 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Contrastive Learning in Music Video Domain
Sep 01, 2023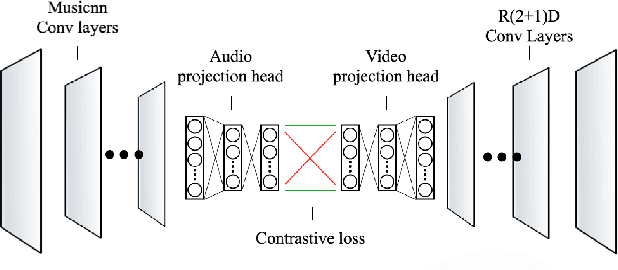
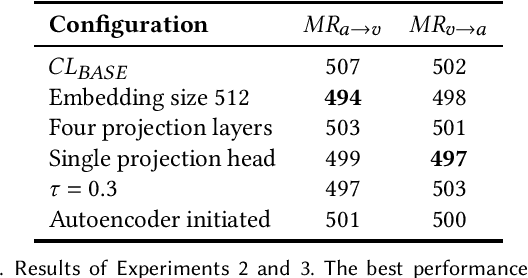

Contrastive learning is a powerful way of learning multimodal representations across various domains such as image-caption retrieval and audio-visual representation learning. In this work, we investigate if these findings generalize to the domain of music videos. Specifically, we create a dual en-coder for the audio and video modalities and train it using a bidirectional contrastive loss. For the experiments, we use an industry dataset containing 550 000 music videos as well as the public Million Song Dataset, and evaluate the quality of learned representations on the downstream tasks of music tagging and genre classification. Our results indicate that pre-trained networks without contrastive fine-tuning outperform our contrastive learning approach when evaluated on both tasks. To gain a better understanding of the reasons contrastive learning was not successful for music videos, we perform a qualitative analysis of the learned representations, revealing why contrastive learning might have difficulties uniting embeddings from two modalities. Based on these findings, we outline possible directions for future work. To facilitate the reproducibility of our results, we share our code and the pre-trained model.
Local Explanations for Clinical Search Engine results
Oct 19, 2021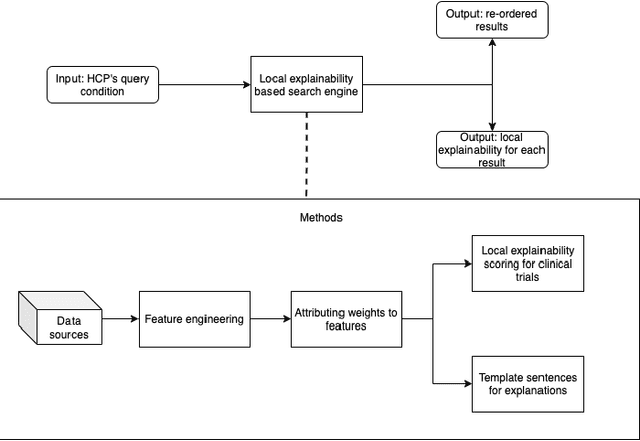
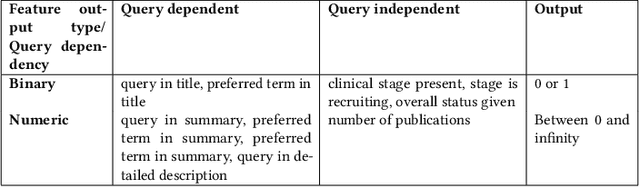
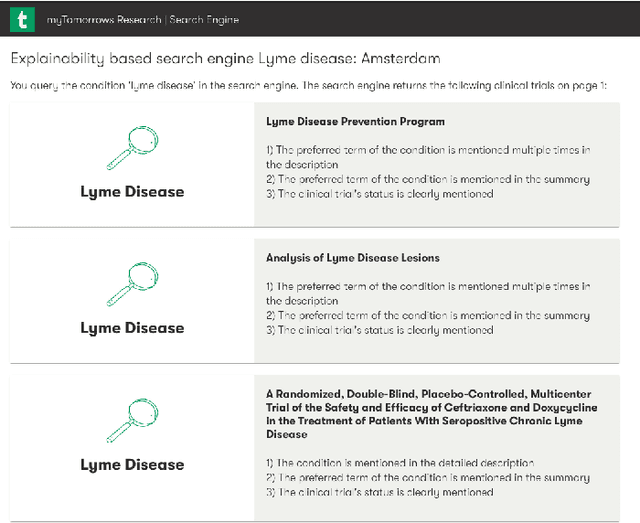
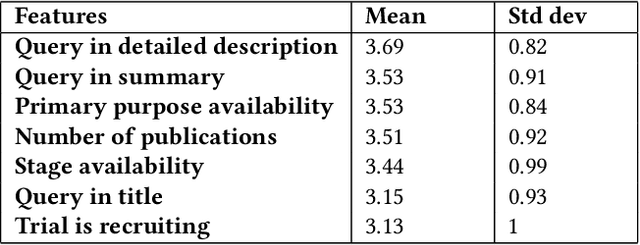
Health care professionals rely on treatment search engines to efficiently find adequate clinical trials and early access programs for their patients. However, doctors lose trust in the system if its underlying processes are unclear and unexplained. In this paper, a model-agnostic explainable method is developed to provide users with further