 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating and Reducing Shortcuts in Vision-Language Representation Learning
Feb 27, 2024



Vision-language models (VLMs) mainly rely on contrastive training to learn general-purpose representations of images and captions. We focus on the situation when one image is associated with several captions, each caption containing both information shared among all captions and unique information per caption about the scene depicted in the image. In such cases, it is unclear whether contrastive losses are sufficient for learning task-optimal representations that contain all the information provided by the captions or whether the contrastive learning setup encourages the learning of a simple shortcut that minimizes contrastive loss. We introduce synthetic shortcuts for vision-language: a training and evaluation framework where we inject synthetic shortcuts into image-text data. We show that contrastive VLMs trained from scratch or fine-tuned with data containing these synthetic shortcuts mainly learn features that represent the shortcut. Hence, contrastive losses are not sufficient to learn task-optimal representations, i.e., representations that contain all task-relevant information shared between the image and associated captions. We examine two methods to reduce shortcut learning in our training and evaluation framework: (i) latent target decoding and (ii) implicit feature modification. We show empirically that both methods improve performance on the evaluation task, but only partly reduce shortcut learning when training and evaluating with our shortcut learning framework. Hence, we show the difficulty and challenge of our shortcut learning framework for contrastive vision-language representation learning.
Approximate Nearest Neighbour Phrase Mining for Contextual Speech Recognition
Apr 18, 2023


