 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Contrastive Learning in Music Video Domain
Sep 01, 2023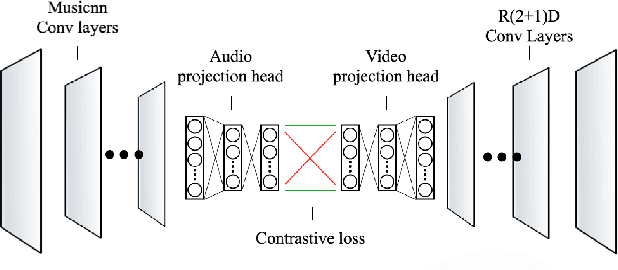
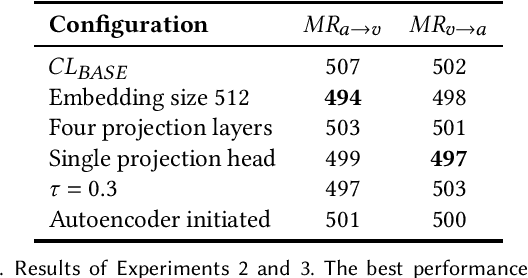

Contrastive learning is a powerful way of learning multimodal representations across various domains such as image-caption retrieval and audio-visual representation learning. In this work, we investigate if these findings generalize to the domain of music videos. Specifically, we create a dual en-coder for the audio and video modalities and train it using a bidirectional contrastive loss. For the experiments, we use an industry dataset containing 550 000 music videos as well as the public Million Song Dataset, and evaluate the quality of learned representations on the downstream tasks of music tagging and genre classification. Our results indicate that pre-trained networks without contrastive fine-tuning outperform our contrastive learning approach when evaluated on both tasks. To gain a better understanding of the reasons contrastive learning was not successful for music videos, we perform a qualitative analysis of the learned representations, revealing why contrastive learning might have difficulties uniting embeddings from two modalities. Based on these findings, we outline possible directions for future work. To facilitate the reproducibility of our results, we share our code and the pre-trained model.