information regarding the reasons why a clinical trial is retrieved in response to a query. To accomplish this, the engine generates features from clinical trials using by using a knowledge graph, clinical trial data and additional medical resources. and a crowd-sourcing methodology is used to determine their importance. Grounded on the proposed methodology, the rationale behind retrieving the clinical trials is explained in layman's terms so that healthcare processionals can effortlessly perceive them. In addition, we compute an explainability score for each of the retrieved items, according to which the items can be ranked. The experiments validated by medical professionals suggest that the proposed methodology induces trust in targeted as well as in non-targeted users, and provide them with reliable explanations and ranking of retrieved items.
Active Learning from Crowd in Document Screening
Nov 11, 2020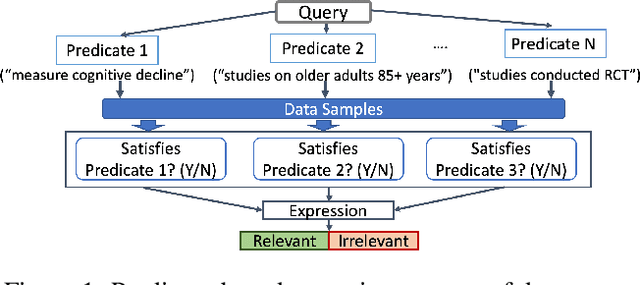

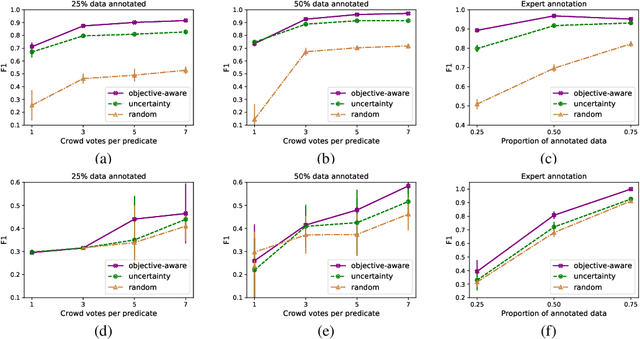
In this paper, we explore how to efficiently combine crowdsourcing and machine intelligence for the problem of document screening, where we need to screen documents with a set of machine-learning filters. Specifically, we focus on building a set of machine learning classifiers that evaluate documents, and then screen them efficiently. It is a challenging task since the budget is limited and there are countless number of ways to spend the given budget on the problem. We propose a multi-label active learning screening specific sampling technique -- objective-aware sampling -- for querying unlabelled documents for annotating. Our algorithm takes a decision on which machine filter need more training data and how to choose unlabeled items to annotate in order to minimize the risk of overall classification errors rather than minimizing a single filter error. We demonstrate that objective-aware sampling significantly outperforms the state of the art active learning sampling strategies.