This paper presents an extension to train end-to-end Context-Aware Transformer Transducer ( CATT ) models by using a simple, yet efficient method of mining hard negative phrases from the latent space of the context encoder. During training, given a reference query, we mine a number of similar phrases using approximate nearest neighbour search. These sampled phrases are then used as negative examples in the context list alongside random and ground truth contextual information. By including approximate nearest neighbour phrases (ANN-P) in the context list, we encourage the learned representation to disambiguate between similar, but not identical, biasing phrases. This improves biasing accuracy when there are several similar phrases in the biasing inventory. We carry out experiments in a large-scale data regime obtaining up to 7% relative word error rate reductions for the contextual portion of test data. We also extend and evaluate CATT approach in streaming applications.
A Song of agreement: Evaluating the Evaluation of Explainable Artificial Intelligence in Natural Language Processing
May 09, 2022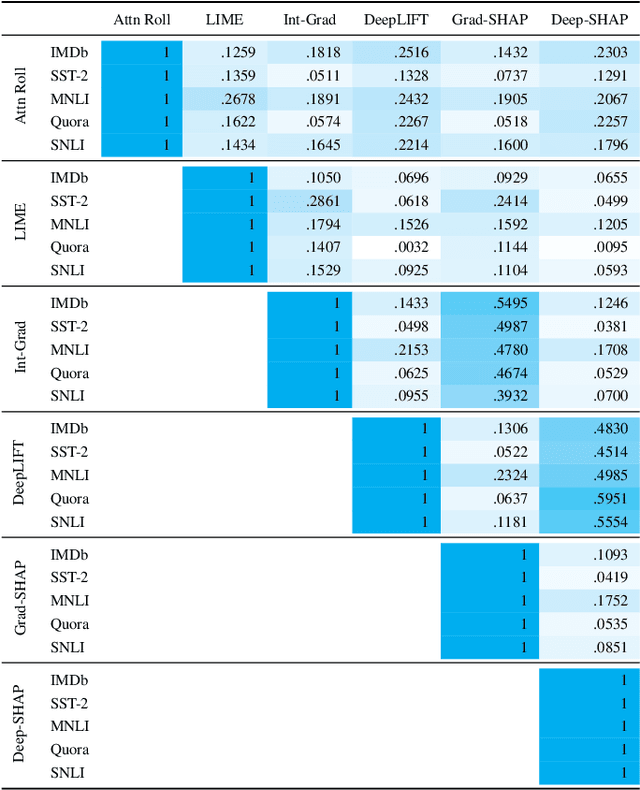

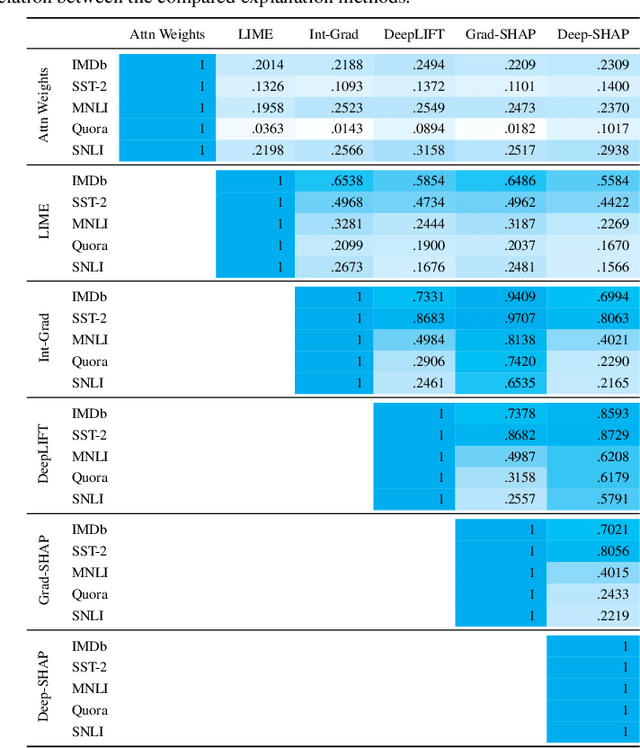
There has been significant debate in the NLP community about whether or not attention weights can be used as an explanation - a mechanism for interpreting how important each input token is for a particular prediction. The validity of "attention as explanation" has so far been evaluated by computing the rank correlation between attention-based explanations and existing feature attribution explanations using LSTM-based models. In our work, we (i) compare the rank correlation between five more recent feature attribution methods and two attention-based methods, on two types of NLP tasks, and (ii) extend this analysis to also include transformer-based models. We find that attention-based explanations do not correlate strongly with any recent feature attribution methods, regardless