 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Really Achieving Better Beyond-Accuracy Performance in Next Basket Recommendation?
May 02, 2024Next basket recommendation (NBR) is a special type of sequential recommendation that is increasingly receiving attention. So far, most NBR studies have focused on optimizing the accuracy of the recommendation, whereas optimizing for beyond-accuracy metrics, e.g., item fairness and diversity remains largely unexplored. Recent studies into NBR have found a substantial performance difference between recommending repeat items and explore items. Repeat items contribute most of the users' perceived accuracy compared with explore items. Informed by these findings, we identify a potential "short-cut" to optimize for beyond-accuracy metrics while maintaining high accuracy. To leverage and verify the existence of such short-cuts, we propose a plug-and-play two-step repetition-exploration (TREx) framework that treats repeat items and explores items separately, where we design a simple yet highly effective repetition module to ensure high accuracy, while two exploration modules target optimizing only beyond-accuracy metrics. Experiments are performed on two widely-used datasets w.r.t. a range of beyond-accuracy metrics, viz. five fairness metrics and three diversity metrics. Our experimental results verify the effectiveness of TREx. Prima facie, this appears to be good news: we can achieve high accuracy and improved beyond-accuracy metrics at the same time. However, we argue that the real-world value of our algorithmic solution, TREx, is likely to be limited and reflect on the reasonableness of the evaluation setup. We end up challenging existing evaluation paradigms, particularly in the context of beyond-accuracy metrics, and provide insights for researchers to navigate potential pitfalls and determine reasonable metrics to consider when optimizing for accuracy and beyond-accuracy metrics.
Distributional Reinforcement Learning with Dual Expectile-Quantile Regression
May 26, 2023



Successful applications of distributional reinforcement learning with quantile regression prompt a natural question: can we use other statistics to represent the distribution of returns? In particular, expectile regression is known to be more efficient than quantile regression for approximating distributions, especially on extreme values, and by providing a straightforward estimator of the mean it is a natural candidate for reinforcement learning. Prior work has answered this question positively in the case of expectiles, with the major caveat that expensive computations must be performed to ensure convergence. In this work, we propose a dual expectile-quantile approach which solves the shortcomings of previous work while leveraging the complementary properties of expectiles and quantiles. Our method outperforms both quantile-based and expectile-based baselines on the MuJoCo continuous control benchmark.
GLDQN: Explicitly Parameterized Quantile Reinforcement Learning for Waste Reduction
May 30, 2022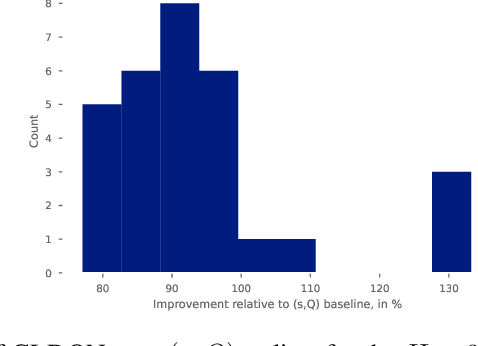
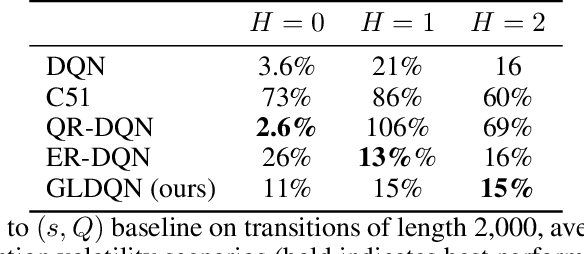
We study the problem of restocking a grocery store's inventory with perishable items over time, from a distributional point of view. The objective is to maximize sales while minimizing waste, with uncertainty about the actual consumption by costumers. This problem is of a high relevance today, given the growing demand for food and the impact of food waste on the environment, the economy, and purchasing power. We frame inventory restocking as a new reinforcement learning task that exhibits stochastic behavior conditioned on the agent's actions, making the environment partially observable. We introduce a new reinforcement learning environment based on real grocery store data and expert knowledge. This environment is highly stochastic, and presents a unique challenge for reinforcement learning practitioners. We show that uncertainty about the future behavior of the environment is not handled well by classical supply chain algorithms, and that distributional approaches are a good way to account for the uncertainty. We also present GLDQN, a new distributional reinforcement learning algorithm that learns a generalized lambda distribution over the reward space. We show that GLDQN outperforms other distributional reinforcement learning approaches in our partially observable environments, in both overall reward and generated waste.
