 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnimodal vs. Multimodal Siamese Networks for Outfit Completion
Paper and Code


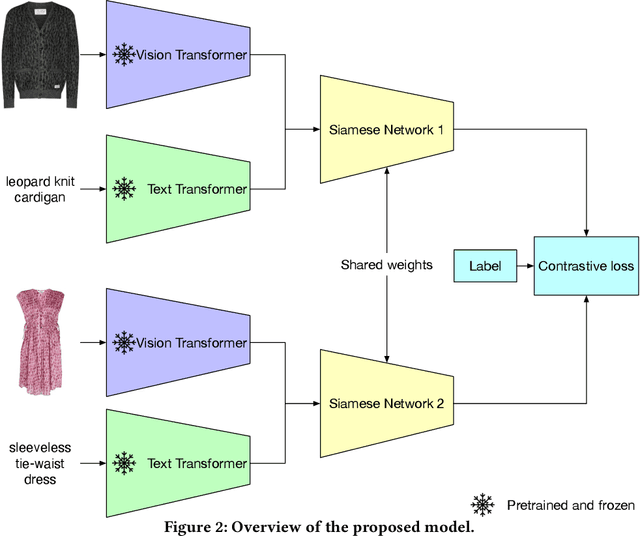
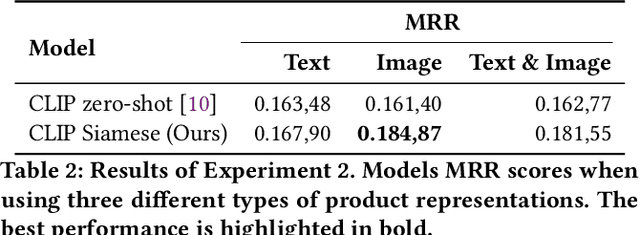
The popularity of online fashion shopping continues to grow. The ability to offer an effective recommendation to customers is becoming increasingly important. In this work, we focus on Fashion Outfits Challenge, part of SIGIR 2022 Workshop on eCommerce. The challenge is centered around Fill in the Blank (FITB) task that implies predicting the missing outfit, given an incomplete outfit and a list of candidates. In this paper, we focus on applying siamese networks on the task. More specifically, we explore how combining information from multiple modalities (textual and visual modality) impacts the performance of the model on the task. We evaluate our model on the test split provided by the challenge organizers and the test split with gold assignments that we created during the development phase. We discover that using both visual, and visual and textual data demonstrates promising results on the task. We conclude by suggesting directions for further improvement of our method.