of the model or task. Furthermore, we find that none of the tested explanations correlate strongly with one another for the transformer-based model, leading us to question the underlying assumption that we should measure the validity of attention-based explanations based on how well they correlate with existing feature attribution explanation methods. After conducting experiments on five datasets using two different models, we argue that the community should stop using rank correlation as an evaluation metric for attention-based explanations. We suggest that researchers and practitioners should instead test various explanation methods and employ a human-in-the-loop process to determine if the explanations align with human intuition for the particular use case at hand.
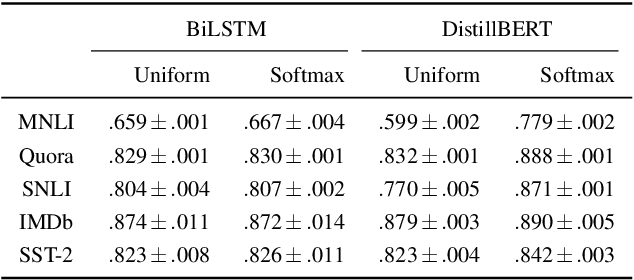
Keep the Caption Information: Preventing Shortcut Learning in Contrastive Image-Caption Retrieval
Apr 28, 2022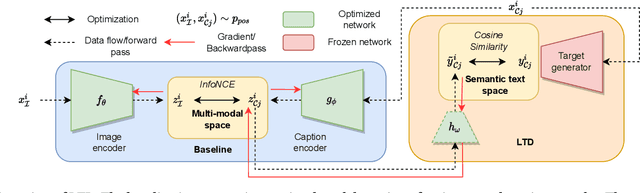
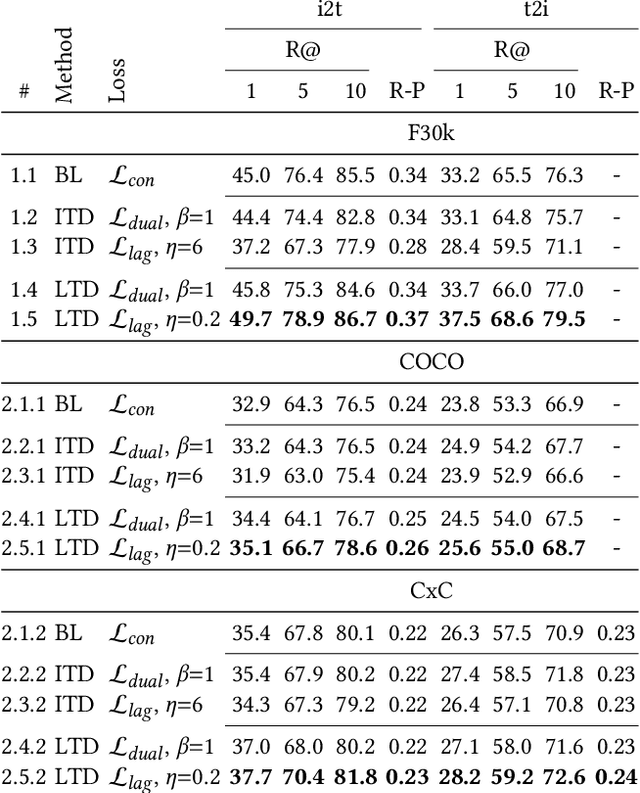
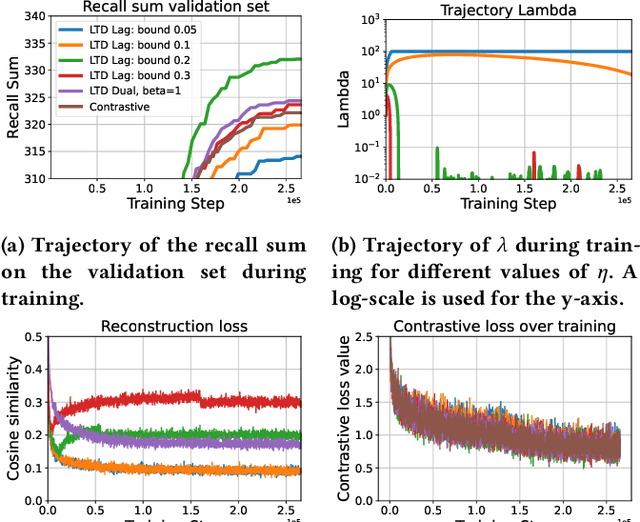
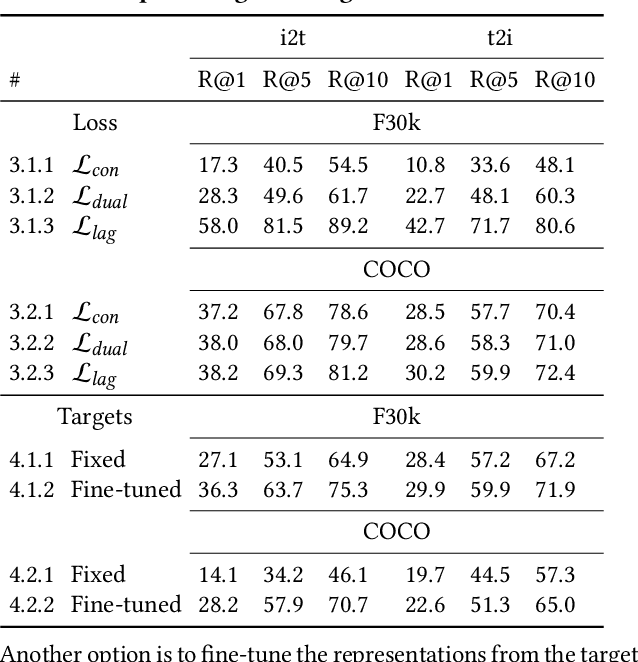
To train image-caption retrieval (ICR) methods, contrastive loss functions are a common choice for optimization functions. Unfortunately, contrastive ICR methods are vulnerable to learning shortcuts: decision rules that perform well on the training data but fail to transfer to other testing conditions. We introduce an approach to reduce shortcut feature representations for the ICR task: latent target decoding (LTD). We add an additional decoder to the learning framework to reconstruct the input caption, which prevents the image and caption encoder from learning shortcut features. Instead of reconstructing input captions in the input space, we decode the semantics of the caption in a latent space. We implement the LTD objective as an optimization constraint, to ensure that the reconstruction loss is below a threshold