Teaching Fairness, Accountability, Confidentiality, and Transparency in Artificial Intelligence through the Lens of Reproducibility
Nov 09, 2021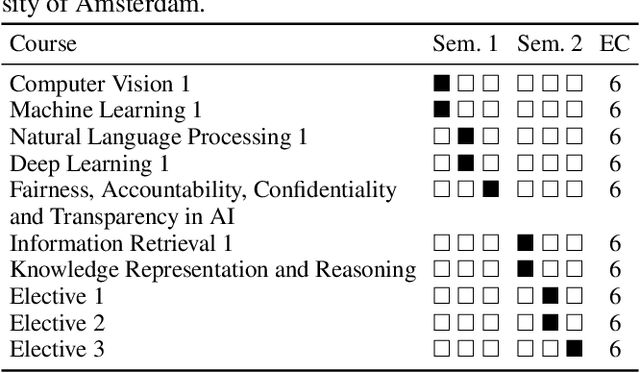
In this work we explain the setup for a technical, graduate-level course on Fairness, Accountability, Confidentiality and Transparency in Artificial Intelligence (FACT-AI) at the University of Amsterdam, which teaches FACT-AI concepts through the lens of reproducibility. The focal point of the course is a group project based on reproducing existing FACT-AI algorithms from top AI conferences, and writing a report about their experiences. In the first iteration of the course, we created an open source repository with the code implementations from the group projects. In the second iteration, we encouraged students to submit their group projects to the Machine Learning Reproducibility Challenge, which resulted in 9 reports from our course being accepted to the challenge. We reflect on our experience teaching the course over two academic years, where one year coincided with a global pandemic, and propose guidelines for teaching FACT-AI through reproducibility in graduate-level AI programs. We hope this can be a useful resource for instructors to set up similar courses at their universities in the future.
A Next Basket Recommendation Reality Check
