 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Assessing Brittleness of Image-Text Retrieval Benchmarks from Vision-Language Models Perspective
Jul 25, 2024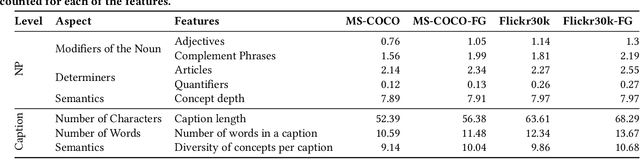
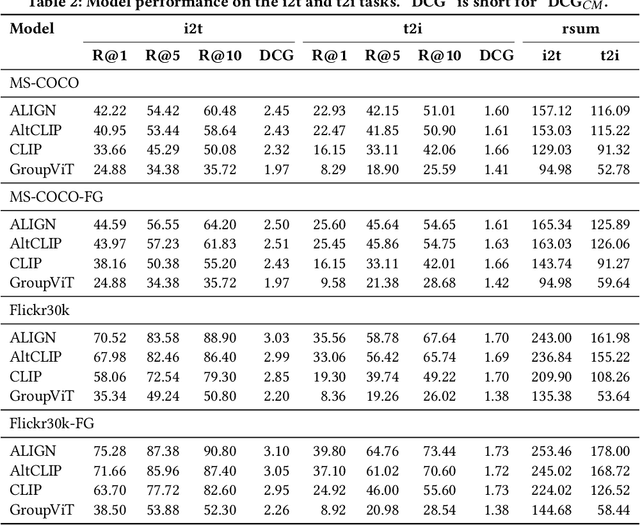
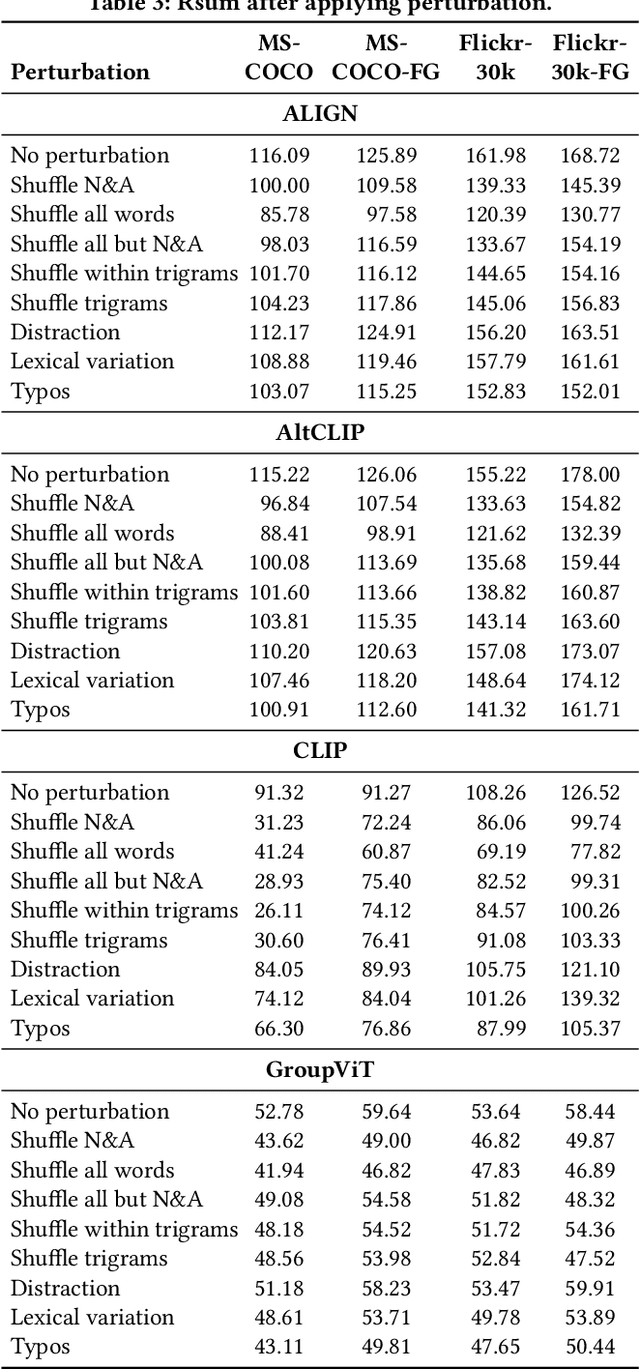

Image-text retrieval (ITR), an important task in information retrieval (IR), is driven by pretrained vision-language models (VLMs) that consistently achieve state-of-the-art performance. However, a significant challenge lies in the brittleness of existing ITR benchmarks. In standard datasets for the task, captions often provide broad summaries of scenes, neglecting detailed information about specific concepts. Additionally, the current evaluation setup assumes simplistic binary matches between images and texts and focuses on intra-modality rather than cross-modal relationships, which can lead to misinterpretations of model performance. Motivated by this gap, in this study, we focus on examining the brittleness of the ITR evaluation pipeline with a focus on concept granularity. We start by analyzing two common benchmarks, MS-COCO and Flickr30k, and compare them with their augmented versions, MS-COCO-FG and Flickr30k-FG, given a specified set of linguistic features capturing concept granularity. We discover that Flickr30k-FG and MS COCO-FG consistently achieve higher scores across all the selected features. To investigate the performance of VLMs on coarse and fine-grained datasets, we introduce a taxonomy of perturbations. We apply these perturbations to the selected datasets. We evaluate four state-of-the-art models - ALIGN, AltCLIP, CLIP, and GroupViT - on the standard and fine-grained datasets under zero-shot conditions, with and without the applied perturbations. The results demonstrate that although perturbations generally degrade model performance, the fine-grained datasets exhibit a smaller performance drop than their standard counterparts. Moreover, the relative performance drop across all setups is consistent across all models and datasets, indicating that the issue lies within the benchmarks. We conclude the paper by providing an agenda for improving ITR evaluation pipelines.
Multimodal Learned Sparse Retrieval with Probabilistic Expansion Control
