 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Shared Query Understanding in an Open Multi-Agent System
May 16, 2023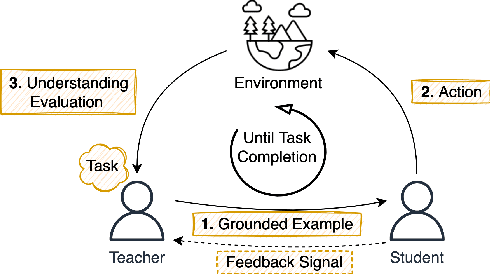
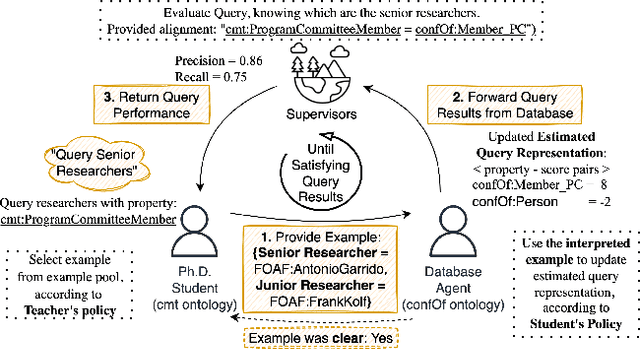
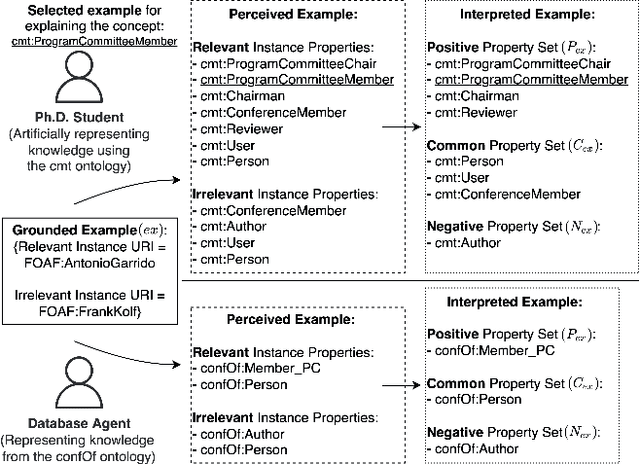
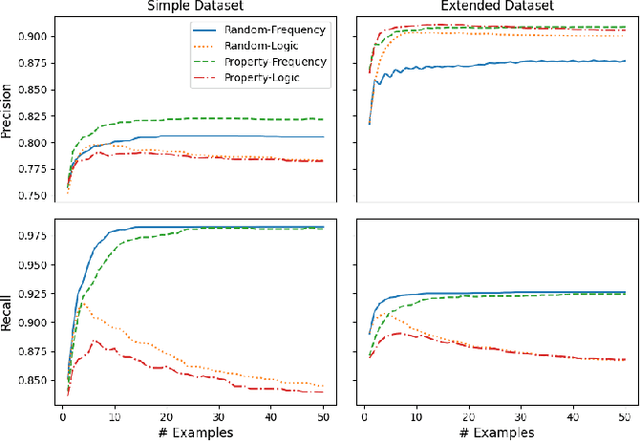
We propose a method that allows to develop shared understanding between two agents for the purpose of performing a task that requires cooperation. Our method focuses on efficiently establishing successful task-oriented communication in an open multi-agent system, where the agents do not know anything about each other and can only communicate via grounded interaction. The method aims to assist researchers that work on human-machine interaction or scenarios that require a human-in-the-loop, by defining interaction restrictions and efficiency metrics. To that end, we point out the challenges and limitations of such a (diverse) setup, while also restrictions and requirements which aim to ensure that high task performance truthfully reflects the extent to which the agents correctly understand each other. Furthermore, we demonstrate a use-case where our method can be applied for the task of cooperative query answering. We design the experiments by modifying an established ontology alignment benchmark. In this example, the agents want to query each other, while representing different databases, defined in their own ontologies that contain different and incomplete knowledge. Grounded interaction here has the form of examples that consists of common instances, for which the agents are expected to have similar knowledge. Our experiments demonstrate successful communication establishment under the required restrictions, and compare different agent policies that aim to solve the task in an efficient manner.
