 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShields to Guarantee Probabilistic Safety in MDPs
May 11, 2026Shielding is a prominent model-based technique to ensure safety of autonomous agents. Classical shielding aims to ensure that nothing bad ever happens and comes with strong guarantees about safety and maximal permissiveness. However, shielding systems for probabilistic safety, where something bad is allowed to happen with an acceptable probability, has proven to be more intricate. This paper presents a formal framework that conservatively extends classical shields to probabilistic safety. In this framework, we (i) demonstrate the impossibility of preserving the strong guarantees on safety and permissiveness, (ii) provide natural shields with weaker guarantees, and (iii) introduce offline and online shield constructions ensuring strong safety guarantees. The empirical evaluation highlights the practical advantages of the new shields, as well as their computational feasibility.
Error-awareness Accelerates Active Automata Learning
Feb 25, 2026Active automata learning (AAL) algorithms can learn a behavioral model of a system from interacting with it. The primary challenge remains scaling to larger models, in particular in the presence of many possible inputs to the system. Modern AAL algorithms fail to scale even if, in every state, most inputs lead to errors. In various challenging problems from the literature, these errors are observable, i.e., they emit a known error output. Motivated by these problems, we study learning these systems more efficiently. Further, we consider various degrees of knowledge about which inputs are non-error producing at which state. For each level of knowledge, we provide a matching adaptation of the state-of-the-art AAL algorithm L# to make the most of this domain knowledge. Our empirical evaluation demonstrates that the methods accelerate learning by orders of magnitude with strong but realistic domain knowledge to a single order of magnitude with limited domain knowledge.
Constrained and Robust Policy Synthesis with Satisfiability-Modulo-Probabilistic-Model-Checking
Nov 15, 2025



The ability to compute reward-optimal policies for given and known finite Markov decision processes (MDPs) underpins a variety of applications across planning, controller synthesis, and verification. However, we often want policies (1) to be robust, i.e., they perform well on perturbations of the MDP and (2) to satisfy additional structural constraints regarding, e.g., their representation or implementation cost. Computing such robust and constrained policies is indeed computationally more challenging. This paper contributes the first approach to effectively compute robust policies subject to arbitrary structural constraints using a flexible and efficient framework. We achieve flexibility by allowing to express our constraints in a first-order theory over a set of MDPs, while the root for our efficiency lies in the tight integration of satisfiability solvers to handle the combinatorial nature of the problem and probabilistic model checking algorithms to handle the analysis of MDPs. Experiments on a few hundred benchmarks demonstrate the feasibility for constrained and robust policy synthesis and the competitiveness with state-of-the-art methods for various fragments of the problem.
\textsc{rfPG}: Robust Finite-Memory Policy Gradients for Hidden-Model POMDPs
May 14, 2025Partially observable Markov decision processes (POMDPs) model specific environments in sequential decision-making under uncertainty. Critically, optimal policies for POMDPs may not be robust against perturbations in the environment. Hidden-model POMDPs (HM-POMDPs) capture sets of different environment models, that is, POMDPs with a shared action and observation space. The intuition is that the true model is hidden among a set of potential models, and it is unknown which model will be the environment at execution time. A policy is robust for a given HM-POMDP if it achieves sufficient performance for each of its POMDPs. We compute such robust policies by combining two orthogonal techniques: (1) a deductive formal verification technique that supports tractable robust policy evaluation by computing a worst-case POMDP within the HM-POMDP and (2) subgradient ascent to optimize the candidate policy for a worst-case POMDP. The empirical evaluation shows that, compared to various baselines, our approach (1) produces policies that are more robust and generalize better to unseen POMDPs and (2) scales to HM-POMDPs that consist of over a hundred thousand environments.
Tighter Value-Function Approximations for POMDPs
Feb 10, 2025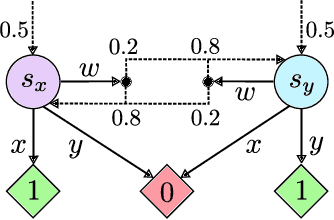

