a comprehensive IR toolkit that enables standardized evaluation of fairness- and diversity-aware algorithms across different IR tasks. To address this challenge, we present FairDiverse, an open-source and standardized toolkit. FairDiverse offers a framework for integrating fair and diverse methods, including pre-processing, in-processing, and post-processing techniques, at different stages of the IR pipeline. The toolkit supports the evaluation of 28 fairness and diversity algorithms across 16 base models, covering two core IR tasks (search and recommendation) thereby establishing a comprehensive benchmark. Moreover, FairDiverse is highly extensible, providing multiple APIs that empower IR researchers to swiftly develop and evaluate their own fairness and diversity aware models, while ensuring fair comparisons with existing baselines. The project is open-sourced and available on https://github.com/XuChen0427/FairDiverse.
CreAgent: Towards Long-Term Evaluation of Recommender System under Platform-Creator Information Asymmetry
Feb 11, 2025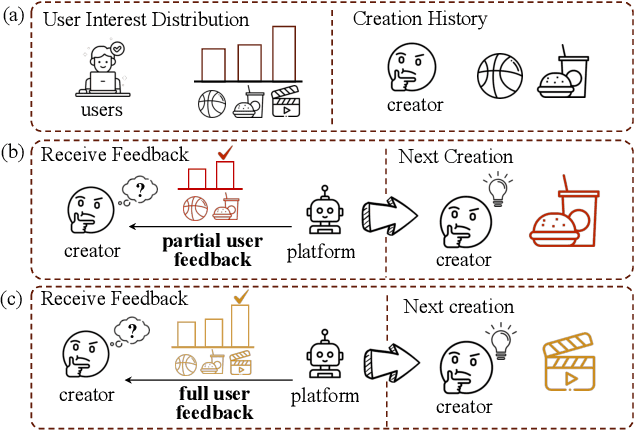
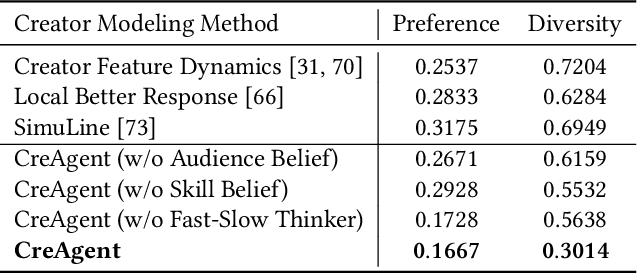
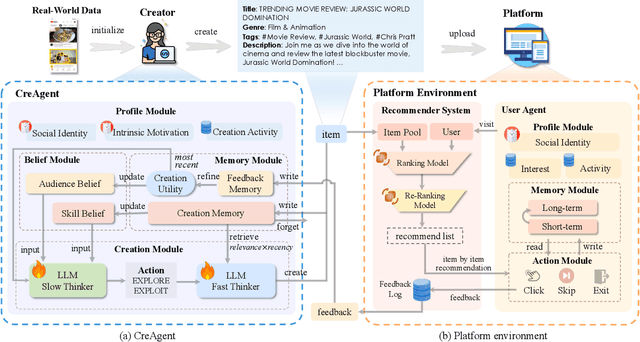
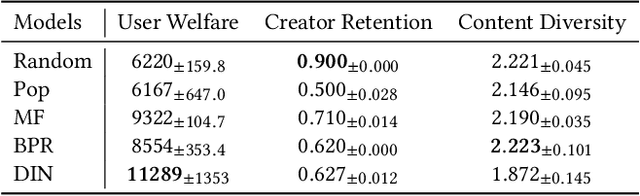
Ensuring the long-term sustainability of recommender systems (RS) emerges as a crucial issue. Traditional offline evaluation methods for RS typically focus on immediate user feedback, such as clicks, but they often neglect the long-term impact of content creators. On real-world content platforms, creators can strategically produce and upload new items based on user feedback and preference trends. While previous studies have attempted to model creator behavior, they often overlook the role of information asymmetry. This asymmetry arises because creators primarily have access to feedback on the items they produce, while platforms possess data on the entire spectrum of user feedback. Current RS simulators, however, fail to account for this asymmetry, leading to inaccurate long-term evaluations. To address this gap, we propose CreAgent, a Large Language Model (LLM)-empowered creator simulation agent. By incorporating game theory's belief mechanism and the fast-and-slow thinking framework, CreAgent effectively simulates creator behavior under conditions of information asymmetry. Additionally, we enhance CreAgent's simulation ability by fine-tuning it using Proximal Policy Optimization (PPO). Our credibility validation experiments show that CreAgent aligns well with the behaviors between real-world platform and creator, thus improving the reliability of long-term RS evaluations. Moreover, through the simulation of RS involving CreAgents, we can explore how fairness- and diversity-aware RS algorithms contribute to better long-term performance for various stakeholders. CreAgent and the simulation platform are publicly available at https://github.com/shawnye2000/CreAgent.
BankFair: Balancing Accuracy and Fairness under Varying User Traffic in Recommender System
May 25, 2024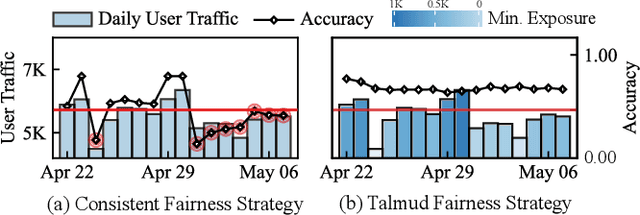

