 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadraSHAP: Stable and Scalable Shapley Values for Product Games via Gauss-Legendre Quadrature
May 07, 2026We study the efficient computation of Shapley values for \emph{product games} -- cooperative games in which the coalition value factorizes as a product of per-player terms. Such games arise in machine learning explainability whenever the value function inherits a multiplicative structure from the underlying model, as in kernel methods with product kernels and tree-based models. Our key result is that the Shapley value of each player in a product game admits an exact one-dimensional integral representation: the weighted sum over exponentially many feature coalitions collapses to the integral of a degree-$(d-1)$ polynomial over $[0,1]$, where $d$ is the total number of features. This yields a Gauss--Legendre quadrature scheme that is \emph{provably exact} whenever the number of nodes satisfies $m_q \geq \lceil d/2 \rceil$, and otherwise provides a \emph{near-exact} approximation with error provably decaying geometrically in $m_q$. In practice, a few hundred nodes can achieve highly precise estimates even with thousands of features. Building on this formulation, we derive a numerically stable implementation via log-space evaluation, together with an efficient parallel implementation based on associative scan primitives that achieves $O(d\,m_q)$ total work and $O(\log d)$ parallel time. Experiments show that \textsc{QuadraSHAP} is the fastest numerically stable method across all tested configurations.
Exact Shapley Attributions in Quadratic-time for FANOVA Gaussian Processes
Aug 20, 2025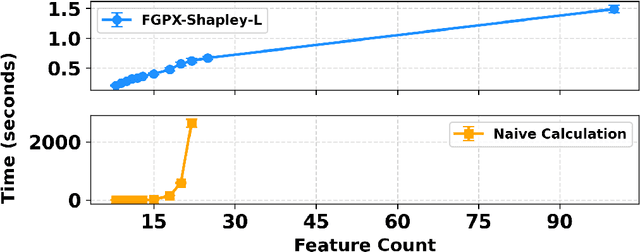



Shapley values are widely recognized as a principled method for attributing importance to input features in machine learning. However, the exact computation of Shapley values scales exponentially with the number of features, severely limiting the practical application of this powerful approach. The challenge is further compounded when the predictive model is probabilistic - as in Gaussian processes (GPs) - where the outputs are random variables rather than point estimates, necessitating additional computational effort in modeling higher-order moments. In this work, we demonstrate that for an important class of GPs known as FANOVA GP, which explicitly models all main effects and interactions, *exact* Shapley attributions for both local and global explanations can be computed in *quadratic time*. For local, instance-wise explanations, we define a stochastic cooperative game over function components and compute the exact stochastic Shapley value in quadratic time only, capturing both the expected contribution and uncertainty. For global explanations, we introduce a deterministic, variance-based value function and compute exact Shapley values that quantify each feature's contribution to the model's overall sensitivity. Our methods leverage a closed-form (stochastic) M\"{o}bius representation of the FANOVA decomposition and introduce recursive algorithms, inspired by Newton's identities, to efficiently compute the mean and variance of Shapley values. Our work enhances the utility of explainable AI, as demonstrated by empirical studies, by providing more scalable, axiomatically sound, and uncertainty-aware explanations for predictions generated by structured probabilistic models.
Computing Exact Shapley Values in Polynomial Time for Product-Kernel Methods
May 22, 2025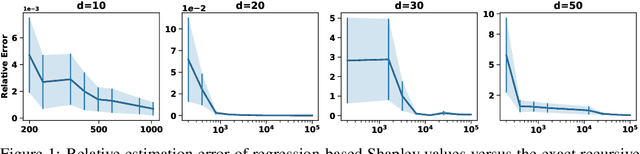
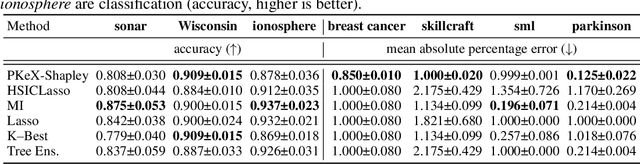
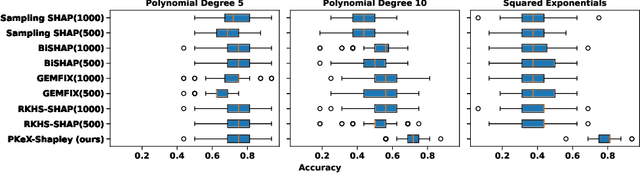
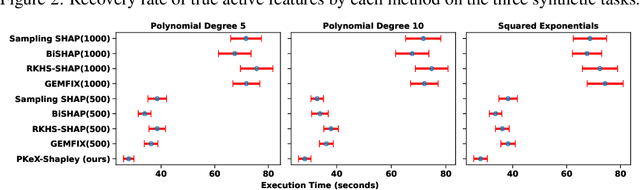
Kernel methods are widely used in machine learning due to their flexibility and expressive power. However, their black-box nature poses significant challenges to interpretability, limiting their adoption in high-stakes applications. Shapley value-based feature attribution techniques, such as SHAP and kernel-specific variants like RKHS-SHAP, offer a promising path toward explainability. Yet, computing exact Shapley values remains computationally intractable in general, motivating the development of various approximation schemes. In this work, we introduce PKeX-Shapley, a novel algorithm that utilizes the multiplicative structure of product kernels to enable the exact computation of Shapley values in polynomial time. We show that product-kernel models admit a functional decomposition that allows for a recursive formulation of Shapley values. This decomposition not only yields computational efficiency but also enhances interpretability in kernel-based learning. We also demonstrate how our framework can be generalized to explain kernel-based statistical discrepancies such as the Maximum Mean Discrepancy (MMD) and the Hilbert-Schmidt Independence Criterion (HSIC), thus offering new tools for interpretable statistical inference.