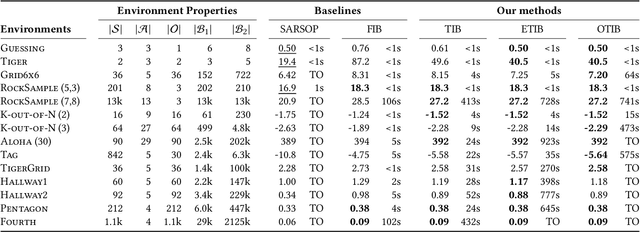
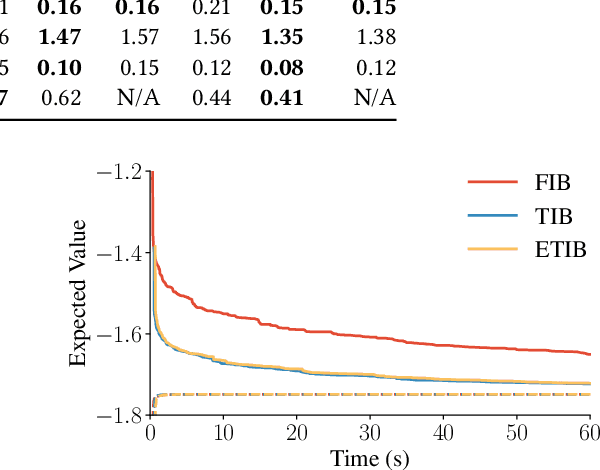
Solving partially observable Markov decision processes (POMDPs) typically requires reasoning about the values of exponentially many state beliefs. Towards practical performance, state-of-the-art solvers use value bounds to guide this reasoning. However, sound upper value bounds are often computationally expensive to compute, and there is a tradeoff between the tightness of such bounds and their computational cost. This paper introduces new and provably tighter upper value bounds than the commonly used fast informed bound. Our empirical evaluation shows that, despite their additional computational overhead, the new upper bounds accelerate state-of-the-art POMDP solvers on a wide range of benchmarks.
State Matching and Multiple References in Adaptive Active Automata Learning
Jun 28, 2024Active automata learning (AAL) is a method to infer state machines by interacting with black-box systems. Adaptive AAL aims to reduce the sample complexity of AAL by incorporating domain specific knowledge in the form of (similar) reference models. Such reference models appear naturally when learning multiple versions or variants of a software system. In this paper, we present state matching, which allows flexible use of the structure of these reference models by the learner. State matching is the main ingredient of adaptive L#, a novel framework for adaptive learning, built on top of L#. Our empirical evaluation shows that adaptive L# improves the state of the art by up to two orders of magnitude.
Learning-Based Verification of Stochastic Dynamical Systems with Neural Network Policies
Jun 02, 2024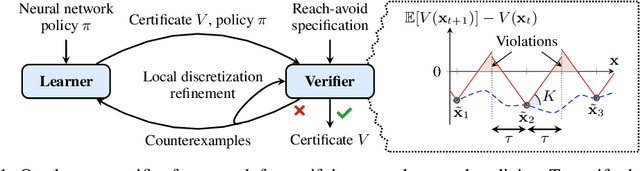