Sep 29, 2021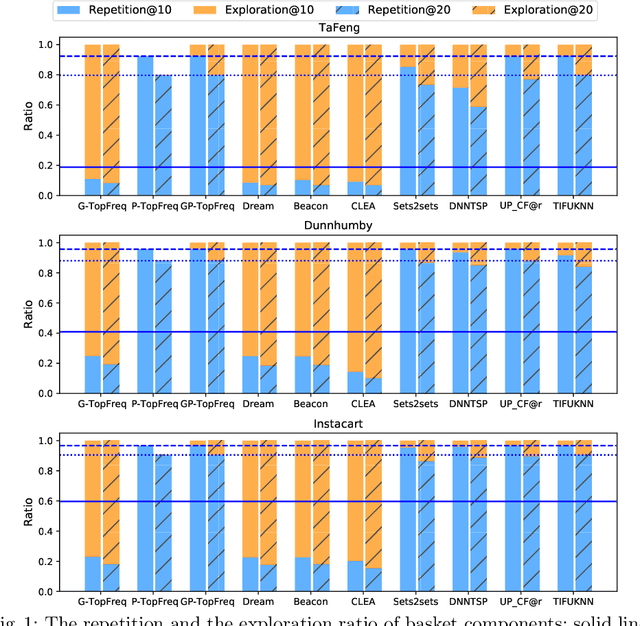
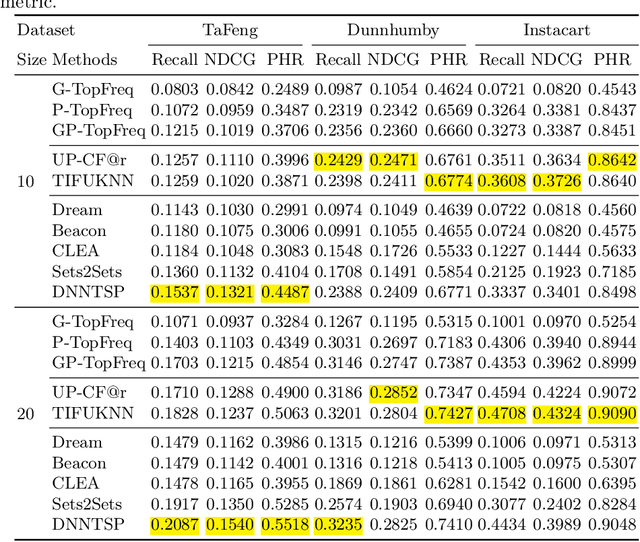
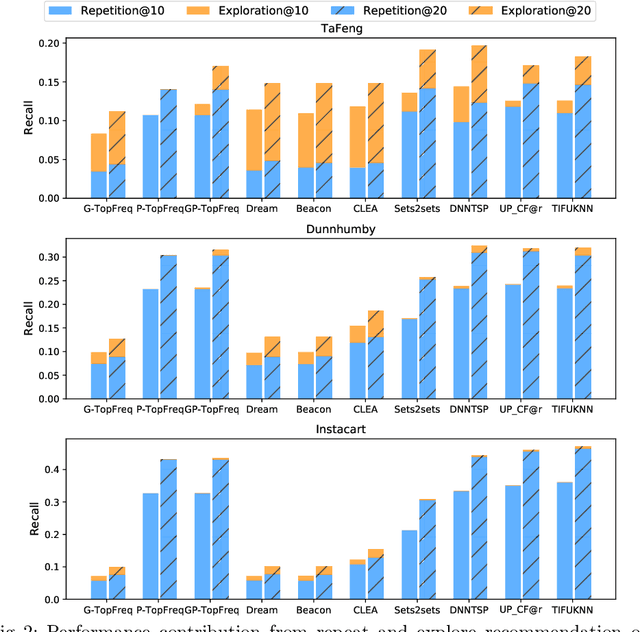
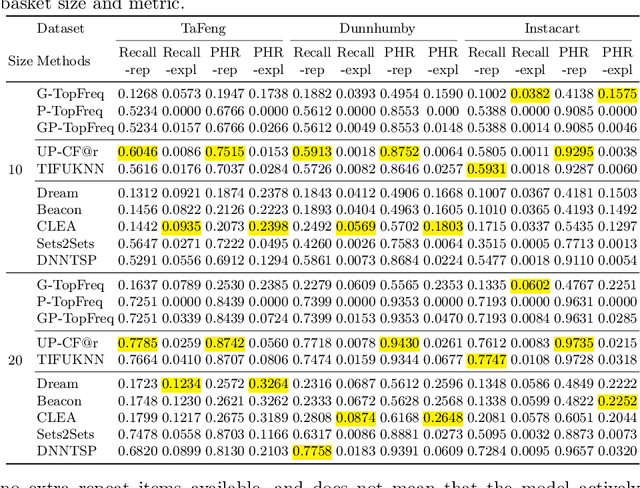
The goal of a next basket recommendation (NBR) system is to recommend items for the next basket for a user, based on the sequence of their prior baskets. Recently, a number of methods with complex modules have been proposed that claim state-of-the-art performance. They rarely look into the predicted basket and just provide intuitive reasons for the observed improvements, e.g., better representation, capturing intentions or relations, etc. We provide a novel angle on the evaluation of next basket recommendation methods, centered on the distinction between repetition and exploration: the next basket is typically composed of previously consumed items (i.e., repeat items) and new items (i.e, explore items). We propose a set of metrics that measure the repeat/explore ratio and performance of NBR models. Using these new metrics, we analyze state-of-the-art NBR models. The results of our analysis help to clarify the extent of the actual progress achieved by existing NBR methods as well as the underlying reasons for the improvements. Overall, our work sheds light on the evaluation problem of NBR and provides useful insights into the model design for this task.