 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOOL-MC: Verifying and Explaining RL Policies for Platelet Inventory Management
Mar 02, 2026Platelets expire within five days. Blood banks face uncertain daily demand and must balance ordering decisions between costly wastage from overstocking and life-threatening shortages from understocking. Reinforcement learning (RL) can learn effective ordering policies for this Markov decision process (MDP), but the resulting neural policies remain black boxes, hindering trust and adoption in safety-critical domains. We apply COOL-MC, a tool that combines RL with probabilistic model checking and explainable RL, to verify and explain a trained policy for the MDP on platelet inventory management inspired by Haijema et al. By constructing a policy-induced discrete-time Markov chain (which includes only the reachable states under the trained policy to reduce memory usage), we verify PCTL properties and provide feature-level explanations. Results show that the trained policy achieves a 2.9% stockout probability and a 1.1% inventory-full (potential wastage) probability within a 200-step horizon, primarily attends to the age distribution of inventory rather than other features such as day of week or pending orders. Action reachability analysis reveals that the policy employs a diverse replenishment strategy, with most order quantities reached quickly, while several are never selected. Counterfactual analysis shows that replacing medium-large orders with smaller ones leaves both safety probabilities nearly unchanged, indicating that these orders are placed in well-buffered inventory states. This first formal verification and explanation of an RL platelet inventory management policy demonstrates COOL-MC's value for transparent, auditable decision-making in safety-critical healthcare supply chain domains.
Formally Verifying and Explaining Sepsis Treatment Policies with COOL-MC
Feb 16, 2026Safe and interpretable sequential decision-making is critical in healthcare, yet reinforcement learning (RL) policies for sepsis treatment optimization remain opaque and difficult to verify. Standard probabilistic model checkers operate on the full state space, which becomes infeasible for larger MDPs, and cannot explain why a learned policy makes particular decisions. COOL-MC wraps the model checker Storm but adds three key capabilities: it constructs only the reachable state space induced by a trained policy, yielding a smaller discrete-time Markov chain amenable to verification even when full-MDP analysis is intractable; it automatically labels states with clinically meaningful atomic propositions; and it integrates explainability methods with probabilistic computation tree logic (PCTL) queries to reveal which features drive decisions across treatment trajectories. We demonstrate COOL-MC's capabilities on the ICU-Sepsis MDP, a benchmark derived from approximately 17,000 sepsis patient records, which serves as a case study for applying COOL-MC to the formal analysis of sepsis treatment policies. Our analysis establishes hard bounds via full MDP verification, trains a safe RL policy that achieves optimal survival probability, and analyzes its behavior via PCTL verification and explainability on the induced DTMC. This reveals, for instance, that our trained policy relies predominantly on prior dosing history rather than the patient's evolving condition, a weakness that is invisible to standard evaluation but is exposed by COOL-MC's integration of formal verification and explainability. Our results illustrate how COOL-MC could serve as a tool for clinicians to investigate and debug sepsis treatment policies before deployment.
Semi-supervised CAPP Transformer Learning via Pseudo-labeling
Feb 01, 2026High-level Computer-Aided Process Planning (CAPP) generates manufacturing process plans from part specifications. It suffers from limited dataset availability in industry, reducing model generalization. We propose a semi-supervised learning approach to improve transformer-based CAPP transformer models without manual labeling. An oracle, trained on available transformer behaviour data, filters correct predictions from unseen parts, which are then used for one-shot retraining. Experiments on small-scale datasets with simulated ground truth across the full data distribution show consistent accuracy gains over baselines, demonstrating the method's effectiveness in data-scarce manufacturing environments.
