 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender mobility in the labor market with skills-based matching models
Jul 17, 2023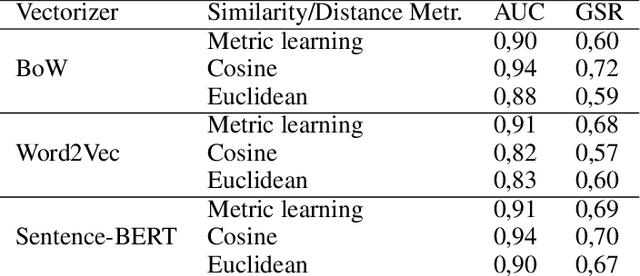
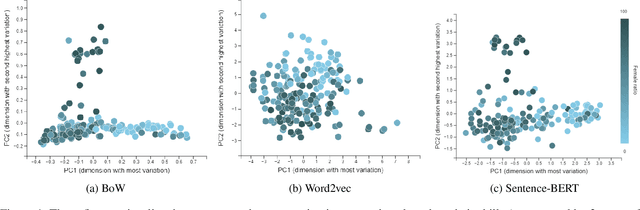
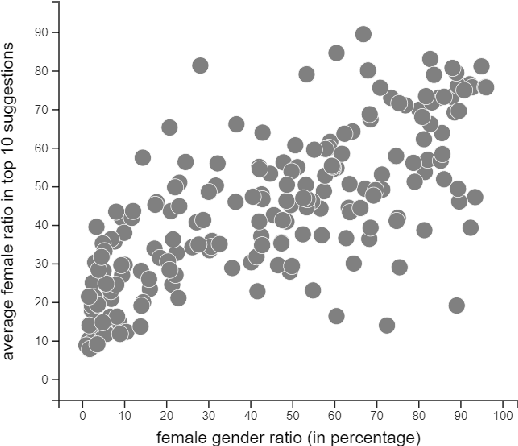
Skills-based matching promises mobility of workers between different sectors and occupations in the labor market. In this case, job seekers can look for jobs they do not yet have experience in, but for which they do have relevant skills. Currently, there are multiple occupations with a skewed gender distribution. For skills-based matching, it is unclear if and how a shift in the gender distribution, which we call gender mobility, between occupations will be effected. It is expected that the skills-based matching approach will likely be data-driven, including computational language models and supervised learning methods. This work, first, shows the presence of gender segregation in language model-based skills representation of occupations. Second, we assess the use of these representations in a potential application based on simulated data, and show that the gender segregation is propagated by various data-driven skills-based matching models.These models are based on different language representations (bag of words, word2vec, and BERT), and distance metrics (static and machine learning-based). Accordingly, we show how skills-based matching approaches can be evaluated and compared on matching performance as well as on the risk of gender segregation. Making the gender segregation bias of models more explicit can help in generating healthy trust in the use of these models in practice.
PERFEX: Classifier Performance Explanations for Trustworthy AI Systems
Dec 12, 2022Explainability of a classification model is crucial when deployed in real-world decision support systems. Explanations make predictions actionable to the user and should inform about the capabilities and limitations of the system. Existing explanation methods, however, typically only provide explanations for individual predictions. Information about conditions under which the classifier is able to support the decision maker is not available, while for instance information about when the system is not able to differentiate classes can be very helpful. In the development phase it can support the search for new features or combining models, and in the operational phase it supports decision makers in deciding e.g. not to use the system. This paper presents a method to explain the qualities of a trained base classifier, called PERFormance EXplainer (PERFEX). Our method consists of a meta tree learning algorithm that is able to predict and explain under which conditions the base classifier has a high or low error or any other classification performance metric. We evaluate PERFEX using several classifiers and datasets, including a case study with urban mobility data. It turns out that PERFEX typically has high meta prediction performance even if the base classifier is hardly able to differentiate classes, while giving compact performance explanations.