A-NeSI: A Scalable Approximate Method for Probabilistic Neurosymbolic Inference
Dec 23, 2022



We study the problem of combining neural networks with symbolic reasoning. Recently introduced frameworks for Probabilistic Neurosymbolic Learning (PNL), such as DeepProbLog, perform exponential-time exact inference, limiting the scalability of PNL solutions. We introduce Approximate Neurosymbolic Inference (A-NeSI): a new framework for PNL that uses neural networks for scalable approximate inference. A-NeSI 1) performs approximate inference in polynomial time without changing the semantics of probabilistic logics; 2) is trained using data generated by the background knowledge; 3) can generate symbolic explanations of predictions; and 4) can guarantee the satisfaction of logical constraints at test time, which is vital in safety-critical applications. Our experiments show that A-NeSI is the first end-to-end method to scale the Multi-digit MNISTAdd benchmark to sums of 15 MNIST digits, up from 4 in competing systems. Finally, our experiments show that A-NeSI achieves explainability and safety without a penalty in performance.
Local Explanations for Clinical Search Engine results
Oct 19, 2021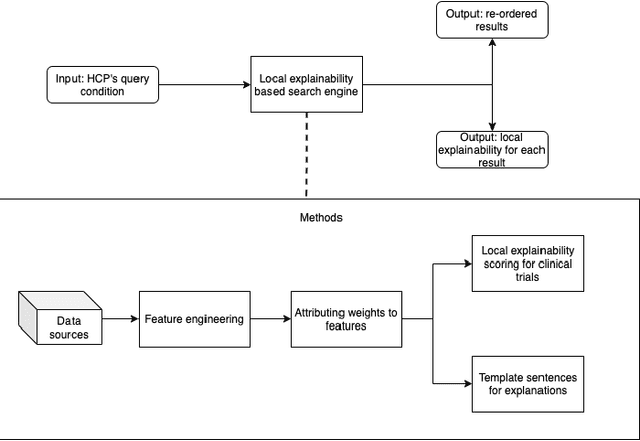
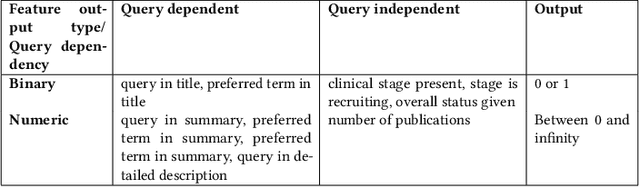
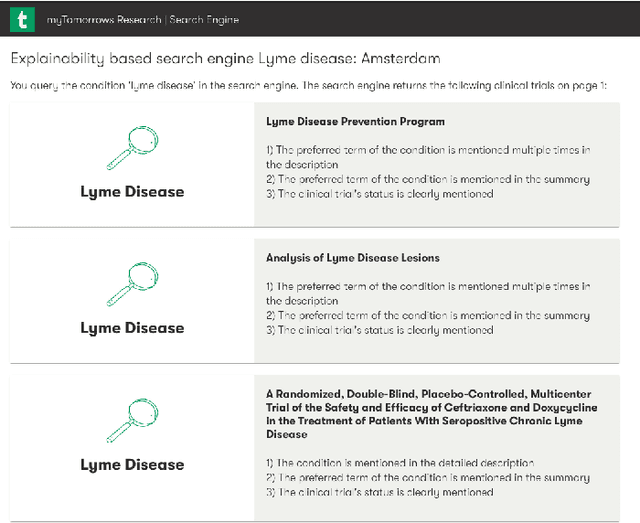
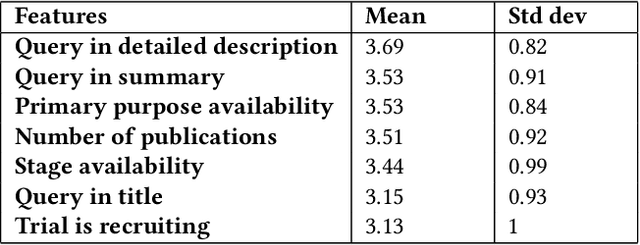
Health care professionals rely on treatment search engines to efficiently find adequate clinical trials and early access programs for their patients. However, doctors lose trust in the system if its underlying processes are unclear and unexplained. In this paper, a model-agnostic explainable method is developed to provide users with further information regarding the reasons why a clinical trial is retrieved in response to a query. To accomplish this, the engine generates features from clinical trials using by using a knowledge graph, clinical trial data and additional medical resources. and a crowd-sourcing methodology is used to determine their importance. Grounded on the proposed methodology, the rationale behind retrieving the clinical trials is explained in layman's terms so that healthcare processionals can effortlessly perceive them. In addition, we compute an explainability score for each of the retrieved items, according to which the items can be ranked. The experiments validated by medical professionals suggest that the proposed methodology induces trust in targeted as well as in non-targeted users, and provide them with reliable explanations and ranking of retrieved items.