Translating the Rashomon Effect to Sequential Decision-Making Tasks
Dec 19, 2025The Rashomon effect describes the phenomenon where multiple models trained on the same data produce identical predictions while differing in which features they rely on internally. This effect has been studied extensively in classification tasks, but not in sequential decision-making, where an agent learns a policy to achieve an objective by taking actions in an environment. In this paper, we translate the Rashomon effect to sequential decision-making. We define it as multiple policies that exhibit identical behavior, visiting the same states and selecting the same actions, while differing in their internal structure, such as feature attributions. Verifying identical behavior in sequential decision-making differs from classification. In classification, predictions can be directly compared to ground-truth labels. In sequential decision-making with stochastic transitions, the same policy may succeed or fail on any single trajectory due to randomness. We address this using formal verification methods that construct and compare the complete probabilistic behavior of each policy in the environment. Our experiments demonstrate that the Rashomon effect exists in sequential decision-making. We further show that ensembles constructed from the Rashomon set exhibit greater robustness to distribution shifts than individual policies. Additionally, permissive policies derived from the Rashomon set reduce computational requirements for verification while maintaining optimal performance.
Co-Activation Graph Analysis of Safety-Verified and Explainable Deep Reinforcement Learning Policies
Jan 06, 2025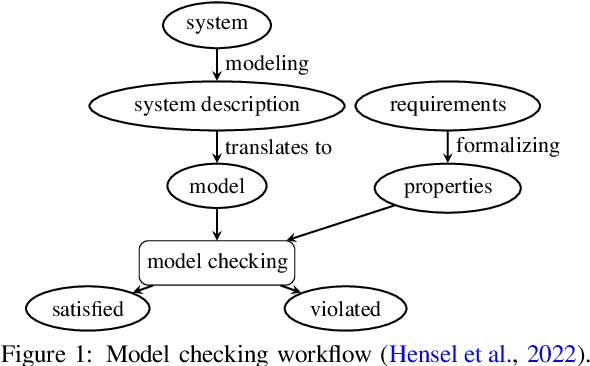
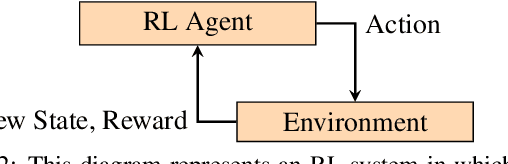
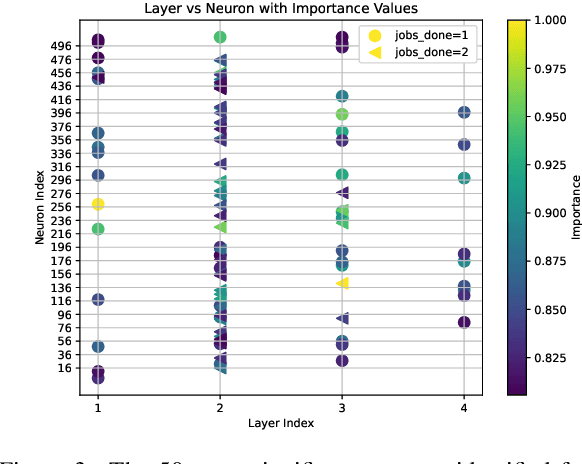
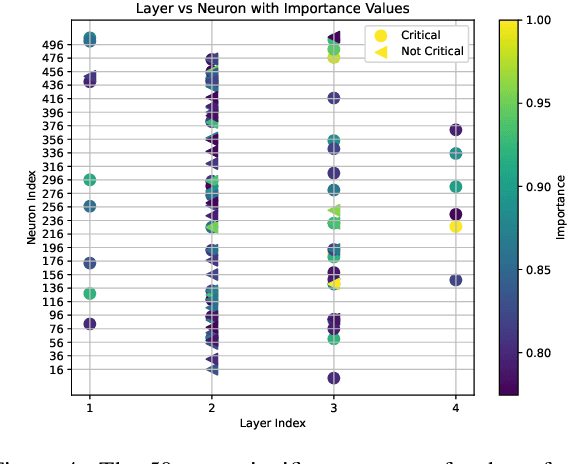
Deep reinforcement learning (RL) policies can demonstrate unsafe behaviors and are challenging to interpret. To address these challenges, we combine RL policy model checking--a technique for determining whether RL policies exhibit unsafe behaviors--with co-activation graph analysis--a method that maps neural network inner workings by analyzing neuron activation patterns--to gain insight into the safe RL policy's sequential decision-making. This combination lets us interpret the RL policy's inner workings for safe decision-making. We demonstrate its applicability in various experiments.