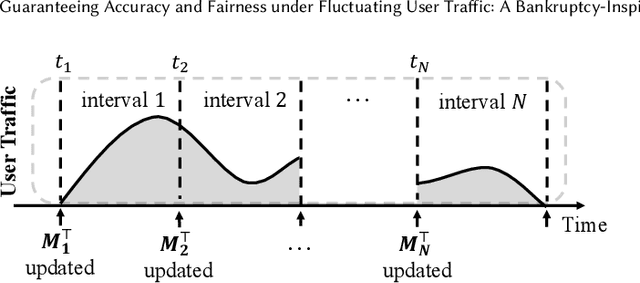
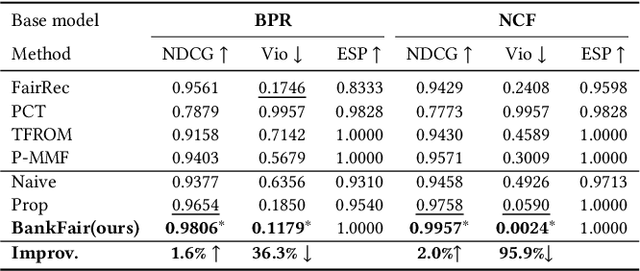
Driven by sustainability and economic considerations, two-sided recommendation platforms are required to satisfy the needs of both users and providers. Previous studies often indicate that the two sides' needs differ in urgency: providers have relatively long-term exposure requirements, while users desire short-term, accurate services. However, our empirical study reveals that existing methods for balancing fairness and accuracy often fail to ensure both long-term fairness and short-term accuracy under fluctuating user traffic in real applications. Notably, when user traffic is low, user experience tends to decline significantly. Then, we conducted a theoretical analysis confirming that user traffic is a crucial factor in such a trade-off problem. Ensuring accuracy and fairness under variable user traffic remains a challenge. Inspired by the bankruptcy problem in economics, we propose a novel fairness-aware re-ranking approach called BankFair. BankFair intuitively uses the Talmud rule to leverage periods of high user traffic to compensate for periods of low traffic, ensuring consistent user service while maintaining long-term fairness. BankFair is composed of two modules: (1) utilizing the Talmud rule to determine the necessary degree of fairness across varying user traffic periods, and (2) implementing an online re-ranking algorithm based on the fairness degree established by the Talmud rule. Experiments on one publicly available and one real industrial dataset demonstrate that BankFair outperforms all baselines in terms of both accuracy and provider fairness.
A Taxation Perspective for Fair Re-ranking
Apr 27, 2024



Fair re-ranking aims to redistribute ranking slots among items more equitably to ensure responsibility and ethics. The exploration of redistribution problems has a long history in economics, offering valuable insights for conceptualizing fair re-ranking as a taxation process. Such a formulation provides us with a fresh perspective to re-examine fair re-ranking and inspire the development of new methods. From a taxation perspective, we theoretically demonstrate that most previous fair re-ranking methods can be reformulated as an item-level tax policy. Ideally, a good tax policy should be effective and conveniently controllable to adjust ranking resources. However, both empirical and theoretical analyses indicate that the previous item-level tax policy cannot meet two ideal controllable requirements: (1) continuity, ensuring minor changes in tax rates result in small accuracy and fairness shifts; (2) controllability over accuracy loss, ensuring precise estimation of the accuracy loss under a specific tax rate. To overcome these challenges, we introduce a new fair re-ranking method named Tax-rank, which levies taxes based on the difference in utility between two items. Then, we efficiently optimize such an objective by utilizing the Sinkhorn algorithm in optimal transport. Upon a comprehensive analysis, Our model Tax-rank offers a superior tax policy for fair re-ranking, theoretically demonstrating both continuity and controllability over accuracy loss. Experimental results show that Tax-rank outperforms all state-of-the-art baselines in terms of effectiveness and efficiency on recommendation and advertising tasks.
LTP-MMF: Towards Long-term Provider Max-min Fairness Under Recommendation Feedback Loops
Aug 11, 2023



Multi-stakeholder recommender systems involve various roles, such as users, providers. Previous work pointed out that max-min fairness (MMF) is a better metric to support weak providers. However, when considering MMF, the features or parameters of these roles vary over time, how to ensure long-term provider MMF has become a significant challenge. We observed that recommendation feedback loops (named RFL) will influence the provider MMF greatly in the long term. RFL means that recommender system can only receive feedback on exposed items from users and update recommender models incrementally based on this feedback. When utilizing the feedback, the recommender model will regard unexposed item as negative. In this way, tail provider will not get the opportunity to be exposed, and its items will always be considered as negative samples. Such phenomenons will become more and more serious in RFL. To alleviate the problem, this paper proposes an online ranking model named Long-Term Provider Max-min Fairness (named LTP-MMF). Theoretical analysis shows that the long-term regret of LTP-MMF enjoys a sub-linear bound. Experimental results on three public recommendation benchmarks demonstrated that LTP-MMF can outperform the baselines in the long term.