Adversarial Patch Camouflage against Aerial Detection
Aug 31, 2020
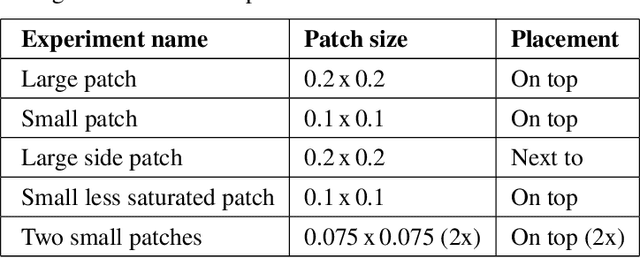

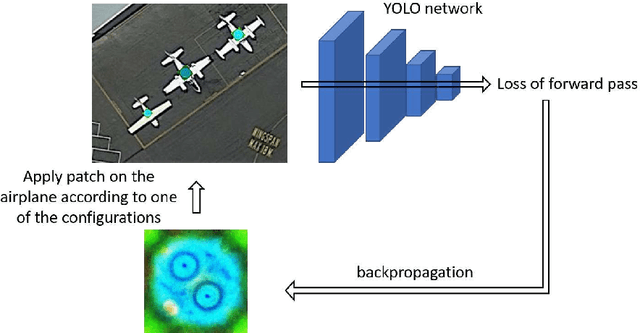
Detection of military assets on the ground can be performed by applying deep learning-based object detectors on drone surveillance footage. The traditional way of hiding military assets from sight is camouflage, for example by using camouflage nets. However, large assets like planes or vessels are difficult to conceal by means of traditional camouflage nets. An alternative type of camouflage is the direct misleading of automatic object detectors. Recently, it has been observed that small adversarial changes applied to images of the object can produce erroneous output by deep learning-based detectors. In particular, adversarial attacks have been successfully demonstrated to prohibit person detections in images, requiring a patch with a specific pattern held up in front of the person, thereby essentially camouflaging the person for the detector. Research into this type of patch attacks is still limited and several questions related to the optimal patch configuration remain open. This work makes two contributions. First, we apply patch-based adversarial attacks for the use case of unmanned aerial surveillance, where the patch is laid on top of large military assets, camouflaging them from automatic detectors running over the imagery. The patch can prevent automatic detection of the whole object while only covering a small part of it. Second, we perform several experiments with different patch configurations, varying their size, position, number and saliency. Our results show that adversarial patch attacks form a realistic alternative to traditional camouflage activities, and should therefore be considered in the automated analysis of aerial surveillance imagery.
Example and Feature importance-based Explanations for Black-box Machine Learning Models
Dec 21, 2018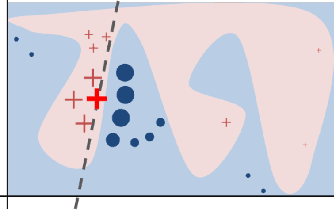
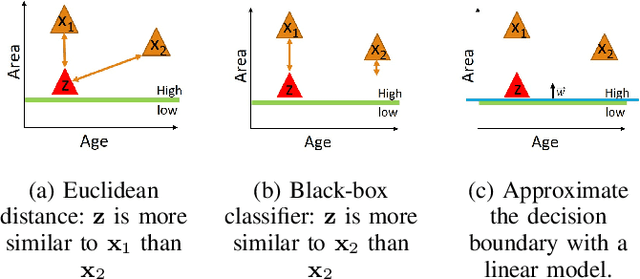
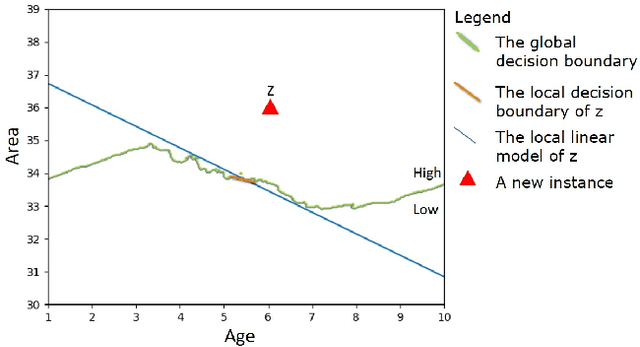
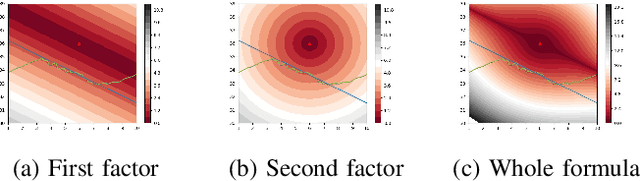
As machine learning models become more accurate, they typically become more complex and uninterpretable by humans. The black-box character of these models holds back its acceptance in practice, especially in high-risk domains where the consequences of failure could be catastrophic such as health-care or defense. Providing understandable and useful explanations behind ML models or predictions can increase the trust of the user. Example-based reasoning, which entails leveraging previous experience with analogous tasks to make a decision, is a well known strategy for problem solving and justification. This work presents a new explanation extraction method called LEAFAGE, for a prediction made by any black-box ML model. The explanation consists of the visualization of similar examples from the training set and the importance of each feature. Moreover, these explanations are contrastive which aims to take the expectations of the user into account. LEAFAGE is evaluated in terms of fidelity to the underlying black-box model and usefulness to the user. The results showed that LEAFAGE performs overall better than the current state-of-the-art method LIME in terms of fidelity, on ML models with non-linear decision boundary. A user-study was conducted which focused on revealing the differences between example-based and feature importance-based explanations. It showed that example-based explanations performed significantly better than feature importance-based explanation, in terms of perceived transparency, information sufficiency, competence and confidence. Counter-intuitively, when the gained knowledge of the participants was tested, it showed that they learned less about the black-box model after seeing a feature importance-based explanation than seeing no explanation at all. The participants found feature importance-based explanation vague and hard to generalize it to other instances.