Turn-based Multi-Agent Reinforcement Learning Model Checking
Jan 06, 2025
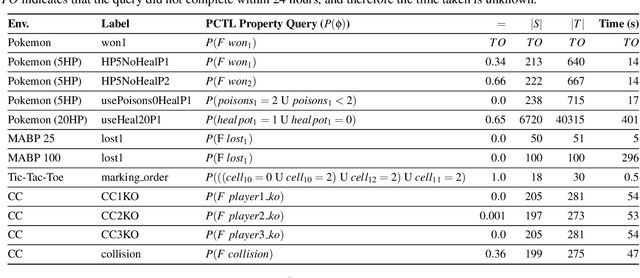
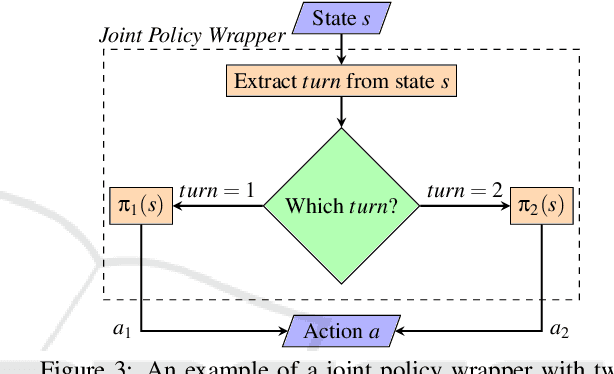
In this paper, we propose a novel approach for verifying the compliance of turn-based multi-agent reinforcement learning (TMARL) agents with complex requirements in stochastic multiplayer games. Our method overcomes the limitations of existing verification approaches, which are inadequate for dealing with TMARL agents and not scalable to large games with multiple agents. Our approach relies on tight integration of TMARL and a verification technique referred to as model checking. We demonstrate the effectiveness and scalability of our technique through experiments in different types of environments. Our experiments show that our method is suited to verify TMARL agents and scales better than naive monolithic model checking.
Efficient Milling Quality Prediction with Explainable Machine Learning
Sep 16, 2024
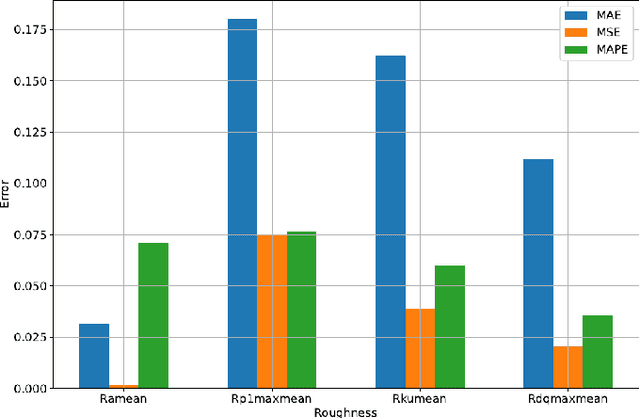
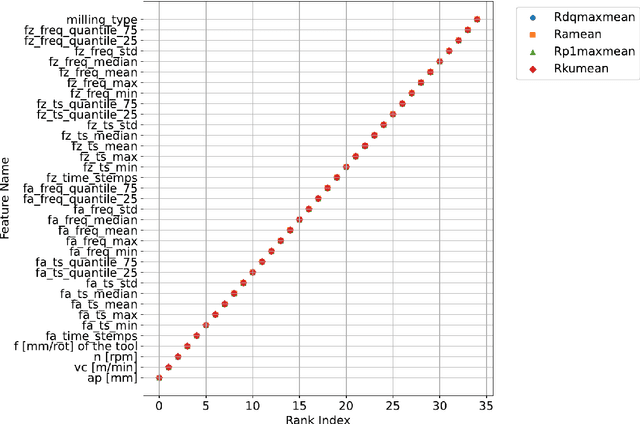
This paper presents an explainable machine learning (ML) approach for predicting surface roughness in milling. Utilizing a dataset from milling aluminum alloy 2017A, the study employs random forest regression models and feature importance techniques. The key contributions include developing ML models that accurately predict various roughness values and identifying redundant sensors, particularly those for measuring normal cutting force. Our experiments show that removing certain sensors can reduce costs without sacrificing predictive accuracy, highlighting the potential of explainable machine learning to improve cost-effectiveness in machining.