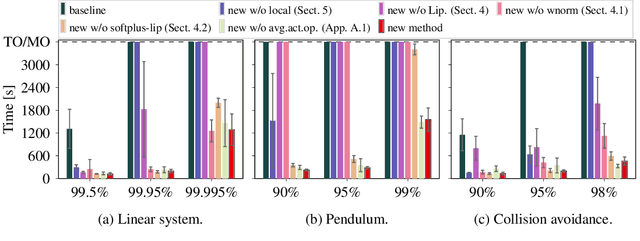

We consider the verification of neural network policies for reach-avoid control tasks in stochastic dynamical systems. We use a verification procedure that trains another neural network, which acts as a certificate proving that the policy satisfies the task. For reach-avoid tasks, it suffices to show that this certificate network is a reach-avoid supermartingale (RASM). As our main contribution, we significantly accelerate algorithmic approaches for verifying that a neural network is indeed a RASM. The main bottleneck of these approaches is the discretization of the state space of the dynamical system. The following two key contributions allow us to use a coarser discretization than existing approaches. First, we present a novel and fast method to compute tight upper bounds on Lipschitz constants of neural networks based on weighted norms. We further improve these bounds on Lipschitz constants based on the characteristics of the certificate network. Second, we integrate an efficient local refinement scheme that dynamically refines the state space discretization where necessary. Our empirical evaluation shows the effectiveness of our approach for verifying neural network policies in several benchmarks and trained with different reinforcement learning algorithms.
Approximate Dec-POMDP Solving Using Multi-Agent A*
May 09, 2024We present an A*-based algorithm to compute policies for finite-horizon Dec-POMDPs. Our goal is to sacrifice optimality in favor of scalability for larger horizons. The main ingredients of our approach are (1) using clustered sliding window memory, (2) pruning the A* search tree, and (3) using novel A* heuristics. Our experiments show competitive performance to the state-of-the-art. Moreover, for multiple benchmarks, we achieve superior performance. In addition, we provide an A* algorithm that finds upper bounds for the optimum, tailored towards problems with long horizons. The main ingredient is a new heuristic that periodically reveals the state, thereby limiting the number of reachable beliefs. Our experiments demonstrate the efficacy and scalability of the approach.
Imprecise Probabilities Meet Partial Observability: Game Semantics for Robust POMDPs
May 08, 2024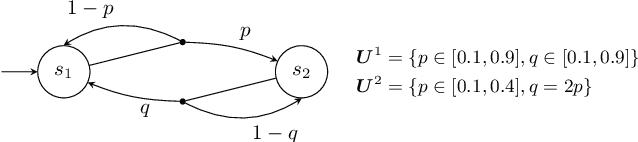
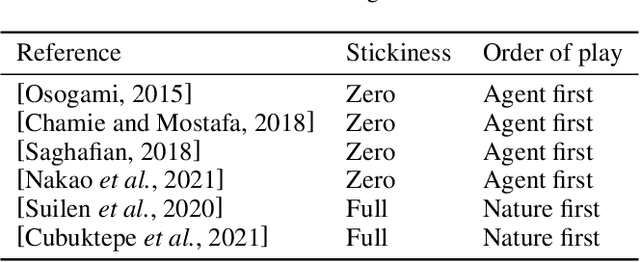
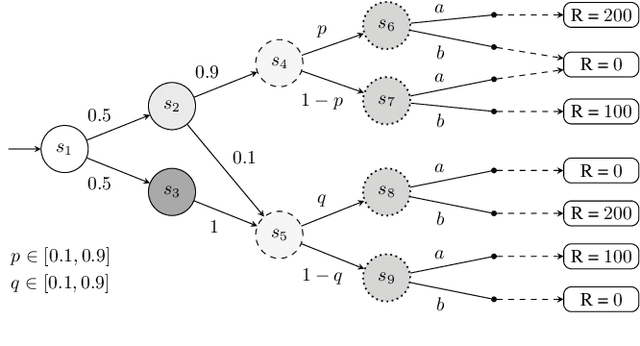
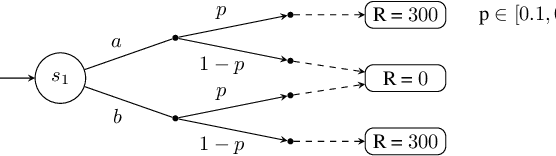
Partially observable Markov decision processes (POMDPs) rely on the key assumption that probability distributions are precisely known. Robust POMDPs (RPOMDPs) alleviate this concern by defining imprecise probabilities, referred to as uncertainty sets. While robust MDPs have been studied extensively, work on RPOMDPs is limited and primarily focuses on algorithmic solution methods. We expand the theoretical understanding of RPOMDPs by showing that 1) different assumptions on the uncertainty sets affect optimal policies and values; 2) RPOMDPs have a partially observable stochastic game (POSG) semantic; and 3) the same RPOMDP with different assumptions leads to semantically different POSGs and, thus, different policies and values. These novel semantics for RPOMDPS give access to results for the widely studied POSG model; concretely, we show the existence of a Nash equilibrium. Finally, we classify the existing RPOMDP literature using our semantics, clarifying under which uncertainty assumptions these existing works operate.
Factored Online Planning in Many-Agent POMDPs
Dec 22, 2023



In centralized multi-agent systems, often modeled as multi-agent partially observable Markov decision processes (MPOMDPs), the action and observation spaces grow exponentially with the number of agents, making the value and belief estimation of single-agent online planning ineffective. Prior work partially tackles value estimation by exploiting the inherent structure of multi-agent settings via so-called coordination graphs. Additionally, belief estimation has been improved by incorporating the likelihood of observations into the approximation. However, the challenges of value estimation and belief estimation have only been tackled individually, which prevents existing methods from scaling to many agents. Therefore, we address these challenges simultaneously. First, we introduce weighted particle filtering to a sample-based online planner for MPOMDPs. Second, we present a scalable approximation of the belief. Third, we bring an approach that exploits the typical locality of agent interactions to novel online planning algorithms for MPOMDPs operating on a so-called sparse particle filter tree. Our experimental evaluation against several state-of-the-art baselines shows that our methods (1) are competitive in settings with only a few agents and (2) improve over the baselines in the presence of many agents.