 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Learning of Affordances using Markov Logic Networks
Oct 23, 2024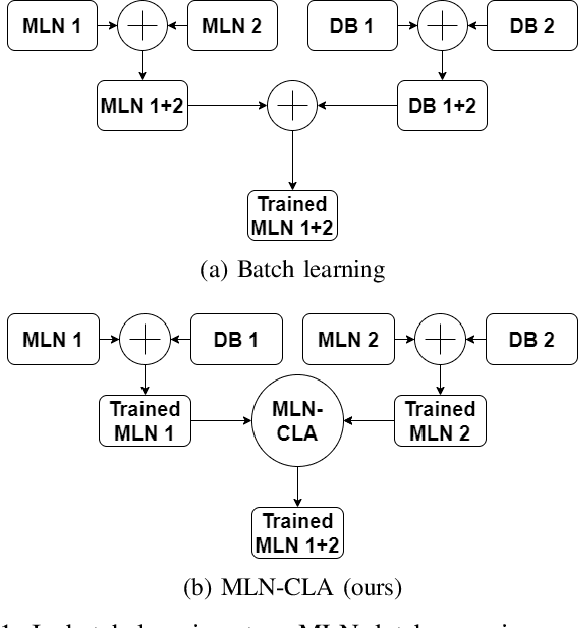
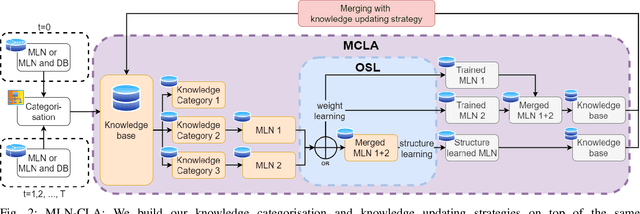
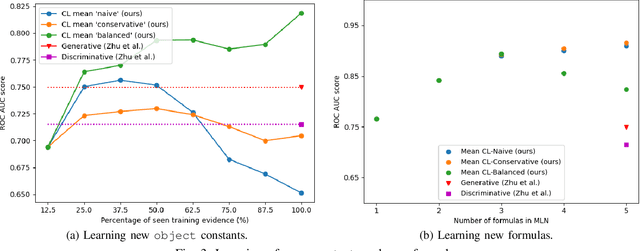
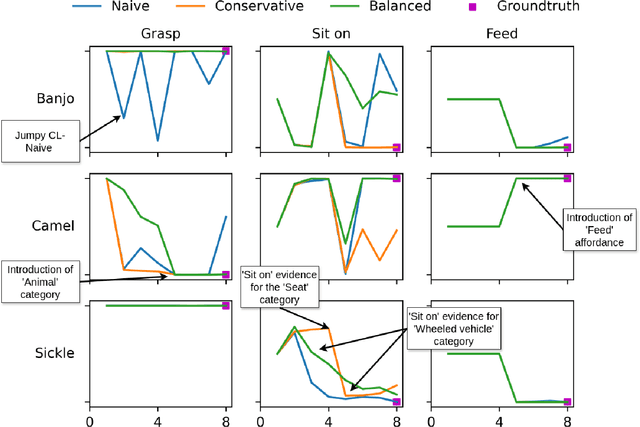
Affordances enable robots to have a semantic understanding of their surroundings. This allows them to have more acting flexibility when completing a given task. Capturing object affordances in a machine learning model is a difficult task, because of their dependence on contextual information. Markov Logic Networks (MLN) combine probabilistic reasoning with logic that is able to capture such context. Mobile robots operate in partially known environments wherein unseen object affordances can be observed. This new information must be incorporated into the existing knowledge, without having to retrain the MLN from scratch. We introduce the MLN Cumulative Learning Algorithm (MLN-CLA). MLN-CLA learns new relations in various knowledge domains by retaining knowledge and only updating the changed knowledge, for which the MLN is retrained. We show that MLN-CLA is effective for accumulative learning and zero-shot affordance inference, outperforming strong baselines.
* accepted at IEEE IRC 2024
Open-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Jul 18, 2024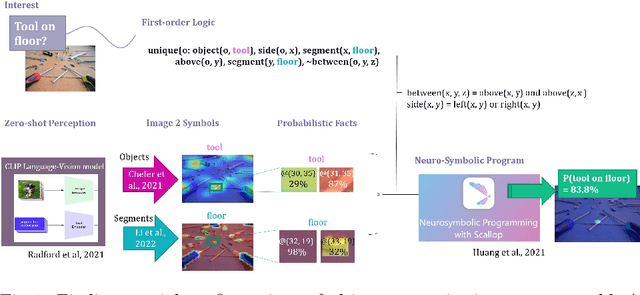



We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
* 12 pages