 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Visual Reasoning by a Neuro-Symbolic Program of Zero-Shot Symbols
Jul 18, 2024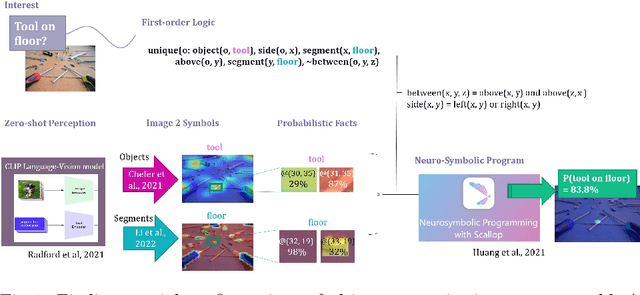



We consider the problem of finding spatial configurations of multiple objects in images, e.g., a mobile inspection robot is tasked to localize abandoned tools on the floor. We define the spatial configuration of objects by first-order logic in terms of relations and attributes. A neuro-symbolic program matches the logic formulas to probabilistic object proposals for the given image, provided by language-vision models by querying them for the symbols. This work is the first to combine neuro-symbolic programming (reasoning) and language-vision models (learning) to find spatial configurations of objects in images in an open world setting. We show the effectiveness by finding abandoned tools on floors and leaking pipes. We find that most prediction errors are due to biases in the language-vision model.
* 12 pages
PERFEX: Classifier Performance Explanations for Trustworthy AI Systems
Dec 12, 2022Explainability of a classification model is crucial when deployed in real-world decision support systems. Explanations make predictions actionable to the user and should inform about the capabilities and limitations of the system. Existing explanation methods, however, typically only provide explanations for individual predictions. Information about conditions under which the classifier is able to support the decision maker is not available, while for instance information about when the system is not able to differentiate classes can be very helpful. In the development phase it can support the search for new features or combining models, and in the operational phase it supports decision makers in deciding e.g. not to use the system. This paper presents a method to explain the qualities of a trained base classifier, called PERFormance EXplainer (PERFEX). Our method consists of a meta tree learning algorithm that is able to predict and explain under which conditions the base classifier has a high or low error or any other classification performance metric. We evaluate PERFEX using several classifiers and datasets, including a case study with urban mobility data. It turns out that PERFEX typically has high meta prediction performance even if the base classifier is hardly able to differentiate classes, while giving compact performance explanations.