 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Reproducibility Study of BSARec for Sequential Recommendation
Dec 19, 2025



In sequential recommendation (SR), the self-attention mechanism of Transformer-based models acts as a low-pass filter, limiting their ability to capture high-frequency signals that reflect short-term user interests. To overcome this, BSARec augments the Transformer encoder with a frequency layer that rescales high-frequency components using the Fourier transform. However, the overall effectiveness of BSARec and the roles of its individual components have yet to be systematically validated. We reproduce BSARec and show that it outperforms other SR methods on some datasets. To empirically assess whether BSARec improves performance on high-frequency signals, we propose a metric to quantify user history frequency and evaluate SR methods across different user groups. We compare digital signal processing (DSP) techniques and find that the discrete wavelet transform (DWT) offer only slight improvements over Fourier transforms, and DSP methods provide no clear advantage over simple residual connections. Finally, we explore padding strategies and find that non-constant padding significantly improves recommendation performance, whereas constant padding hinders the frequency rescaler's ability to capture high-frequency signals.
FairDiverse: A Comprehensive Toolkit for Fair and Diverse Information Retrieval Algorithms
Feb 17, 2025In modern information retrieval (IR). achieving more than just accuracy is essential to sustaining a healthy ecosystem, especially when addressing fairness and diversity considerations. To meet these needs, various datasets, algorithms, and evaluation frameworks have been introduced. However, these algorithms are often tested across diverse metrics, datasets, and experimental setups, leading to inconsistencies and difficulties in direct comparisons. This highlights the need for a comprehensive IR toolkit that enables standardized evaluation of fairness- and diversity-aware algorithms across different IR tasks. To address this challenge, we present FairDiverse, an open-source and standardized toolkit. FairDiverse offers a framework for integrating fair and diverse methods, including pre-processing, in-processing, and post-processing techniques, at different stages of the IR pipeline. The toolkit supports the evaluation of 28 fairness and diversity algorithms across 16 base models, covering two core IR tasks (search and recommendation) thereby establishing a comprehensive benchmark. Moreover, FairDiverse is highly extensible, providing multiple APIs that empower IR researchers to swiftly develop and evaluate their own fairness and diversity aware models, while ensuring fair comparisons with existing baselines. The project is open-sourced and available on https://github.com/XuChen0427/FairDiverse.
Repeat-bias-aware Optimization of Beyond-accuracy Metrics for Next Basket Recommendation
Jan 10, 2025
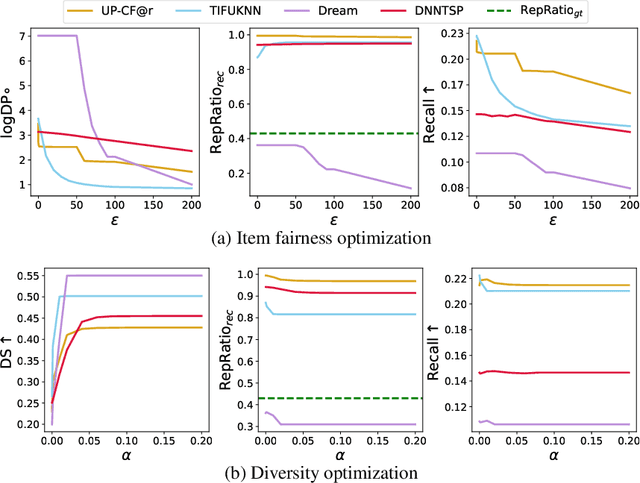
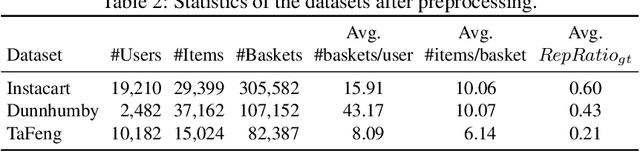
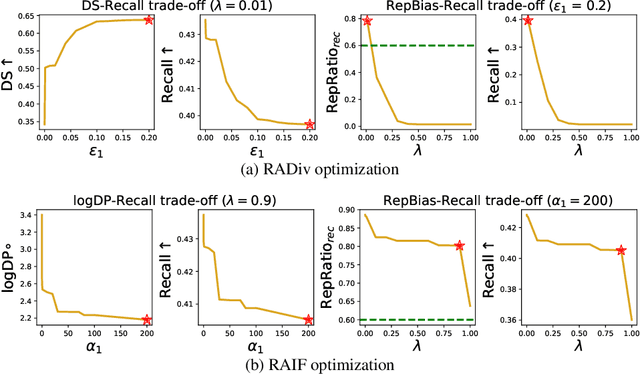
In next basket recommendation (NBR) a set of items is recommended to users based on their historical basket sequences. In many domains, the recommended baskets consist of both repeat items and explore items. Some state-of-the-art NBR methods are heavily biased to recommend repeat items so as to maximize utility. The evaluation and optimization of beyond-accuracy objectives for NBR, such as item fairness and diversity, has attracted increasing attention. How can such beyond-accuracy objectives be pursued in the presence of heavy repeat bias? We find that only optimizing diversity or item fairness without considering repeat bias may cause NBR algorithms to recommend more repeat items. To solve this problem, we propose a model-agnostic repeat-bias-aware optimization algorithm to post-process the recommended results obtained from NBR methods with the objective of mitigating repeat bias when optimizing diversity or item fairness. We consider multiple variations of our optimization algorithm to cater to multiple NBR methods. Experiments on three real-world grocery shopping datasets show that the proposed algorithms can effectively improve diversity and item fairness, and mitigate repeat bias at acceptable Recall loss.
Are We Really Achieving Better Beyond-Accuracy Performance in Next Basket Recommendation?
May 02, 2024Next basket recommendation (NBR) is a special type of sequential recommendation that is increasingly receiving attention. So far, most NBR studies have focused on optimizing the accuracy of the recommendation, whereas optimizing for beyond-accuracy metrics, e.g., item fairness and diversity remains largely unexplored. Recent studies into NBR have found a substantial performance difference between recommending repeat items and explore items. Repeat items contribute most of the users' perceived accuracy compared with explore items. Informed by these findings, we identify a potential "short-cut" to optimize for beyond-accuracy metrics while maintaining high accuracy. To leverage and verify the existence of such short-cuts, we propose a plug-and-play two-step repetition-exploration (TREx) framework that treats repeat items and explores items separately, where we design a simple yet highly effective repetition module to ensure high accuracy, while two exploration modules target optimizing only beyond-accuracy metrics. Experiments are performed on two widely-used datasets w.r.t. a range of beyond-accuracy metrics, viz. five fairness metrics and three diversity metrics. Our experimental results verify the effectiveness of TREx. Prima facie, this appears to be good news: we can achieve high accuracy and improved beyond-accuracy metrics at the same time. However, we argue that the real-world value of our algorithmic solution, TREx, is likely to be limited and reflect on the reasonableness of the evaluation setup. We end up challenging existing evaluation paradigms, particularly in the context of beyond-accuracy metrics, and provide insights for researchers to navigate potential pitfalls and determine reasonable metrics to consider when optimizing for accuracy and beyond-accuracy metrics.