 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the AI Trustworthiness Gap between Functions and Norms
Dec 19, 2025Trustworthy Artificial Intelligence (TAI) is gaining traction due to regulations and functional benefits. While Functional TAI (FTAI) focuses on how to implement trustworthy systems, Normative TAI (NTAI) focuses on regulations that need to be enforced. However, gaps between FTAI and NTAI remain, making it difficult to assess trustworthiness of AI systems. We argue that a bridge is needed, specifically by introducing a conceptual language which can match FTAI and NTAI. Such a semantic language can assist developers as a framework to assess AI systems in terms of trustworthiness. It can also help stakeholders translate norms and regulations into concrete implementation steps for their systems. In this position paper, we describe the current state-of-the-art and identify the gap between FTAI and NTAI. We will discuss starting points for developing a semantic language and the envisioned effects of it. Finally, we provide key considerations and discuss future actions towards assessment of TAI.
Affordance Perception by a Knowledge-Guided Vision-Language Model with Efficient Error Correction
Jul 18, 2024Mobile robot platforms will increasingly be tasked with activities that involve grasping and manipulating objects in open world environments. Affordance understanding provides a robot with means to realise its goals and execute its tasks, e.g. to achieve autonomous navigation in unknown buildings where it has to find doors and ways to open these. In order to get actionable suggestions, robots need to be able to distinguish subtle differences between objects, as they may result in different action sequences: doorknobs require grasp and twist, while handlebars require grasp and push. In this paper, we improve affordance perception for a robot in an open-world setting. Our contribution is threefold: (1) We provide an affordance representation with precise, actionable affordances; (2) We connect this knowledge base to a foundational vision-language models (VLM) and prompt the VLM for a wider variety of new and unseen objects; (3) We apply a human-in-the-loop for corrections on the output of the VLM. The mix of affordance representation, image detection and a human-in-the-loop is effective for a robot to search for objects to achieve its goals. We have demonstrated this in a scenario of finding various doors and the many different ways to open them.
* 15 pages
Which objects help me to act effectively? Reasoning about physically-grounded affordances
Jul 18, 2024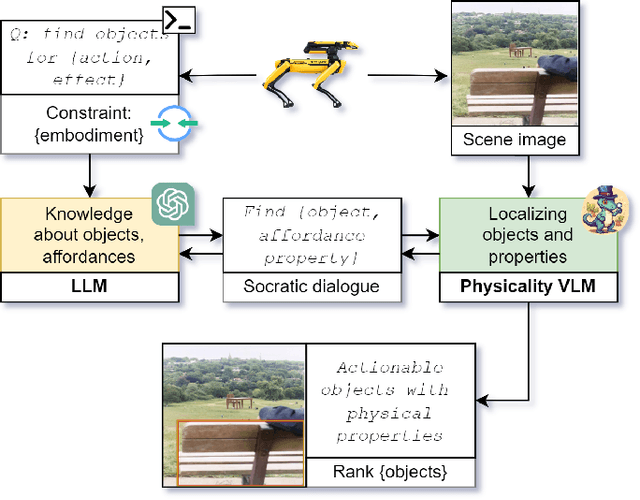
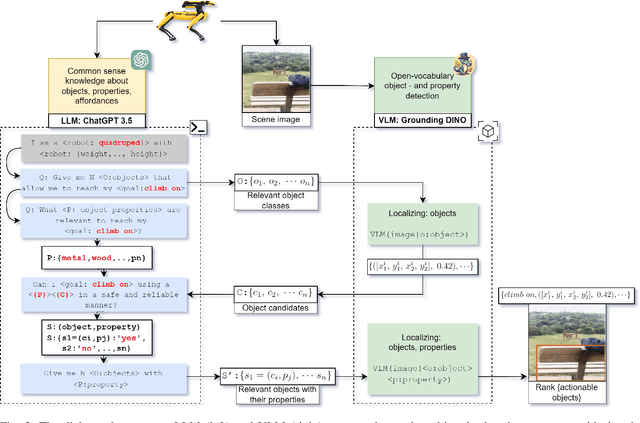


For effective interactions with the open world, robots should understand how interactions with known and novel objects help them towards their goal. A key aspect of this understanding lies in detecting an object's affordances, which represent the potential effects that can be achieved by manipulating the object in various ways. Our approach leverages a dialogue of large language models (LLMs) and vision-language models (VLMs) to achieve open-world affordance detection. Given open-vocabulary descriptions of intended actions and effects, the useful objects in the environment are found. By grounding our system in the physical world, we account for the robot's embodiment and the intrinsic properties of the objects it encounters. In our experiments, we have shown that our method produces tailored outputs based on different embodiments or intended effects. The method was able to select a useful object from a set of distractors. Finetuning the VLM for physical properties improved overall performance. These results underline the importance of grounding the affordance search in the physical world, by taking into account robot embodiment and the physical properties of objects.
* 10 pages
Open-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Jul 18, 2024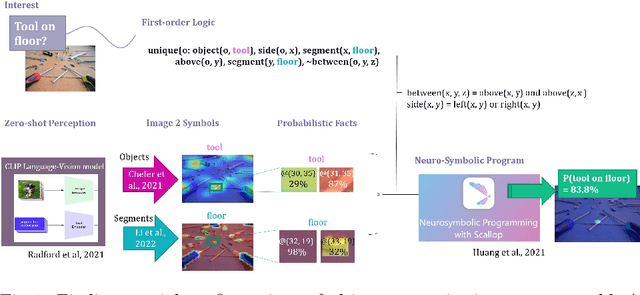