Feb 27, 2024Learned sparse retrieval (LSR) is a family of neural methods that encode queries and documents into sparse lexical vectors that can be indexed and retrieved efficiently with an inverted index. We explore the application of LSR to the multi-modal domain, with a focus on text-image retrieval. While LSR has seen success in text retrieval, its application in multimodal retrieval remains underexplored. Current approaches like LexLIP and STAIR require complex multi-step training on massive datasets. Our proposed approach efficiently transforms dense vectors from a frozen dense model into sparse lexical vectors. We address issues of high dimension co-activation and semantic deviation through a new training algorithm, using Bernoulli random variables to control query expansion. Experiments with two dense models (BLIP, ALBEF) and two datasets (MSCOCO, Flickr30k) show that our proposed algorithm effectively reduces co-activation and semantic deviation. Our best-performing sparsified model outperforms state-of-the-art text-image LSR models with a shorter training time and lower GPU memory requirements. Our approach offers an effective solution for training LSR retrieval models in multimodal settings. Our code and model checkpoints are available at github.com/thongnt99/lsr-multimodal
Demonstrating and Reducing Shortcuts in Vision-Language Representation Learning
Feb 27, 2024



Vision-language models (VLMs) mainly rely on contrastive training to learn general-purpose representations of images and captions. We focus on the situation when one image is associated with several captions, each caption containing both information shared among all captions and unique information per caption about the scene depicted in the image. In such cases, it is unclear whether contrastive losses are sufficient for learning task-optimal representations that contain all the information provided by the captions or whether the contrastive learning setup encourages the learning of a simple shortcut that minimizes contrastive loss. We introduce synthetic shortcuts for vision-language: a training and evaluation framework where we inject synthetic shortcuts into image-text data. We show that contrastive VLMs trained from scratch or fine-tuned with data containing these synthetic shortcuts mainly learn features that represent the shortcut. Hence, contrastive losses are not sufficient to learn task-optimal representations, i.e., representations that contain all task-relevant information shared between the image and associated captions. We examine two methods to reduce shortcut learning in our training and evaluation framework: (i) latent target decoding and (ii) implicit feature modification. We show empirically that both methods improve performance on the evaluation task, but only partly reduce shortcut learning when training and evaluating with our shortcut learning framework. Hence, we show the difficulty and challenge of our shortcut learning framework for contrastive vision-language representation learning.