Enhancing RL Safety with Counterfactual LLM Reasoning
Sep 16, 2024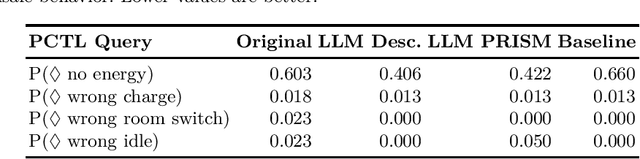
Reinforcement learning (RL) policies may exhibit unsafe behavior and are hard to explain. We use counterfactual large language model reasoning to enhance RL policy safety post-training. We show that our approach improves and helps to explain the RL policy safety.
Safety-Oriented Pruning and Interpretation of Reinforcement Learning Policies
Sep 16, 2024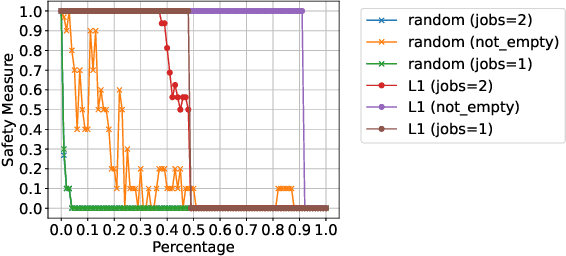

Pruning neural networks (NNs) can streamline them but risks removing vital parameters from safe reinforcement learning (RL) policies. We introduce an interpretable RL method called VERINTER, which combines NN pruning with model checking to ensure interpretable RL safety. VERINTER exactly quantifies the effects of pruning and the impact of neural connections on complex safety properties by analyzing changes in safety measurements. This method maintains safety in pruned RL policies and enhances understanding of their safety dynamics, which has proven effective in multiple RL settings.
Probabilistic Model Checking of Stochastic Reinforcement Learning Policies
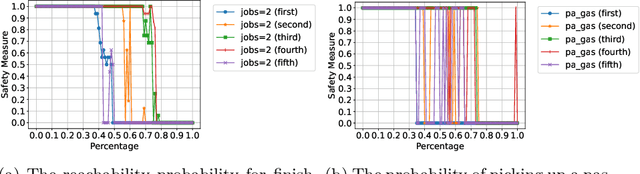
Mar 27, 2024
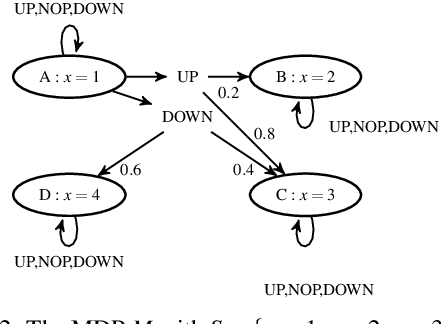

We introduce a method to verify stochastic reinforcement learning (RL) policies. This approach is compatible with any RL algorithm as long as the algorithm and its corresponding environment collectively adhere to the Markov property. In this setting, the future state of the environment should depend solely on its current state and the action executed, independent of any previous states or actions. Our method integrates a verification technique, referred to as model checking, with RL, leveraging a Markov decision process, a trained RL policy, and a probabilistic computation tree logic (PCTL) formula to build a formal model that can be subsequently verified via the model checker Storm. We demonstrate our method's applicability across multiple benchmarks, comparing it to baseline methods called deterministic safety estimates and naive monolithic model checking. Our results show that our method is suited to verify stochastic RL policies.