We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
* 12 pages
Modular Design Patterns for Hybrid Learning and Reasoning Systems: a taxonomy, patterns and use cases
Feb 23, 2021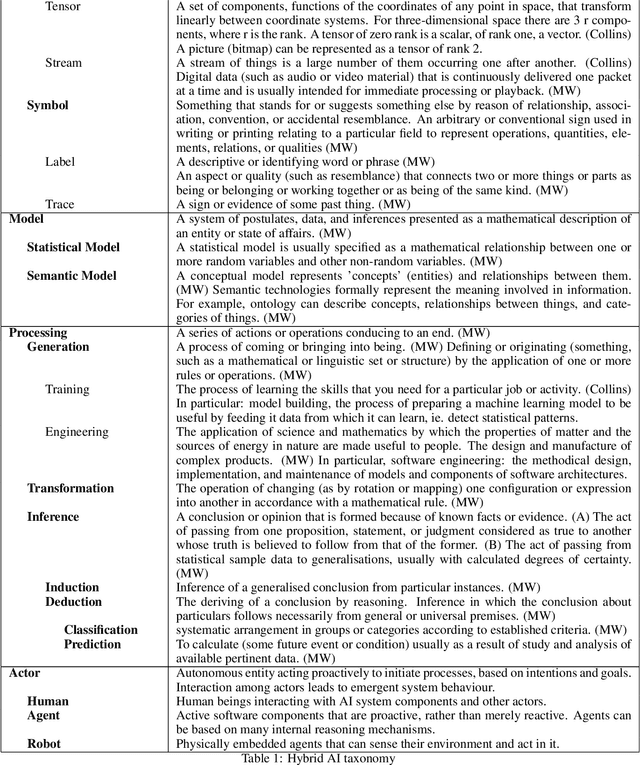
The unification of statistical (data-driven) and symbolic (knowledge-driven) methods is widely recognised as one of the key challenges of modern AI. Recent years have seen large number of publications on such hybrid neuro-symbolic AI systems. That rapidly growing literature is highly diverse and mostly empirical, and is lacking a unifying view of the large variety of these hybrid systems. In this paper we analyse a large body of recent literature and we propose a set of modular design patterns for such hybrid, neuro-symbolic systems. We are able to describe the architecture of a very large number of hybrid systems by composing only a small set of elementary patterns as building blocks. The main contributions of this paper are: 1) a taxonomically organised vocabulary to describe both processes and data structures used in hybrid systems; 2) a set of 15+ design patterns for hybrid AI systems, organised in a set of elementary patterns and a set of compositional patterns; 3) an application of these design patterns in two realistic use-cases for hybrid AI systems. Our patterns reveal similarities between systems that were not recognised until now. Finally, our design patterns extend and refine Kautz' earlier attempt at categorising neuro-symbolic architectures.
Adversarial Patch Camouflage against Aerial Detection
Aug 31, 2020
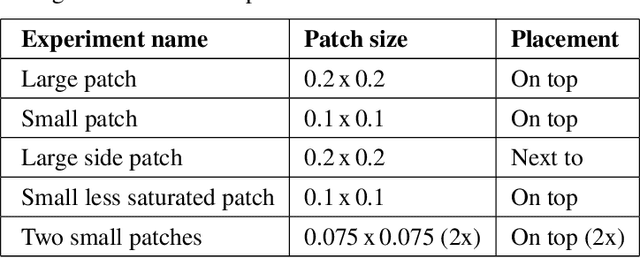

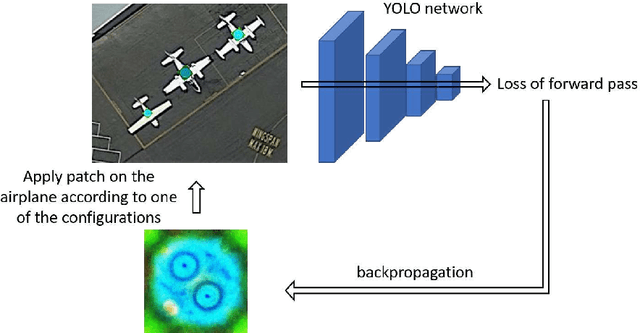
Detection of military assets on the ground can be performed by applying deep learning-based object detectors on drone surveillance footage. The traditional way of hiding military assets from sight is camouflage, for example by using camouflage nets. However, large assets like planes or vessels are difficult to conceal by means of traditional camouflage nets. An alternative type of camouflage is the direct misleading of automatic object detectors. Recently, it has been observed that small adversarial changes applied to images of the object can produce erroneous output by deep learning-based detectors. In particular, adversarial attacks have been successfully demonstrated to prohibit person detections in images, requiring a patch with a specific pattern held up in front of the person, thereby essentially camouflaging the person for the detector. Research into this type of patch attacks is still limited and several questions related to the optimal patch configuration remain open. This work makes two contributions. First, we apply patch-based adversarial attacks for the use case of unmanned aerial surveillance, where the patch is laid on top of large military assets, camouflaging them from automatic detectors running over the imagery. The patch can prevent automatic detection of the whole object while only covering a small part of it. Second, we perform several experiments with different patch configurations, varying their size, position, number and saliency. Our results show that adversarial patch attacks form a realistic alternative to traditional camouflage activities, and should therefore be considered in the automated analysis of aerial surveillance imagery.