value while primarily optimizing for the contrastive loss. Importantly, LTD does not depend on additional training data or expensive (hard) negative mining strategies. Our experiments show that, unlike reconstructing the input caption, LTD reduces shortcut learning and improves generalizability by obtaining higher recall@k and r-precision scores. Additionally, we show that the evaluation scores benefit from implementing LTD as an optimization constraint instead of a dual loss.
Do Lessons from Metric Learning Generalize to Image-Caption Retrieval?
Feb 14, 2022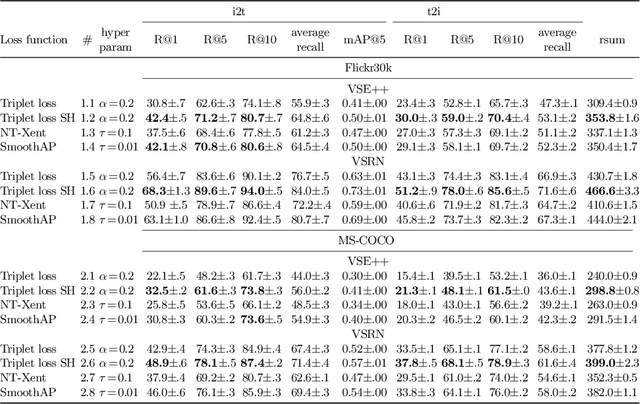
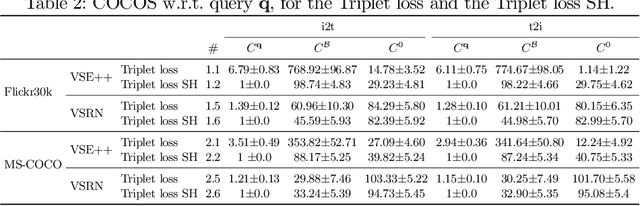
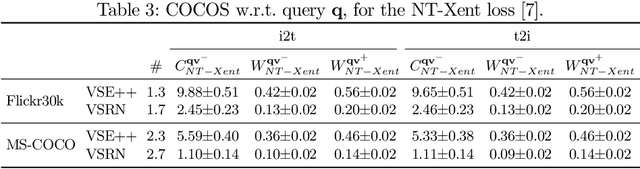

The triplet loss with semi-hard negatives has become the de facto choice for image-caption retrieval (ICR) methods that are optimized from scratch. Recent progress in metric learning has given rise to new loss functions that outperform the triplet loss on tasks such as image retrieval and representation learning. We ask whether these findings generalize to the setting of ICR by comparing three loss functions on two ICR methods. We answer this question negatively: the triplet loss with semi-hard negative mining still outperforms newly introduced loss functions from metric learning on the ICR task. To gain a better understanding of these outcomes, we introduce an analysis method to compare loss functions by counting how many samples contribute to the gradient w.r.t. the query representation during optimization. We find that loss functions that result in lower evaluation scores on the ICR task, in general, take too many (non-informative) samples into account when computing a gradient w.r.t. the query representation, which results in sub-optimal performance. The triplet loss with semi-hard negatives is shown to outperform the other loss functions, as it only takes one (hard) negative into account when computing the gradient.