Multimodal Learned Sparse Retrieval for Image Suggestion
Feb 12, 2024Learned Sparse Retrieval (LSR) is a group of neural methods designed to encode queries and documents into sparse lexical vectors. These vectors can be efficiently indexed and retrieved using an inverted index. While LSR has shown promise in text retrieval, its potential in multi-modal retrieval remains largely unexplored. Motivated by this, in this work, we explore the application of LSR in the multi-modal domain, i.e., we focus on Multi-Modal Learned Sparse Retrieval (MLSR). We conduct experiments using several MLSR model configurations and evaluate the performance on the image suggestion task. We find that solving the task solely based on the image content is challenging. Enriching the image content with its caption improves the model performance significantly, implying the importance of image captions to provide fine-grained concepts and context information of images. Our approach presents a practical and effective solution for training LSR retrieval models in multi-modal settings.
Towards Contrastive Learning in Music Video Domain
Sep 01, 2023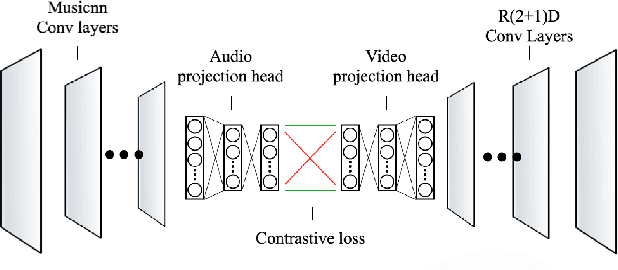

Contrastive learning is a powerful way of learning multimodal representations across various domains such as image-caption retrieval and audio-visual representation learning. In this work, we investigate if these findings generalize to the domain of music videos. Specifically, we create a dual en-coder for the audio and video modalities and train it using a bidirectional contrastive loss. For the experiments, we use an industry dataset containing 550 000 music videos as well as the public Million Song Dataset, and evaluate the quality of learned representations on the downstream tasks of music tagging and genre classification. Our results indicate that pre-trained networks without contrastive fine-tuning outperform our contrastive learning approach when evaluated on both tasks. To gain a better understanding of the reasons contrastive learning was not successful for music videos, we perform a qualitative analysis of the learned representations, revealing why contrastive learning might have difficulties uniting embeddings from two modalities. Based on these findings, we outline possible directions for future work. To facilitate the reproducibility of our results, we share our code and the pre-trained model.
Scene-centric vs. Object-centric Image-Text Cross-modal Retrieval: A Reproducibility Study
Jan 12, 2023Most approaches to cross-modal retrieval (CMR) focus either on object-centric datasets, meaning that each document depicts or describes a single object, or on scene-centric datasets, meaning that each image depicts or describes a complex scene that involves multiple objects and relations between them. We posit that a robust CMR model should generalize well across both dataset types. Despite recent advances in CMR, the reproducibility of the results and their generalizability across different dataset types has not been studied before. We address this gap and focus on the reproducibility of the state-of-the-art CMR results when evaluated on object-centric and scene-centric datasets. We select two state-of-the-art CMR models with different architectures: (i) CLIP; and (ii) X-VLM. Additionally, we select two scene-centric datasets, and three object-centric datasets, and determine the relative performance of the selected models on these datasets. We focus on reproducibility, replicability, and generalizability of the outcomes of previously published CMR experiments. We discover that the experiments are not fully reproducible and replicable. Besides, the relative performance results partially generalize across object-centric and scene-centric datasets. On top of that, the scores obtained on object-centric datasets are much lower than the scores obtained on scene-centric datasets. For reproducibility and transparency we make our source code and the trained models publicly available.
Unimodal vs. Multimodal Siamese Networks for Outfit Completion
Jul 21, 2022

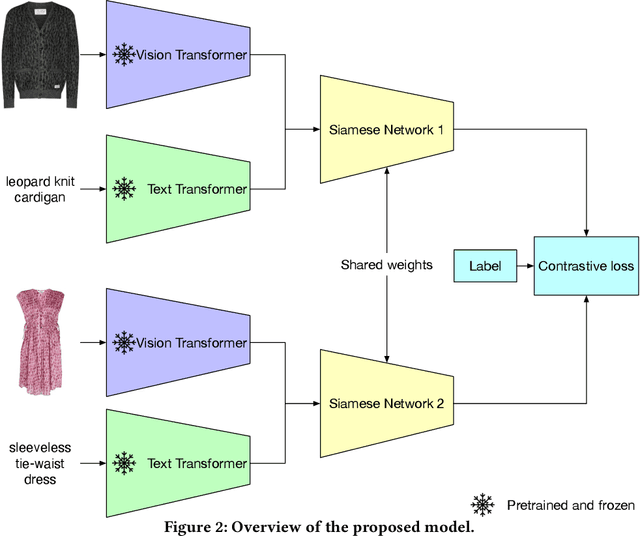
The popularity of online fashion shopping continues to grow. The ability to offer an effective recommendation to customers is becoming increasingly important. In this work, we focus on Fashion Outfits Challenge, part of SIGIR 2022 Workshop on eCommerce. The challenge is centered around Fill in the Blank (FITB) task that implies predicting the missing outfit, given an incomplete outfit and a list of candidates. In this paper, we focus on applying siamese networks on the task. More specifically, we explore how combining information from multiple modalities (textual and visual modality) impacts the performance of the model on the task. We evaluate our model on the test split provided by the challenge organizers and the test split with gold assignments that we created during the development phase. We discover that using both visual, and visual and textual data demonstrates promising results on the task. We conclude by suggesting directions for further improvement of our method.