Recursive Self-Similarity in Deep Weight Spaces of Neural Architectures: A Fractal and Coarse Geometry Perspective
Mar 18, 2025

This paper conceptualizes the Deep Weight Spaces (DWS) of neural architectures as hierarchical, fractal-like, coarse geometric structures observable at discrete integer scales through recursive dilation. We introduce a coarse group action termed the fractal transformation, $T_{r_k} $, acting under the symmetry group $G = (\mathbb{Z}, +) $, to analyze neural parameter matrices or tensors, by segmenting the underlying discrete grid $\Omega$ into $N(r_k)$ fractals across varying observation scales $ r_k $. This perspective adopts a box count technique, commonly used to assess the hierarchical and scale-related geometry of physical structures, which has been extensively formalized under the topic of fractal geometry. We assess the structural complexity of neural layers by estimating the Hausdorff-Besicovitch dimension of their layers and evaluating a degree of self-similarity. The fractal transformation features key algebraic properties such as linearity, identity, and asymptotic invertibility, which is a signature of coarse structures. We show that the coarse group action exhibits a set of symmetries such as Discrete Scale Invariance (DSI) under recursive dilation, strong invariance followed by weak equivariance to permutations, alongside respecting the scaling equivariance of activation functions, defined by the intertwiner group relations. Our framework targets large-scale structural properties of DWS, deliberately overlooking minor inconsistencies to focus on significant geometric characteristics of neural networks. Experiments on CIFAR-10 using ResNet-18, VGG-16, and a custom CNN validate our approach, demonstrating effective fractal segmentation and structural analysis.
CAGE: Causality-Aware Shapley Value for Global Explanations
Apr 17, 2024



As Artificial Intelligence (AI) is having more influence on our everyday lives, it becomes important that AI-based decisions are transparent and explainable. As a consequence, the field of eXplainable AI (or XAI) has become popular in recent years. One way to explain AI models is to elucidate the predictive importance of the input features for the AI model in general, also referred to as global explanations. Inspired by cooperative game theory, Shapley values offer a convenient way for quantifying the feature importance as explanations. However many methods based on Shapley values are built on the assumption of feature independence and often overlook causal relations of the features which could impact their importance for the ML model. Inspired by studies of explanations at the local level, we propose CAGE (Causally-Aware Shapley Values for Global Explanations). In particular, we introduce a novel sampling procedure for out-coalition features that respects the causal relations of the input features. We derive a practical approach that incorporates causal knowledge into global explanation and offers the possibility to interpret the predictive feature importance considering their causal relation. We evaluate our method on synthetic data and real-world data. The explanations from our approach suggest that they are not only more intuitive but also more faithful compared to previous global explanation methods.
Unveiling and unraveling aggregation and dispersion fallacies in group MCDM
Apr 18, 2023Priorities in multi-criteria decision-making (MCDM) convey the relevance preference of one criterion over another, which is usually reflected by imposing the non-negativity and unit-sum constraints. The processing of such priorities is different than other unconstrained data, but this point is often neglected by researchers, which results in fallacious statistical analysis. This article studies three prevalent fallacies in group MCDM along with solutions based on compositional data analysis to avoid misusing statistical operations. First, we use a compositional approach to aggregate the priorities of a group of DMs and show that the outcome of the compositional analysis is identical to the normalized geometric mean, meaning that the arithmetic mean should be avoided. Furthermore, a new aggregation method is developed, which is a robust surrogate for the geometric mean. We also discuss the errors in computing measures of dispersion, including standard deviation and distance functions. Discussing the fallacies in computing the standard deviation, we provide a probabilistic criteria ranking by developing proper Bayesian tests, where we calculate the extent to which a criterion is more important than another. Finally, we explain the errors in computing the distance between priorities, and a clustering algorithm is specially tailored based on proper distance metrics.