Extending CLIP for Category-to-image Retrieval in E-commerce
Jan 04, 2022
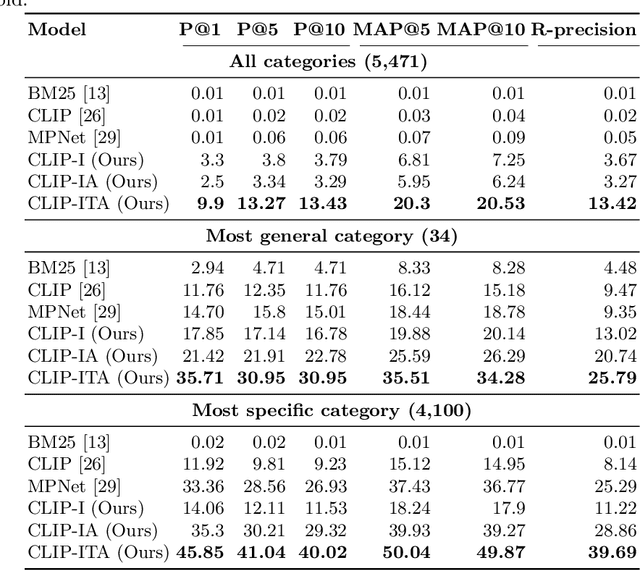
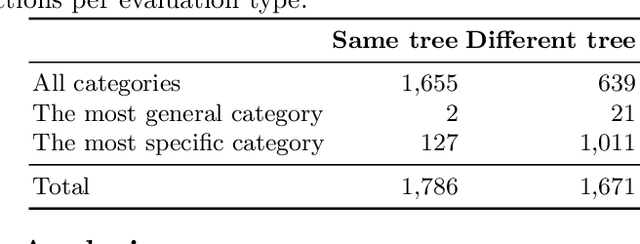
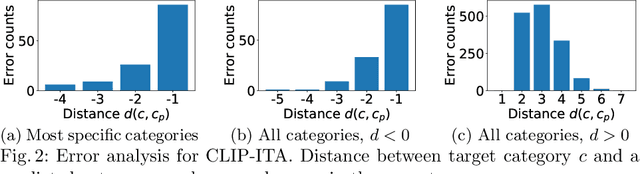
E-commerce provides rich multimodal data that is barely leveraged in practice. One aspect of this data is a category tree that is being used in search and recommendation. However, in practice, during a user's session there is often a mismatch between a textual and a visual representation of a given category. Motivated by the problem, we introduce the task of category-to-image retrieval in e-commerce and propose a model for the task, CLIP-ITA. The model leverages information from multiple modalities (textual, visual, and attribute modality) to create product representations. We explore how adding information from multiple modalities (textual, visual, and attribute modality) impacts the model's performance. In particular, we observe that CLIP-ITA significantly outperforms a comparable model that leverages only the visual modality and a comparable model that leverages the visual and attribute modality.
