 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Efficiently Monitorable Formulas in Metric Temporal Logic
Oct 26, 2023In runtime verification, manually formalizing a specification for monitoring system executions is a tedious and error-prone process. To address this issue, we consider the problem of automatically synthesizing formal specifications from system executions. To demonstrate our approach, we consider the popular specification language Metric Temporal Logic (MTL), which is particularly tailored towards specifying temporal properties for cyber-physical systems (CPS). Most of the classical approaches for synthesizing temporal logic formulas aim at minimizing the size of the formula. However, for efficiency in monitoring, along with the size, the amount of "lookahead" required for the specification becomes relevant, especially for safety-critical applications. We formalize this notion and devise a learning algorithm that synthesizes concise formulas having bounded lookahead. To do so, our algorithm reduces the synthesis task to a series of satisfiability problems in Linear Real Arithmetic (LRA) and generates MTL formulas from their satisfying assignments. The reduction uses a novel encoding of a popular MTL monitoring procedure using LRA. Finally, we implement our algorithm in a tool called TEAL and demonstrate its ability to synthesize efficiently monitorable MTL formulas in a CPS application.
Targeted Adversarial Attacks on Deep Reinforcement Learning Policies via Model Checking
Dec 10, 2022Deep Reinforcement Learning (RL) agents are susceptible to adversarial noise in their observations that can mislead their policies and decrease their performance. However, an adversary may be interested not only in decreasing the reward, but also in modifying specific temporal logic properties of the policy. This paper presents a metric that measures the exact impact of adversarial attacks against such properties. We use this metric to craft optimal adversarial attacks. Furthermore, we introduce a model checking method that allows us to verify the robustness of RL policies against adversarial attacks. Our empirical analysis confirms (1) the quality of our metric to craft adversarial attacks against temporal logic properties, and (2) that we are able to concisely assess a system's robustness against attacks.
COOL-MC: A Comprehensive Tool for Reinforcement Learning and Model Checking
Sep 15, 2022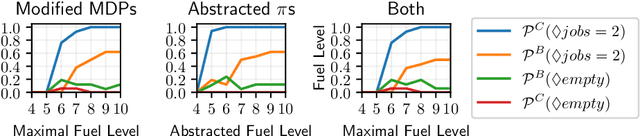
This paper presents COOL-MC, a tool that integrates state-of-the-art reinforcement learning (RL) and model checking. Specifically, the tool builds upon the OpenAI gym and the probabilistic model checker Storm. COOL-MC provides the following features: (1) a simulator to train RL policies in the OpenAI gym for Markov decision processes (MDPs) that are defined as input for Storm, (2) a new model builder for Storm, which uses callback functions to verify (neural network) RL policies, (3) formal abstractions that relate models and policies specified in OpenAI gym or Storm, and (4) algorithms to obtain bounds on the performance of so-called permissive policies. We describe the components and architecture of COOL-MC and demonstrate its features on multiple benchmark environments.
Lecture Notes on Partially Known MDPs
Dec 06, 2021In these notes we will tackle the problem of finding optimal policies for Markov decision processes (MDPs) which are not fully known to us. Our intention is to slowly transition from an offline setting to an online (learning) setting. Namely, we are moving towards reinforcement learning.
Active Learning of Sequential Transducers with Side Information about the Domain
Apr 23, 2021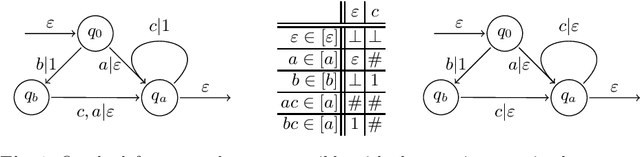
Active learning is a setting in which a student queries a teacher, through membership and equivalence queries, in order to learn a language. Performance on these algorithms is often measured in the number of queries required to learn a target, with an emphasis on costly equivalence queries. In graybox learning, the learning process is accelerated by foreknowledge of some information on the target. Here, we consider graybox active learning of subsequential string transducers, where a regular overapproximation of the domain is known by the student. We show that there exists an algorithm using string equation solvers that uses this knowledge to learn subsequential string transducers with a better guarantee on the required number of equivalence queries than classical active learning.
The Complexity of Graph-Based Reductions for Reachability in Markov Decision Processes
Feb 24, 2018
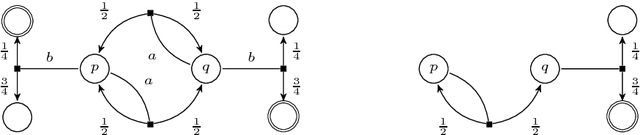


We study the never-worse relation (NWR) for Markov decision processes with an infinite-horizon reachability objective. A state q is never worse than a state p if the maximal probability of reaching the target set of states from p is at most the same value from q, regard- less of the probabilities labelling the transitions. Extremal-probability states, end components, and essential states are all special cases of the equivalence relation induced by the NWR. Using the NWR, states in the same equivalence class can be collapsed. Then, actions leading to sub- optimal states can be removed. We show the natural decision problem associated to computing the NWR is coNP-complete. Finally, we ex- tend a previously known incomplete polynomial-time iterative algorithm to under-approximate the NWR.