Extending CLIP for Category-to-image Retrieval in E-commerce
Jan 04, 2022
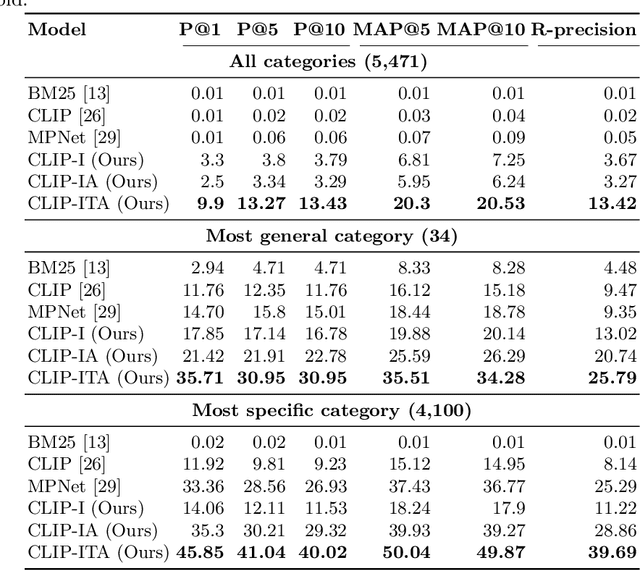
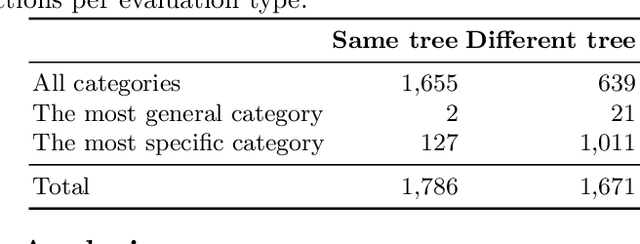
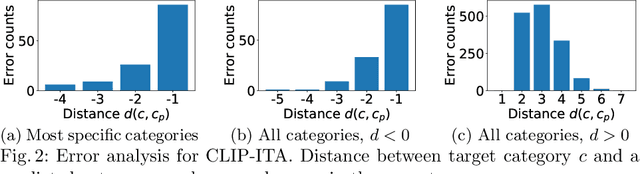
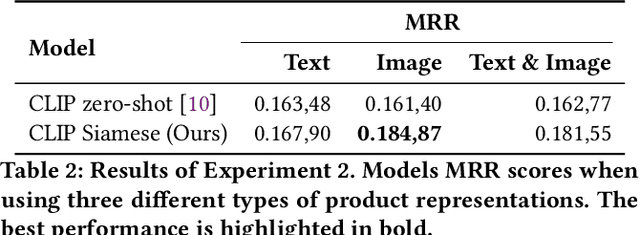
E-commerce provides rich multimodal data that is barely leveraged in practice. One aspect of this data is a category tree that is being used in search and recommendation. However, in practice, during a user's session there is often a mismatch between a textual and a visual representation of a given category. Motivated by the problem, we introduce the task of category-to-image retrieval in e-commerce and propose a model for the task, CLIP-ITA. The model leverages information from multiple modalities (textual, visual, and attribute modality) to create product representations. We explore how adding information from multiple modalities (textual, visual, and attribute modality) impacts the model's performance. In particular, we observe that CLIP-ITA significantly outperforms a comparable model that leverages only the visual modality and a comparable model that leverages the visual and attribute modality.