 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Jul 18, 2024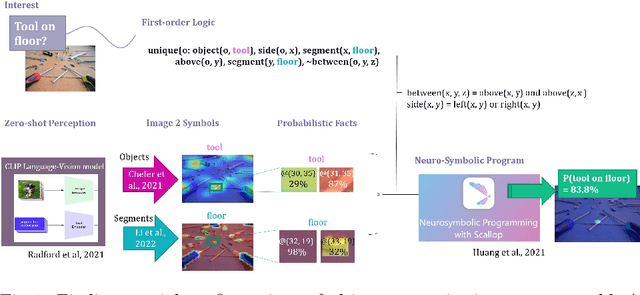



We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
* 12 pages
Affordance Perception by a Knowledge-Guided Vision-Language Model with Efficient Error Correction
Jul 18, 2024Mobile robot platforms will increasingly be tasked with activities that involve grasping and manipulating objects in open world environments. Affordance understanding provides a robot with means to realise its goals and execute its tasks, e.g. to achieve autonomous navigation in unknown buildings where it has to find doors and ways to open these. In order to get actionable suggestions, robots need to be able to distinguish subtle differences between objects, as they may result in different action sequences: doorknobs require grasp and twist, while handlebars require grasp and push. In this paper, we improve affordance perception for a robot in an open-world setting. Our contribution is threefold: (1) We provide an affordance representation with precise, actionable affordances; (2) We connect this knowledge base to a foundational vision-language models (VLM) and prompt the VLM for a wider variety of new and unseen objects; (3) We apply a human-in-the-loop for corrections on the output of the VLM. The mix of affordance representation, image detection and a human-in-the-loop is effective for a robot to search for objects to achieve its goals. We have demonstrated this in a scenario of finding various doors and the many different ways to open them.
* 15 pages
Spot What Matters: Learning Context Using Graph Convolutional Networks for Weakly-Supervised Action Detection
Jul 28, 2021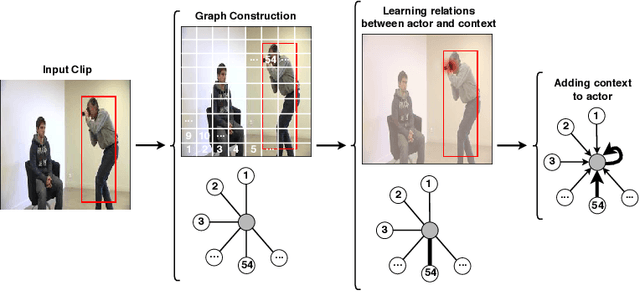
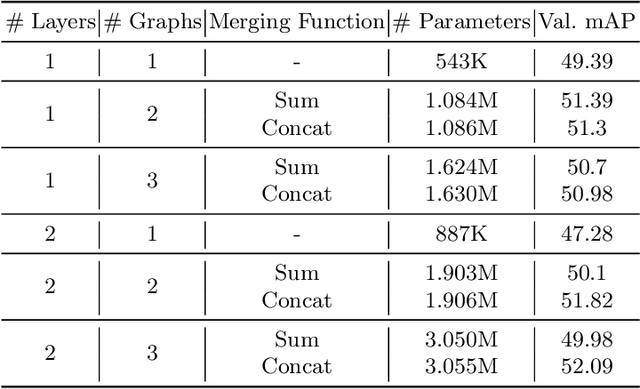
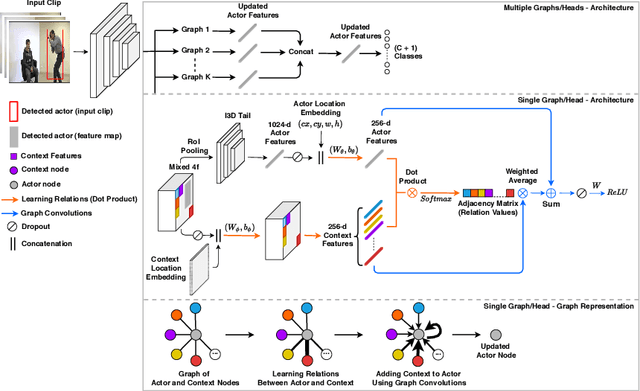
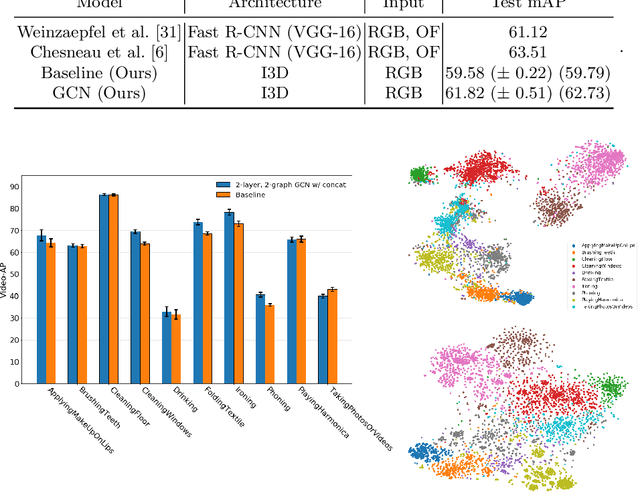
The dominant paradigm in spatiotemporal action detection is to classify actions using spatiotemporal features learned by 2D or 3D Convolutional Networks. We argue that several actions are characterized by their context, such as relevant objects and actors present in the video. To this end, we introduce an architecture based on self-attention and Graph Convolutional Networks in order to model contextual cues, such as actor-actor and actor-object interactions, to improve human action detection in video. We are interested in achieving this in a weakly-supervised setting, i.e. using as less annotations as possible in terms of action bounding boxes. Our model aids explainability by visualizing the learned context as an attention map, even for actions and objects unseen during training. We evaluate how well our model highlights the relevant context by introducing a quantitative metric based on recall of objects retrieved by attention maps. Our model relies on a 3D convolutional RGB stream, and does not require expensive optical flow computation. We evaluate our models on the DALY dataset, which consists of human-object interaction actions. Experimental results show that our contextualized approach outperforms a baseline action detection approach by more than 2 points in Video-mAP. Code is available at \url{https://github.com/micts/acgcn}
* Paper presented at the International Workshop on Deep Learning for Human-Centric Activity Understanding (DL-HAU2020), January 11, 2021