Storchastic: A Framework for General Stochastic Automatic Differentiation
Apr 01, 2021

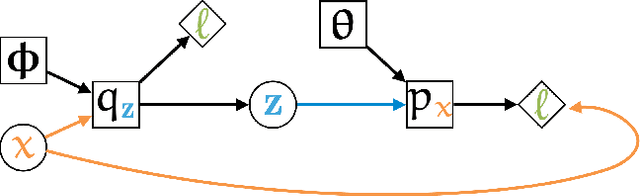

Modelers use automatic differentiation of computation graphs to implement complex Deep Learning models without defining gradient computations. However, modelers often use sampling methods to estimate intractable expectations such as in Reinforcement Learning and Variational Inference. Current methods for estimating gradients through these sampling steps are limited: They are either only applicable to continuous random variables and differentiable functions, or can only use simple but high variance score-function estimators. To overcome these limitations, we introduce Storchastic, a new framework for automatic differentiation of stochastic computation graphs. Storchastic allows the modeler to choose from a wide variety of gradient estimation methods at each sampling step, to optimally reduce the variance of the gradient estimates. Furthermore, Storchastic is provably unbiased for estimation of any-order gradients, and generalizes variance reduction techniques to higher-order gradient estimates. Finally, we implement Storchastic as a PyTorch library.
Modular Design Patterns for Hybrid Learning and Reasoning Systems: a taxonomy, patterns and use cases
Feb 23, 2021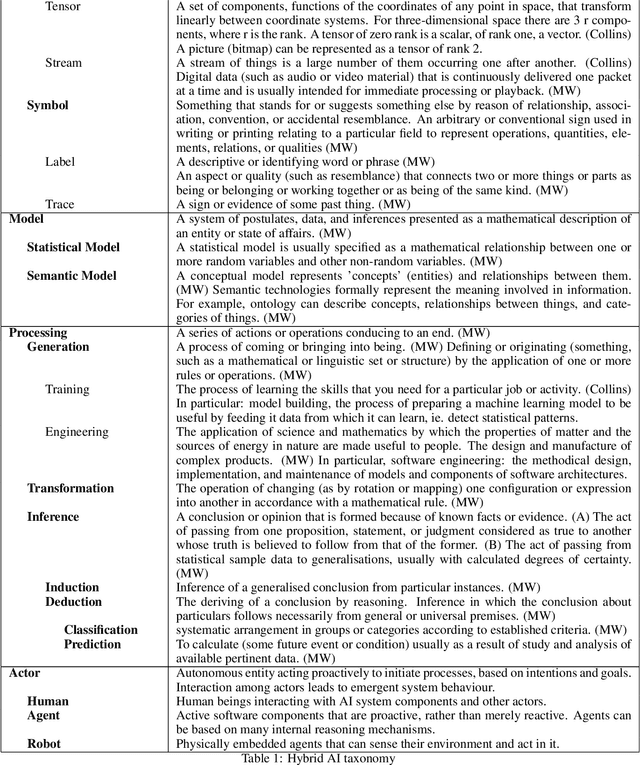
The unification of statistical (data-driven) and symbolic (knowledge-driven) methods is widely recognised as one of the key challenges of modern AI. Recent years have seen large number of publications on such hybrid neuro-symbolic AI systems. That rapidly growing literature is highly diverse and mostly empirical, and is lacking a unifying view of the large variety of these hybrid systems. In this paper we analyse a large body of recent literature and we propose a set of modular design patterns for such hybrid, neuro-symbolic systems. We are able to describe the architecture of a very large number of hybrid systems by composing only a small set of elementary patterns as building blocks. The main contributions of this paper are: 1) a taxonomically organised vocabulary to describe both processes and data structures used in hybrid systems; 2) a set of 15+ design patterns for hybrid AI systems, organised in a set of elementary patterns and a set of compositional patterns; 3) an application of these design patterns in two realistic use-cases for hybrid AI systems. Our patterns reveal similarities between systems that were not recognised until now. Finally, our design patterns extend and refine Kautz' earlier attempt at categorising neuro-symbolic architectures.
A Boxology of Design Patterns for Hybrid Learning and Reasoning Systems
May 29, 2019We propose a set of compositional design patterns to describe a large variety of systems that combine statistical techniques from machine learning with symbolic techniques from knowledge representation. As in other areas of computer science (knowledge engineering, software engineering, ontology engineering, process mining and others), such design patterns help to systematize the literature, clarify which combinations of techniques serve which purposes, and encourage re-use of software components. We have validated our set of compositional design patterns against a large body of recent literature.
* 12 pages,55 references