Teaching Fairness, Accountability, Confidentiality, and Transparency in Artificial Intelligence through the Lens of Reproducibility
Nov 09, 2021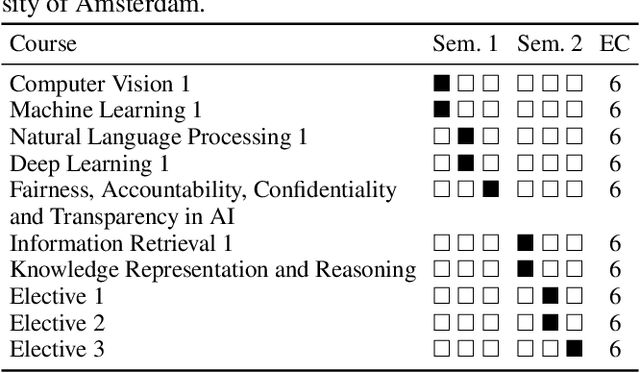
In this work we explain the setup for a technical, graduate-level course on Fairness, Accountability, Confidentiality and Transparency in Artificial Intelligence (FACT-AI) at the University of Amsterdam, which teaches FACT-AI concepts through the lens of reproducibility. The focal point of the course is a group project based on reproducing existing FACT-AI algorithms from top AI conferences, and writing a report about their experiences. In the first iteration of the course, we created an open source repository with the code implementations from the group projects. In the second iteration, we encouraged students to submit their group projects to the Machine Learning Reproducibility Challenge, which resulted in 9 reports from our course being accepted to the challenge. We reflect on our experience teaching the course over two academic years, where one year coincided with a global pandemic, and propose guidelines for teaching FACT-AI through reproducibility in graduate-level AI programs. We hope this can be a useful resource for instructors to set up similar courses at their universities in the future.
Conditional Image Generation and Manipulation for User-Specified Content
May 11, 2020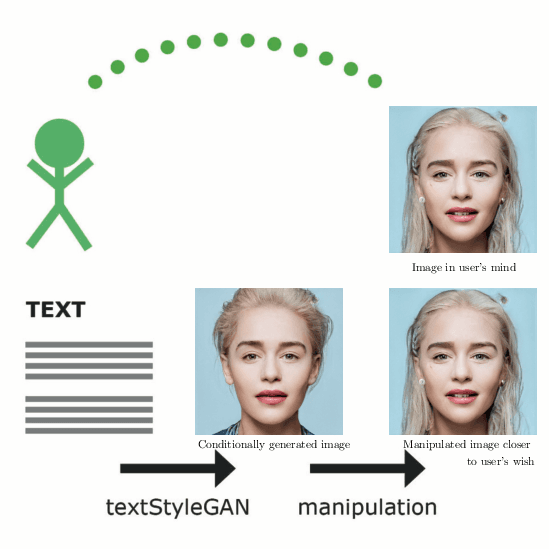
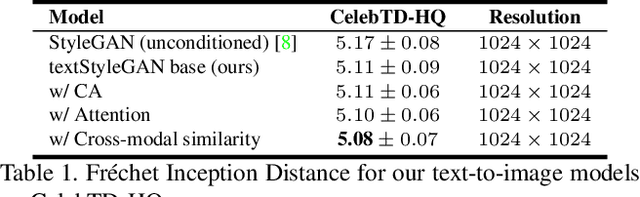
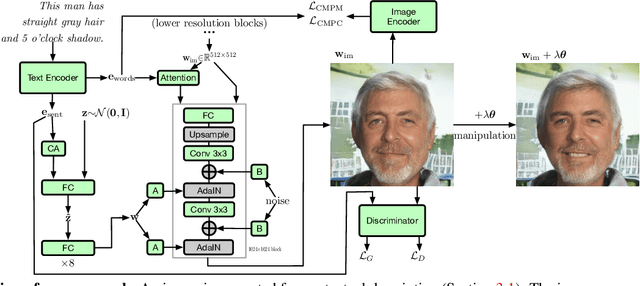
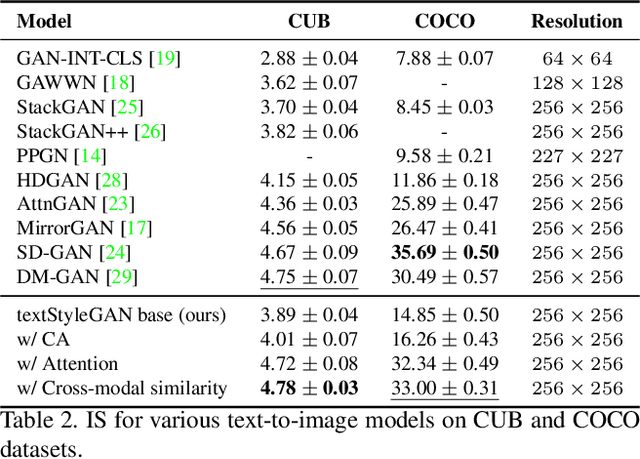
In recent years, Generative Adversarial Networks (GANs) have improved steadily towards generating increasingly impressive real-world images. It is useful to steer the image generation process for purposes such as content creation. This can be done by conditioning the model on additional information. However, when conditioning on additional information, there still exists a large set of images that agree with a particular conditioning. This makes it