Unified Bayesian Frameworks for Multi-criteria Decision-making
Aug 29, 2022


This paper presents a Bayesian framework predicated on a probabilistic interpretation of the MCDM problems and encompasses several well-known multi-criteria decision-making (MCDM) methods. Owing to the flexibility of Bayesian models, the proposed framework can address several long-standing, fundamental challenges in MCDM, including group decision-making problems and criteria correlation, in a statistically elegant way. Also, the model can accommodate different forms of uncertainty in the preferences of the decision makers (DMs), such as normal and triangular distributions and interval preferences. Further, a probabilistic mixture model is developed that can group the DMs into several exhaustive classes. A probabilistic ranking scheme is also designed for both criteria and alternatives, where it identifies the extent to which one criterion/alternative is more important than another based on the DM(s) preferences. The experiments validate the outcome of the proposed framework on several numerical examples and highlight its salient features compared to other methods.
Local Explanations for Clinical Search Engine results
Oct 19, 2021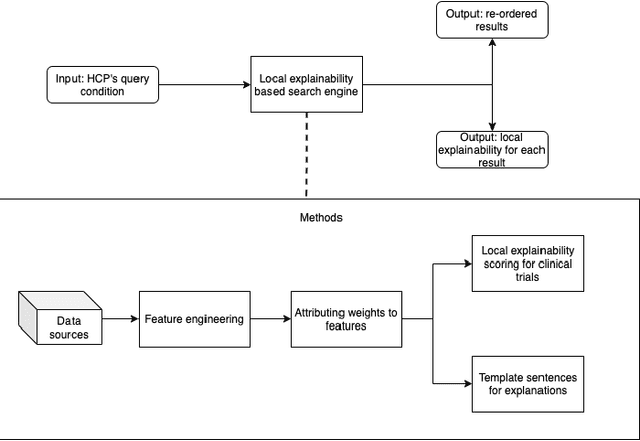
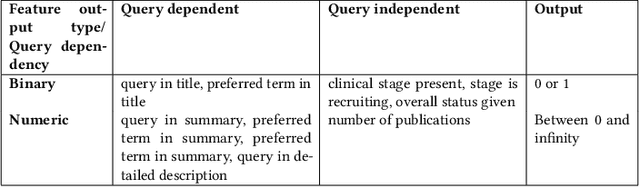
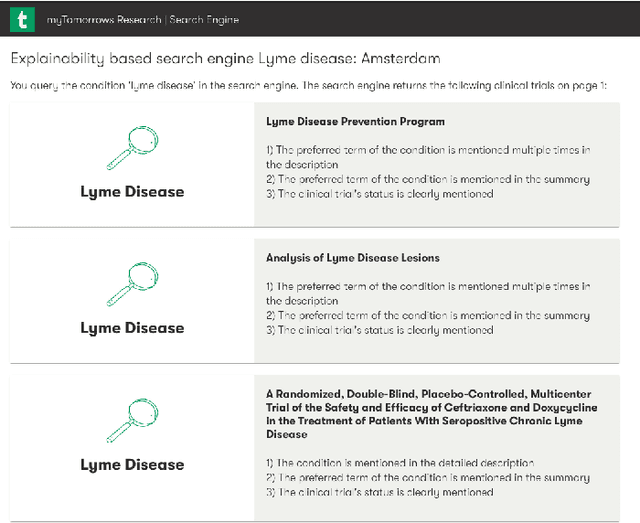
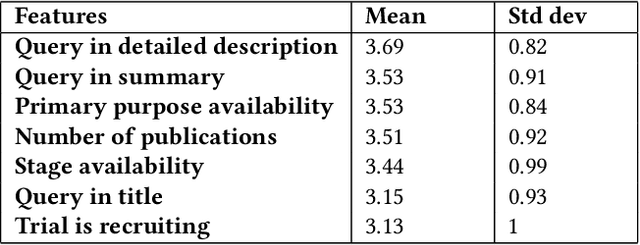
Health care professionals rely on treatment search engines to efficiently find adequate clinical trials and early access programs for their patients. However, doctors lose trust in the system if its underlying processes are unclear and unexplained. In this paper, a model-agnostic explainable method is developed to provide users with further information regarding the reasons why a clinical trial is retrieved in response to a query. To accomplish this, the engine generates features from clinical trials using by using a knowledge graph, clinical trial data and additional medical resources. and a crowd-sourcing methodology is used to determine their importance. Grounded on the proposed methodology, the rationale behind retrieving the clinical trials is explained in layman's terms so that healthcare processionals can effortlessly perceive them. In addition, we compute an explainability score for each of the retrieved items, according to which the items can be ranked. The experiments validated by medical professionals suggest that the proposed methodology induces trust in targeted as well as in non-targeted users, and provide them with reliable explanations and ranking of retrieved items.