unlikely that the generated image is exactly as envisioned by a user, which is problematic for practical content creation scenarios such as generating facial composites or stock photos. To solve this problem, we propose a single pipeline for text-to-image generation and manipulation. In the first part of our pipeline we introduce textStyleGAN, a model that is conditioned on text. In the second part of our pipeline we make use of the pre-trained weights of textStyleGAN to perform semantic facial image manipulation. The approach works by finding semantic directions in latent space. We show that this method can be used to manipulate facial images for a wide range of attributes. Finally, we introduce the CelebTD-HQ dataset, an extension to CelebA-HQ, consisting of faces and corresponding textual descriptions.
Bidirectional Scene Text Recognition with a Single Decoder
Dec 08, 2019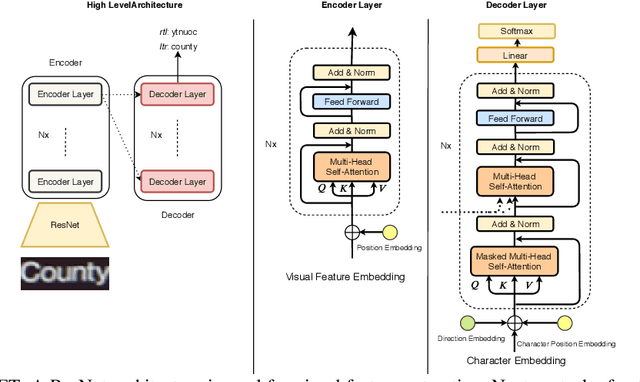
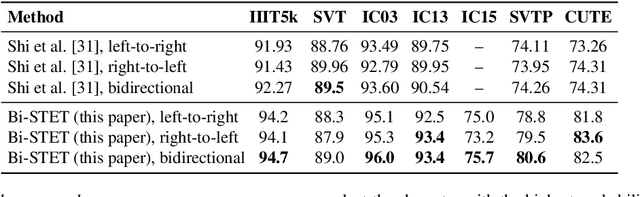
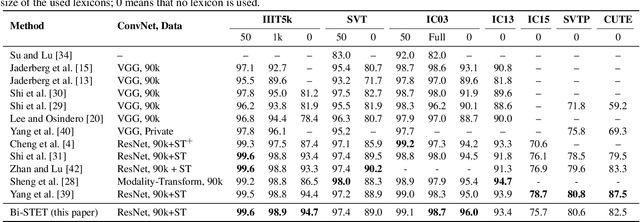

Scene Text Recognition (STR) is the problem of recognizing the correct word or character sequence in a cropped word image. To obtain more robust output sequences, the notion of bidirectional STR has been introduced. So far, bidirectional STRs have been implemented by using two separate decoders; one for left-to-right decoding and one for right-to-left. Having two separate decoders for almost the same task with the same output space is undesirable from a computational and optimization point of view. We introduce the bidirectional Scene Text Transformer (Bi-STET), a novel bidirectional STR method with a single decoder for bidirectional text decoding. With its single decoder, Bi-STET outperforms methods that apply bidirectional decoding by using two separate decoders while also being more efficient than those methods, Furthermore, we achieve or beat state-of-the-art (SOTA) methods on all STR benchmarks with Bi-STET. Finally, we provide analyses and insights into the performance of Bi-STET.