An efficient projection neural network for $\ell_1$-regularized logistic regression
May 12, 2021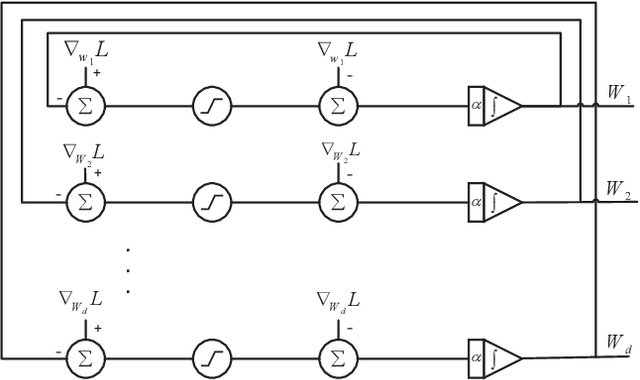
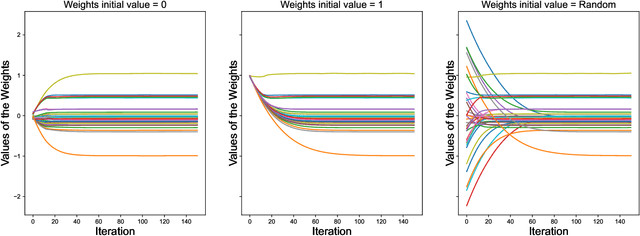
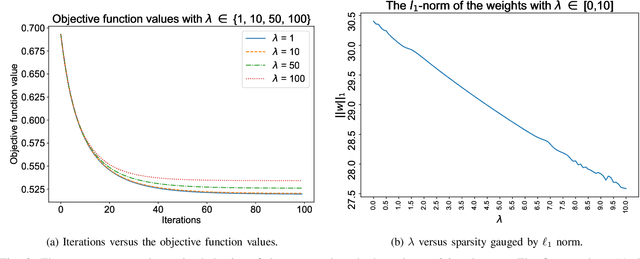
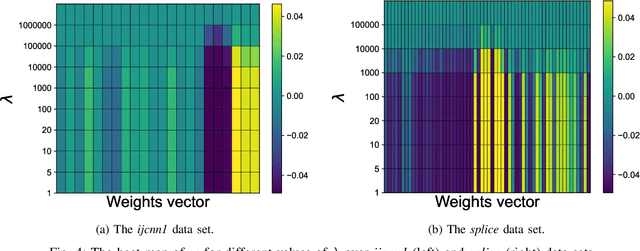
$\ell_1$ regularization has been used for logistic regression to circumvent the overfitting and use the estimated sparse coefficient for feature selection. However, the challenge of such a regularization is that the $\ell_1$ norm is not differentiable, making the standard algorithms for convex optimization not applicable to this problem. This paper presents a simple projection neural network for $\ell_1$-regularized logistics regression. In contrast to many available solvers in the literature, the proposed neural network does not require any extra auxiliary variable nor any smooth approximation, and its complexity is almost identical to that of the gradient descent for logistic regression without $\ell_1$ regularization, thanks to the projection operator. We also investigate the convergence of the proposed neural network by using the Lyapunov theory and show that it converges to a solution of the problem with any arbitrary initial value. The proposed neural solution significantly outperforms state-of-the-art methods with respect to the execution time and is competitive in terms of accuracy and AUROC.
SANOM Results for OAEI 2019
Jun 09, 2020
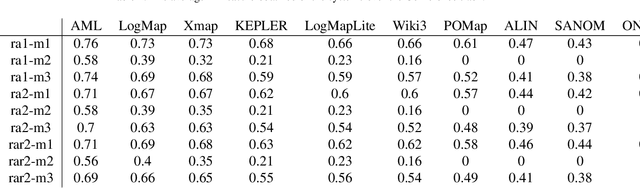


Simulated annealing-based ontology matching (SANOM) participates for the second time at the ontology alignment evaluation initiative (OAEI) 2019. This paper contains the configuration of SANOM and its results on the anatomy and conference tracks. In comparison to the OAEI 2017, SANOM has improved significantly, and its results are competitive with the state-of-the-art systems. In particular, SANOM has the highest recall rate among the participated systems in the conference track, and is competitive with AML, the best performing system, in terms of F-measure. SANOM is also competitive with LogMap on the anatomy track, which is the best performing system in this track with no usage of particular biomedical background knowledge. SANOM has been adapted to the HOBBIT platfrom and is now available for the registered users.